 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Anomaly Detection Through Density Matrices
Aug 14, 2024This paper introduces a novel anomaly detection framework that combines the robust statistical principles of density-estimation-based anomaly detection methods with the representation-learning capabilities of deep learning models. The method originated from this framework is presented in two different versions: a shallow approach employing a density-estimation model based on adaptive Fourier features and density matrices, and a deep approach that integrates an autoencoder to learn a low-dimensional representation of the data. By estimating the density of new samples, both methods are able to find normality scores. The methods can be seamlessly integrated into an end-to-end architecture and optimized using gradient-based optimization techniques. To evaluate their performance, extensive experiments were conducted on various benchmark datasets. The results demonstrate that both versions of the method can achieve comparable or superior performance when compared to other state-of-the-art methods. Notably, the shallow approach performs better on datasets with fewer dimensions, while the autoencoder-based approach shows improved performance on datasets with higher dimensions.
MEMO-QCD: Quantum Density Estimation through Memetic Optimisation for Quantum Circuit Design
Jun 14, 2024

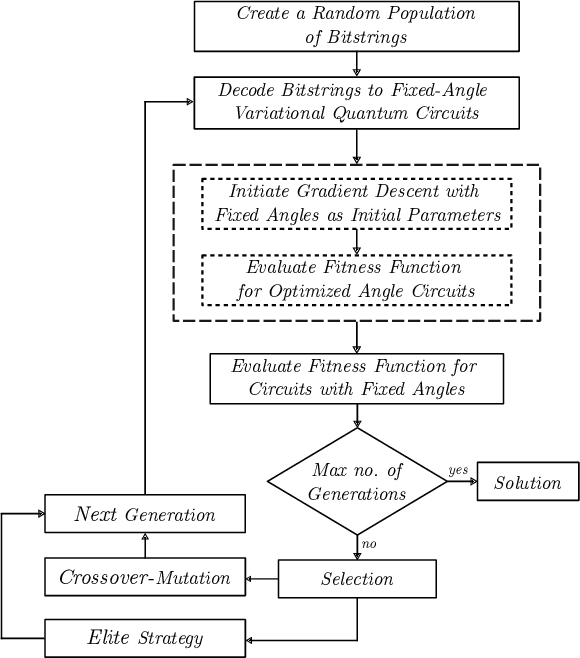

This paper presents a strategy for efficient quantum circuit design for density estimation. The strategy is based on a quantum-inspired algorithm for density estimation and a circuit optimisation routine based on memetic algorithms. The model maps a training dataset to a quantum state represented by a density matrix through a quantum feature map. This training state encodes the probability distribution of the dataset in a quantum state, such that the density of a new sample can be estimated by projecting its corresponding quantum state onto the training state. We propose the application of a memetic algorithm to find the architecture and parameters of a variational quantum circuit that implements the quantum feature map, along with a variational learning strategy to prepare the training state. Demonstrations of the proposed strategy show an accurate approximation of the Gaussian kernel density estimation method through shallow quantum circuits illustrating the feasibility of the algorithm for near-term quantum hardware.
Interpreting Themes from Educational Stories
Apr 08, 2024Reading comprehension continues to be a crucial research focus in the NLP community. Recent advances in Machine Reading Comprehension (MRC) have mostly centered on literal comprehension, referring to the surface-level understanding of content. In this work, we focus on the next level - interpretive comprehension, with a particular emphasis on inferring the themes of a narrative text. We introduce the first dataset specifically designed for interpretive comprehension of educational narratives, providing corresponding well-edited theme texts. The dataset spans a variety of genres and cultural origins and includes human-annotated theme keywords with varying levels of granularity. We further formulate NLP tasks under different abstractions of interpretive comprehension toward the main idea of a story. After conducting extensive experiments with state-of-the-art methods, we found the task to be both challenging and significant for NLP research. The dataset and source code have been made publicly available to the research community at https://github.com/RiTUAL-UH/EduStory.
Lightweight learning from label proportions on satellite imagery
Jun 21, 2023



This work addresses the challenge of producing chip level predictions on satellite imagery when only label proportions at a coarser spatial geometry are available, typically from statistical or aggregated data from administrative divisions (such as municipalities or communes). This kind of tabular data is usually widely available in many regions of the world and application areas and, thus, its exploitation may contribute to leverage the endemic scarcity of fine grained labelled data in Earth Observation (EO). This can be framed as a Learning from Label Proportions (LLP) problem setup. LLP applied to EO data is still an emerging field and performing comparative studies in applied scenarios remains a challenge due to the lack of standardized datasets. In this work, first, we show how simple deep learning and probabilistic methods generally perform better than standard more complex ones, providing a surprising level of finer grained spatial detail when trained with much coarser label proportions. Second, we provide a set of benchmarking datasets enabling comparative LLP applied to EO, providing both fine grained labels and aggregated data according to existing administrative divisions. Finally, we argue how this approach might be valuable when considering on-orbit inference and training. Source code is available at https://github.com/rramosp/llpeo
Quantum Kernel Mixtures for Probabilistic Deep Learning
May 26, 2023



