 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Design beyond Training Data with Novel Extended Objective Functionals of Generative AI Models Driven by Quantum Annealing Computer
Feb 17, 2026Deep generative modeling to stochastically design small molecules is an emerging technology for accelerating drug discovery and development. However, one major issue in molecular generative models is their lower frequency of drug-like compounds. To resolve this problem, we developed a novel framework for optimization of deep generative models integrated with a D-Wave quantum annealing computer, where our Neural Hash Function (NHF) presented herein is used both as the regularization and binarization schemes simultaneously, of which the latter is for transformation between continuous and discrete signals of the classical and quantum neural networks, respectively, in the error evaluation (i.e., objective) function. The compounds generated via the quantum-annealing generative models exhibited higher quality in both validity and drug-likeness than those generated via the fully-classical models, and was further indicated to exceed even the training data in terms of drug-likeness features, without any restraints and conditions to deliberately induce such an optimization. These results indicated an advantage of quantum annealing to aim at a stochastic generator integrated with our novel neural network architectures, for the extended performance of feature space sampling and extraction of characteristic features in drug design.
Quantum Deep Sets and Sequences
Apr 03, 2025This paper introduces the quantum deep sets model, expanding the quantum machine learning tool-box by enabling the possibility of learning variadic functions using quantum systems. A couple of variants are presented for this model. The first one focuses on mapping sets to quantum systems through state vector averaging: each element of the set is mapped to a quantum state, and the quantum state of the set is the average of the corresponding quantum states of its elements. This approach allows the definition of a permutation-invariant variadic model. The second variant is useful for ordered sets, i.e., sequences, and relies on optimal coherification of tristochastic tensors that implement products of mixed states: each element of the set is mapped to a density matrix, and the quantum state of the set is the product of the corresponding density matrices of its elements. Such variant can be relevant in tasks such as natural language processing. The resulting quantum state in any of the variants is then processed to realise a function that solves a machine learning task such as classification, regression or density estimation. Through synthetic problem examples, the efficacy and versatility of quantum deep sets and sequences (QDSs) is demonstrated.
Variational decision diagrams for quantum-inspired machine learning applications
Feb 06, 2025


Decision diagrams (DDs) have emerged as an efficient tool for simulating quantum circuits due to their capacity to exploit data redundancies in quantum states and quantum operations, enabling the efficient computation of probability amplitudes. However, their application in quantum machine learning (QML) has remained unexplored. This paper introduces variational decision diagrams (VDDs), a novel graph structure that combines the structural benefits of DDs with the adaptability of variational methods for efficiently representing quantum states. We investigate the trainability of VDDs by applying them to the ground state estimation problem for transverse-field Ising and Heisenberg Hamiltonians. Analysis of gradient variance suggests that training VDDs is possible, as no signs of vanishing gradients--also known as barren plateaus--are observed. This work provides new insights into the use of decision diagrams in QML as an alternative to design and train variational ans\"atze.
MEMO-QCD: Quantum Density Estimation through Memetic Optimisation for Quantum Circuit Design
Jun 14, 2024


This paper presents a strategy for efficient quantum circuit design for density estimation. The strategy is based on a quantum-inspired algorithm for density estimation and a circuit optimisation routine based on memetic algorithms. The model maps a training dataset to a quantum state represented by a density matrix through a quantum feature map. This training state encodes the probability distribution of the dataset in a quantum state, such that the density of a new sample can be estimated by projecting its corresponding quantum state onto the training state. We propose the application of a memetic algorithm to find the architecture and parameters of a variational quantum circuit that implements the quantum feature map, along with a variational learning strategy to prepare the training state. Demonstrations of the proposed strategy show an accurate approximation of the Gaussian kernel density estimation method through shallow quantum circuits illustrating the feasibility of the algorithm for near-term quantum hardware.
