 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning for assessing quality of service in the hospitality sector based on customer reviews
Jul 21, 2021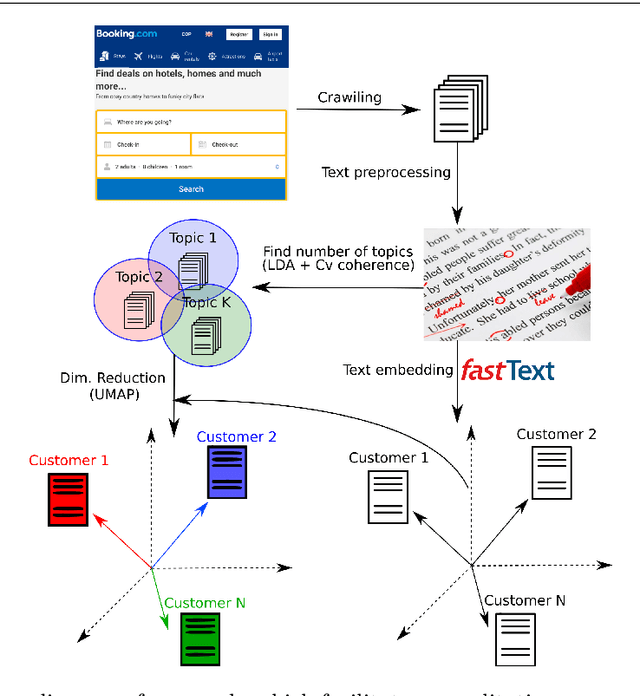
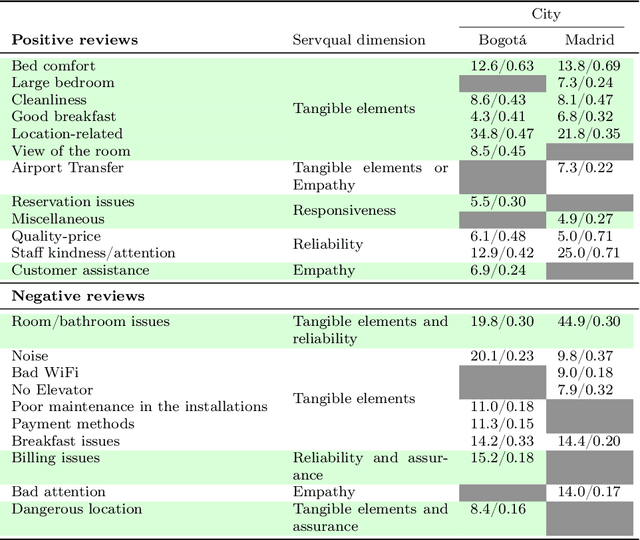
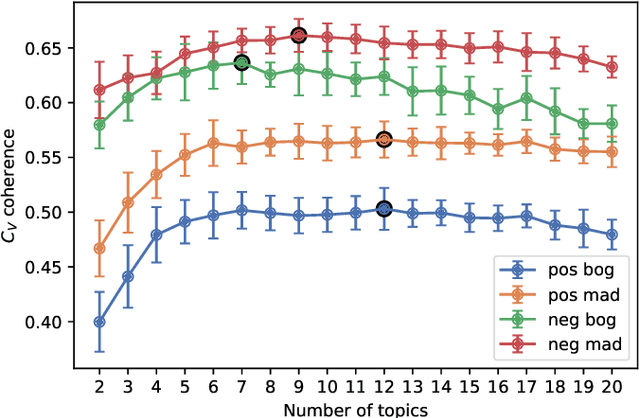
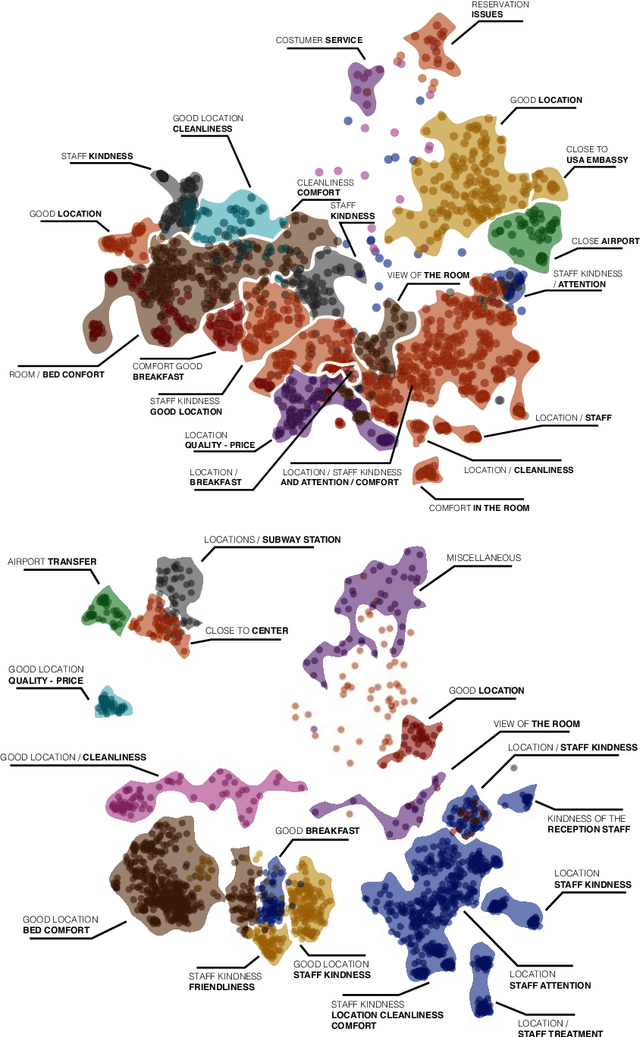
The increasing use of online hospitality platforms provides firsthand information about clients preferences, which are essential to improve hotel services and increase the quality of service perception. Customer reviews can be used to automatically extract the most relevant aspects of the quality of service for hospitality clientele. This paper proposes a framework for the assessment of the quality of service in the hospitality sector based on the exploitation of customer reviews through natural language processing and machine learning methods. The proposed framework automatically discovers the quality of service aspects relevant to hotel customers. Hotel reviews from Bogot\'a and Madrid are automatically scrapped from Booking.com. Semantic information is inferred through Latent Dirichlet Allocation and FastText, which allow representing text reviews as vectors. A dimensionality reduction technique is applied to visualise and interpret large amounts of customer reviews. Visualisations of the most important quality of service aspects are generated, allowing to qualitatively and quantitatively assess the quality of service. Results show that it is possible to automatically extract the main quality of service aspects perceived by customers from large customer review datasets. These findings could be used by hospitality managers to understand clients better and to improve the quality of service.