This paper presents a novel approach to probabilistic deep learning (PDL), quantum kernel mixtures, derived from the mathematical formalism of quantum density matrices, which provides a simpler yet effective mechanism for representing joint probability distributions of both continuous and discrete random variables. The framework allows for the construction of differentiable models for density estimation, inference, and sampling, enabling integration into end-to-end deep neural models. In doing so, we provide a versatile representation of marginal and joint probability distributions that allows us to develop a differentiable, compositional, and reversible inference procedure that covers a wide range of machine learning tasks, including density estimation, discriminative learning, and generative modeling. We illustrate the broad applicability of the framework with two examples: an image classification model, which can be naturally transformed into a conditional generative model thanks to the reversibility of our inference procedure; and a model for learning with label proportions, which is a weakly supervised classification task, demonstrating the framework's ability to deal with uncertainty in the training samples.
What are the Machine Learning best practices reported by practitioners on Stack Exchange?
Jan 25, 2023



Machine Learning (ML) is being used in multiple disciplines due to its powerful capability to infer relationships within data. In particular, Software Engineering (SE) is one of those disciplines in which ML has been used for multiple tasks, like software categorization, bugs prediction, and testing. In addition to the multiple ML applications, some studies have been conducted to detect and understand possible pitfalls and issues when using ML. However, to the best of our knowledge, only a few studies have focused on presenting ML best practices or guidelines for the application of ML in different domains. In addition, the practices and literature presented in previous literature (i) are domain-specific (e.g., concrete practices in biomechanics), (ii) describe few practices, or (iii) the practices lack rigorous validation and are presented in gray literature. In this paper, we present a study listing 127 ML best practices systematically mining 242 posts of 14 different Stack Exchange (STE) websites and validated by four independent ML experts. The list of practices is presented in a set of categories related to different stages of the implementation process of an ML-enabled system; for each practice, we include explanations and examples. In all the practices, the provided examples focus on SE tasks. We expect this list of practices could help practitioners to understand better the practices and use ML in a more informed way, in particular newcomers to this new area that sits at the intersection of software engineering and machine learning.
LEAN-DMKDE: Quantum Latent Density Estimation for Anomaly Detection
Nov 15, 2022



This paper presents an anomaly detection model that combines the strong statistical foundation of density-estimation-based anomaly detection methods with the representation-learning ability of deep-learning models. The method combines an autoencoder, for learning a low-dimensional representation of the data, with a density-estimation model based on random Fourier features and density matrices in an end-to-end architecture that can be trained using gradient-based optimization techniques. The method predicts a degree of normality for new samples based on the estimated density. A systematic experimental evaluation was performed on different benchmark datasets. The experimental results show that the method performs on par with or outperforms other state-of-the-art methods.
AD-DMKDE: Anomaly Detection through Density Matrices and Fourier Features
Oct 26, 2022


This paper presents a novel density estimation method for anomaly detection using density matrices (a powerful mathematical formalism from quantum mechanics) and Fourier features. The method can be seen as an efficient approximation of Kernel Density Estimation (KDE). A systematic comparison of the proposed method with eleven state-of-the-art anomaly detection methods on various data sets is presented, showing competitive performance on different benchmark data sets. The method is trained efficiently and it uses optimization to find the parameters of data embedding. The prediction phase complexity of the proposed algorithm is constant relative to the training data size, and it performs well in data sets with different anomaly rates. Its architecture allows vectorization and can be implemented on GPU/TPU hardware.
Quantum Adaptive Fourier Features for Neural Density Estimation
Aug 04, 2022
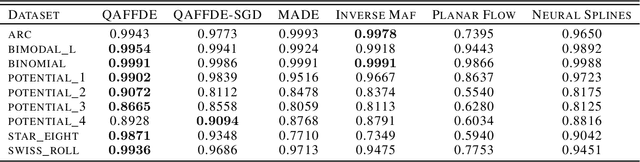
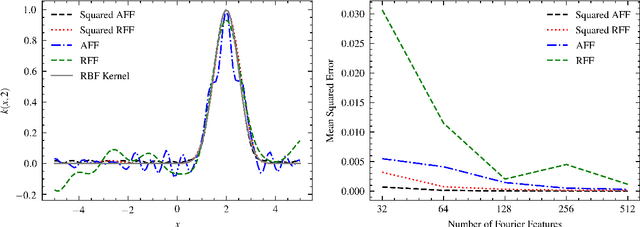