Road Network Deterioration Monitoring Using Aerial Images and Computer Vision
Sep 30, 2022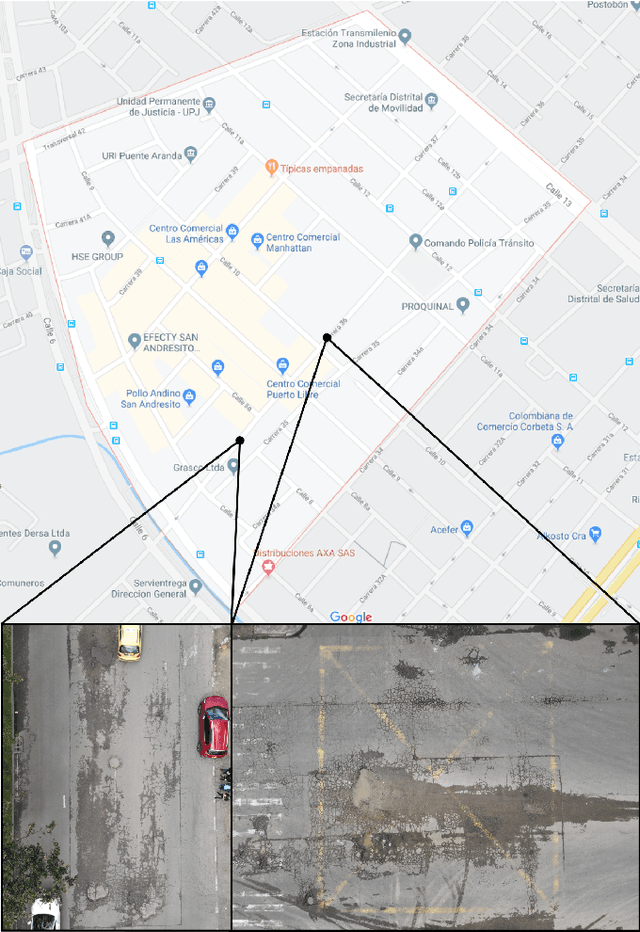



Road maintenance is an essential process for guaranteeing the quality of transportation in any city. A crucial step towards effective road maintenance is the ability to update the inventory of the road network. We present a proof of concept of a protocol for maintaining said inventory based on the use of unmanned aerial vehicles to quickly collect images which are processed by a computer vision program that automatically identifies potholes and their severity. Our protocol aims to provide information to local governments to prioritise the road network maintenance budget, and to be able to detect early stages of road deterioration so as to minimise maintenance expenditure.
An Empirical Study of Quantum Dynamics as a Ground State Problem with Neural Quantum States
Jun 18, 2022
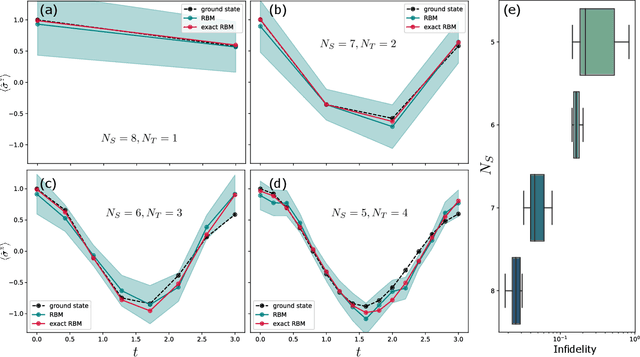
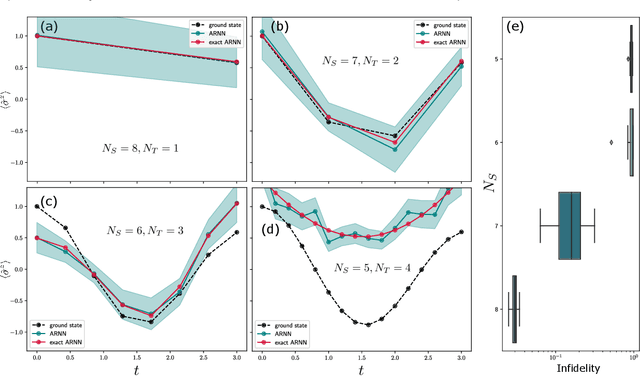
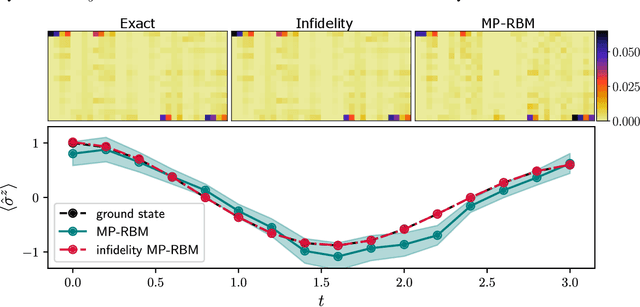
Neural quantum states are variational wave functions parameterised by artificial neural networks, a mathematical model studied for decades in the machine learning community. In the context of many-body physics, methods such as variational Monte Carlo with neural quantum states as variational wave functions are successful in approximating, with great accuracy, the ground-state of a quantum Hamiltonian. However, all the difficulties of proposing neural network architectures, along with exploring their expressivity and trainability, permeate their application as neural quantum states. In this paper, we consider the Feynman-Kitaev Hamiltonian for the transverse field Ising model, whose ground state encodes the time evolution of a