 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBirds of a Feather Flock Together: Satirical News Detection via Language Model Differentiation
Paper and Code
Jul 04, 2020
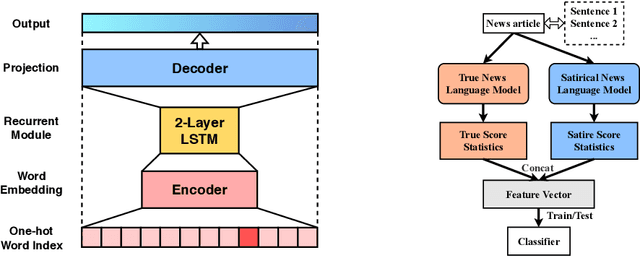
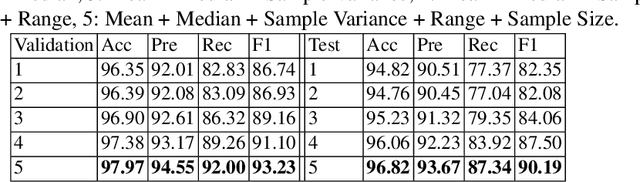
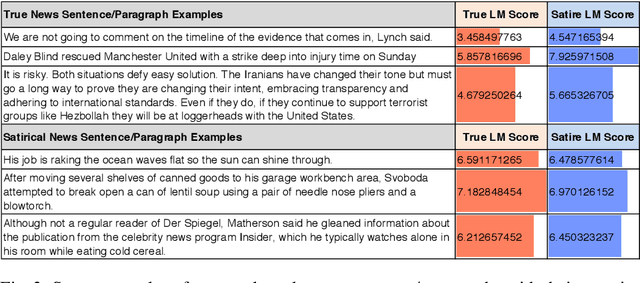
Satirical news is regularly shared in modern social media because it is entertaining with smartly embedded humor. However, it can be harmful to society because it can sometimes be mistaken as factual news, due to its deceptive character. We found that in satirical news, the lexical and pragmatical attributes of the context are the key factors in amusing the readers. In this work, we propose a method that differentiates the satirical news and true news. It takes advantage of satirical writing evidence by leveraging the difference between the prediction loss of two language models, one trained on true news and the other on satirical news, when given a new news article. We compute several statistical metrics of language model prediction loss as features, which are then used to conduct downstream classification. The proposed method is computationally effective because the language models capture the language usage differences between satirical news documents and traditional news documents, and are sensitive when applied to documents outside their domains.