Density estimation is a fundamental task in statistics and machine learning applications. Kernel density estimation is a powerful tool for non-parametric density estimation in low dimensions; however, its performance is poor in higher dimensions. Moreover, its prediction complexity scale linearly with more training data points. This paper presents a method for neural density estimation that can be seen as a type of kernel density estimation, but without the high prediction computational complexity. The method is based on density matrices, a formalism used in quantum mechanics, and adaptive Fourier features. The method can be trained without optimization, but it could be also integrated with deep learning architectures and trained using gradient descent. Thus, it could be seen as a form of neural density estimation method. The method was evaluated in different synthetic and real datasets, and its performance compared against state-of-the-art neural density estimation methods, obtaining competitive results.
Fast Kernel Density Estimation with Density Matrices and Random Fourier Features
Aug 04, 2022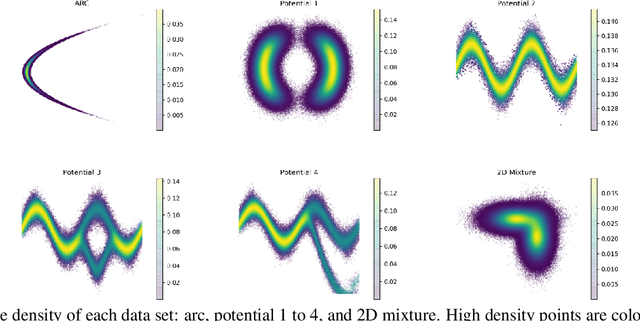
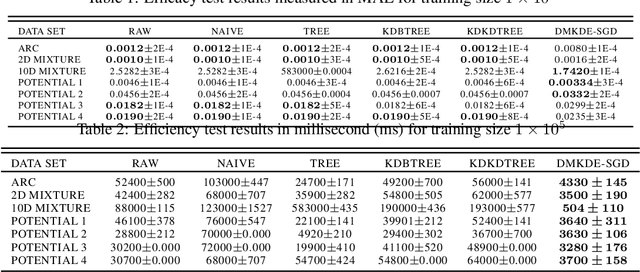

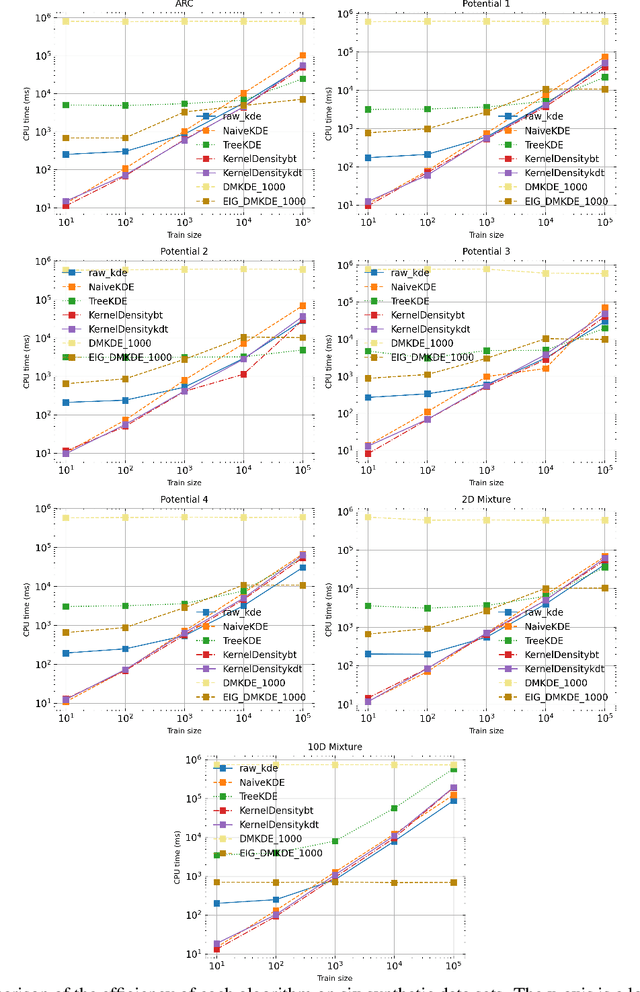
Kernel density estimation (KDE) is one of the most widely used nonparametric density estimation methods. The fact that it is a memory-based method, i.e., it uses the entire training data set for prediction, makes it unsuitable for most current big data applications. Several strategies, such as tree-based or hashing-based estimators, have been proposed to improve the efficiency of the kernel density estimation method. The novel density kernel density estimation method (DMKDE) uses density matrices, a quantum mechanical formalism, and random Fourier features, an explicit kernel approximation, to produce density estimates. This method has its roots in the KDE and can be considered as an approximation method, without its memory-based restriction. In this paper, we systematically evaluate the novel DMKDE algorithm and compare it with other state-of-the-art fast procedures for approximating the kernel density estimation method on different synthetic data sets. Our experimental results show that DMKDE is on par with its competitors for computing density estimates and advantages are shown when performed on high-dimensional data. We have made all the code available as an open source software repository.