spin chain at discrete time steps. We show how this ground state problem specifically challenges the neural quantum state trainability as the time steps increase because the true ground state becomes more entangled, and the probability distribution starts to spread across the Hilbert space. Our results indicate that the considered neural quantum states are capable of accurately approximating the true ground state of the system, i.e., they are expressive enough. However, extensive hyper-parameter tuning experiments point towards the empirical fact that it is poor trainability--in the variational Monte Carlo setup--that prevents a faithful approximation of the true ground state.
Optimisation-free Classification and Density Estimation with Quantum Circuits
Mar 31, 2022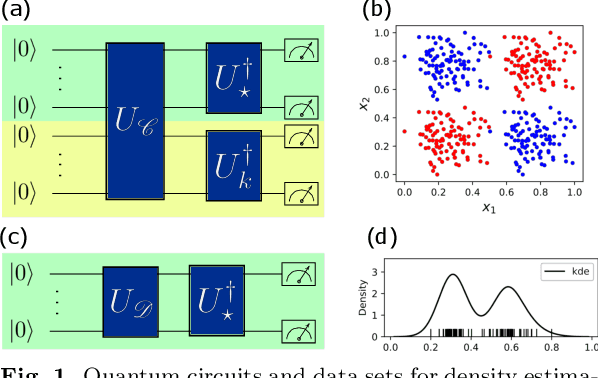
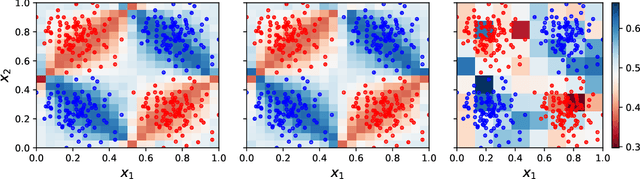
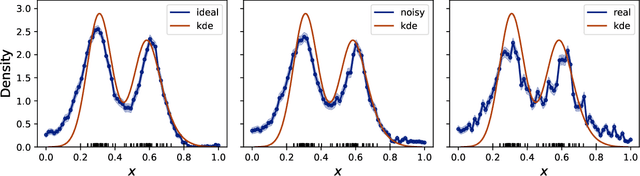
We demonstrate the implementation of a novel machine learning framework for probability density estimation and classification using quantum circuits. The framework maps a training data set or a single data sample to the quantum state of a physical system through quantum feature maps. The quantum state of the arbitrarily large training data set summarises its probability distribution in a finite-dimensional quantum wave function. By projecting the quantum state of a new data sample onto the quantum state of the training data set, one can derive statistics to classify or estimate the density of the new data sample. Remarkably, the implementation of our framework on a real quantum device does not require any optimisation of quantum circuit parameters. Nonetheless, we discuss a variational quantum circuit approach that could leverage quantum advantage for our framework.
