 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeling Comic Mischief Content in Online Videos with a Multimodal Hierarchical-Cross-Attention Model
Paper and Code



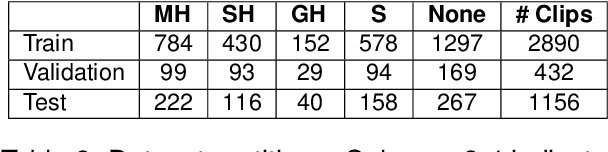
We address the challenge of detecting questionable content in online media, specifically the subcategory of comic mischief. This type of content combines elements such as violence, adult content, or sarcasm with humor, making it difficult to detect. Employing a multimodal approach is vital to capture the subtle details inherent in comic mischief content. To tackle this problem, we propose a novel end-to-end multimodal system for the task of comic mischief detection. As part of this contribution, we release a novel dataset for the targeted task consisting of three modalities: video, text (video captions and subtitles), and audio. We also design a HIerarchical Cross-attention model with CAPtions (HICCAP) to capture the intricate relationships among these modalities. The results show that the proposed approach makes a significant improvement over robust baselines and state-of-the-art models for comic mischief detection and its type classification. This emphasizes the potential of our system to empower users, to make informed decisions about the online content they choose to see. In addition, we conduct experiments on the UCF101, HMDB51, and XD-Violence datasets, comparing our model against other state-of-the-art approaches showcasing the outstanding performance of our proposed model in various scenarios.