Machine learning for assessing quality of service in the hospitality sector based on customer reviews
Jul 21, 2021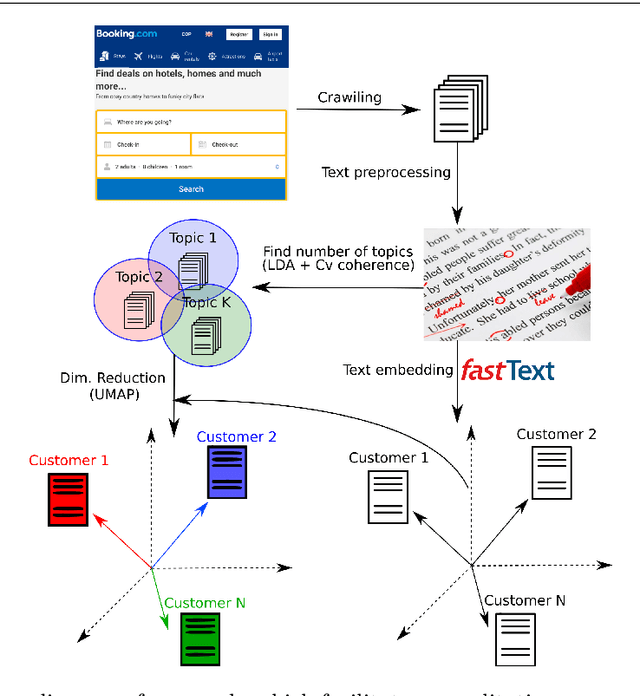
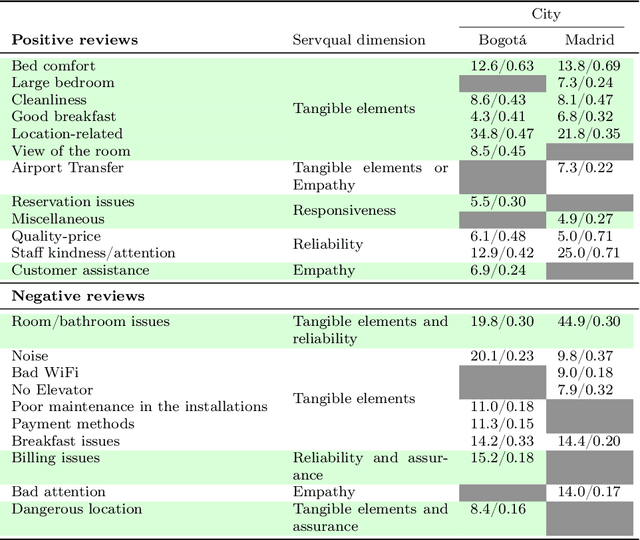
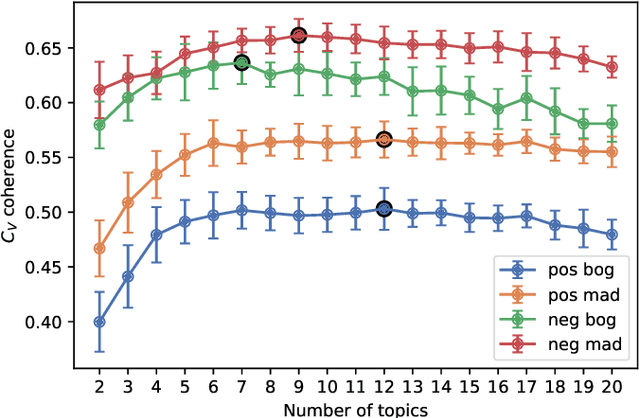
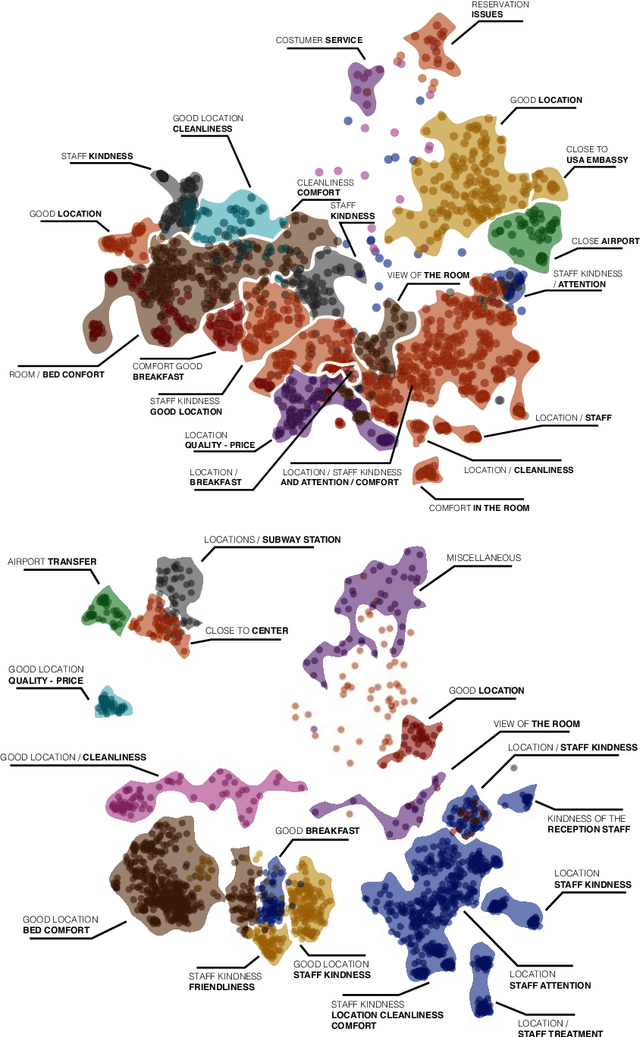
The increasing use of online hospitality platforms provides firsthand information about clients preferences, which are essential to improve hotel services and increase the quality of service perception. Customer reviews can be used to automatically extract the most relevant aspects of the quality of service for hospitality clientele. This paper proposes a framework for the assessment of the quality of service in the hospitality sector based on the exploitation of customer reviews through natural language processing and machine learning methods. The proposed framework automatically discovers the quality of service aspects relevant to hotel customers. Hotel reviews from Bogot\'a and Madrid are automatically scrapped from Booking.com. Semantic information is inferred through Latent Dirichlet Allocation and FastText, which allow representing text reviews as vectors. A dimensionality reduction technique is applied to visualise and interpret large amounts of customer reviews. Visualisations of the most important quality of service aspects are generated, allowing to qualitatively and quantitatively assess the quality of service. Results show that it is possible to automatically extract the main quality of service aspects perceived by customers from large customer review datasets. These findings could be used by hospitality managers to understand clients better and to improve the quality of service.
Learning with Density Matrices and Random Features
Feb 12, 2021


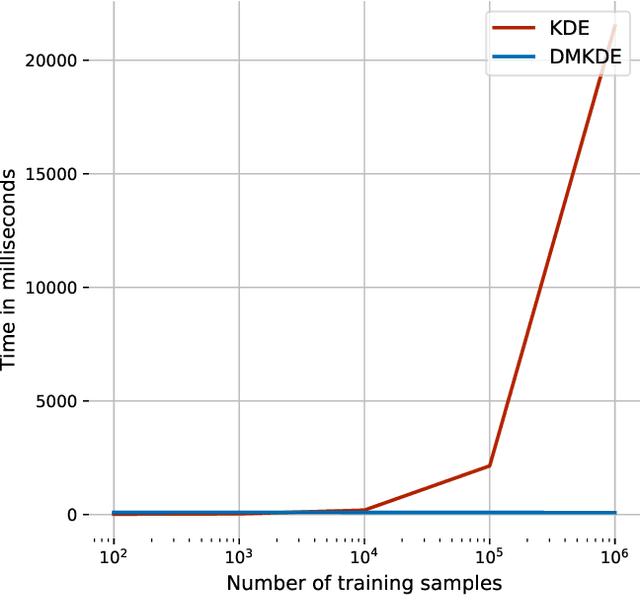
A density matrix describes the statistical state of a quantum system. It is a powerful formalism to represent both the quantum and classical uncertainty of quantum systems and to express different statistical operations such as measurement, system combination and expectations as linear algebra operations. This paper explores how density matrices can be used as a building block to build machine learning models exploiting their ability to straightforwardly combine linear algebra and probability. One of the main results of the paper is to show that density matrices coupled with random Fourier features could approximate arbitrary probability distributions over $\mathbb{R}^n$. Based on this finding the paper builds different models for density estimation, classification and regression. These models are differentiable, so it is possible to integrate them with other differentiable components, such as deep learning architectures and to learn their parameters using gradient-based optimization. In addition, the paper presents optimization-less training strategies based on estimation and model averaging. The models are evaluated in benchmark tasks and the results are reported and discussed.
Towards robust and speculation-reduction real estate pricing models based on a data-driven strategy
Nov 26, 2020
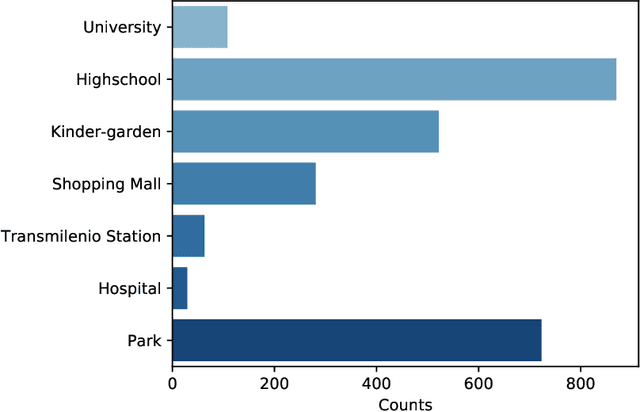
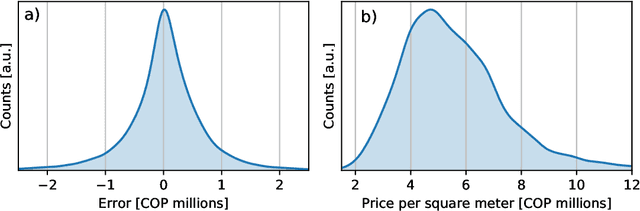
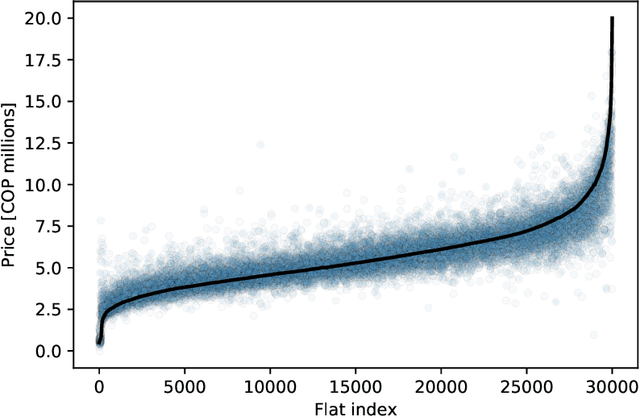
In many countries, real estate appraisal is based on conventional methods that rely on appraisers' abilities to collect data, interpret it and model the price of a real estate property. With the increasing use of real estate online platforms and the large amount of information found therein, there exists the possibility of overcoming many drawbacks of conventional pricing models such as subjectivity, cost, unfairness, among others. In this paper we propose a data-driven real estate pricing model based on machine learning methods to estimate prices reducing human bias. We test the model with 178,865 flats listings from Bogot\'a, collected from 2016 to 2020. Results show that the proposed state-of-the-art model is robust and accurate in estimating real estate prices. This case study serves as an incentive for local governments from developing countries to discuss and build real estate pricing models based on large data sets that increases fairness for all the real estate market stakeholders and reduces price speculation.