Towards robust and speculation-reduction real estate pricing models based on a data-driven strategy
Nov 26, 2020
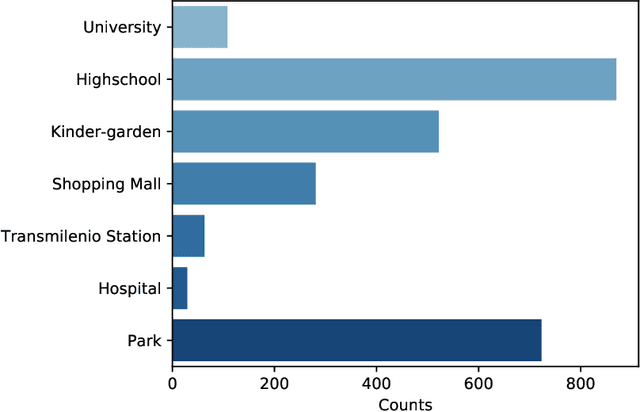
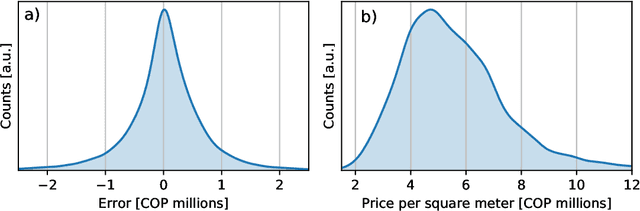
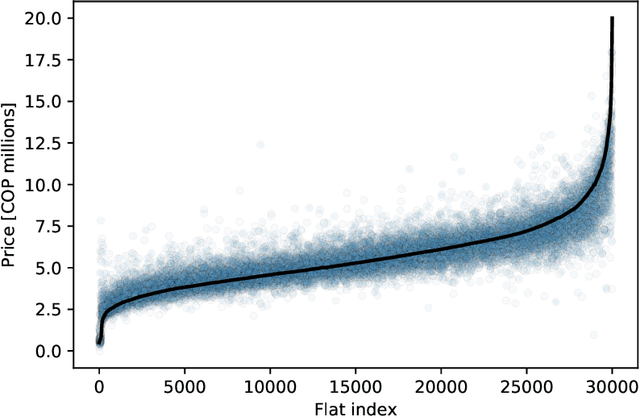
In many countries, real estate appraisal is based on conventional methods that rely on appraisers' abilities to collect data, interpret it and model the price of a real estate property. With the increasing use of real estate online platforms and the large amount of information found therein, there exists the possibility of overcoming many drawbacks of conventional pricing models such as subjectivity, cost, unfairness, among others. In this paper we propose a data-driven real estate pricing model based on machine learning methods to estimate prices reducing human bias. We test the model with 178,865 flats listings from Bogot\'a, collected from 2016 to 2020. Results show that the proposed state-of-the-art model is robust and accurate in estimating real estate prices. This case study serves as an incentive for local governments from developing countries to discuss and build real estate pricing models based on large data sets that increases fairness for all the real estate market stakeholders and reduces price speculation.
Learning from students' perception on professors through opinion mining
Aug 25, 2020


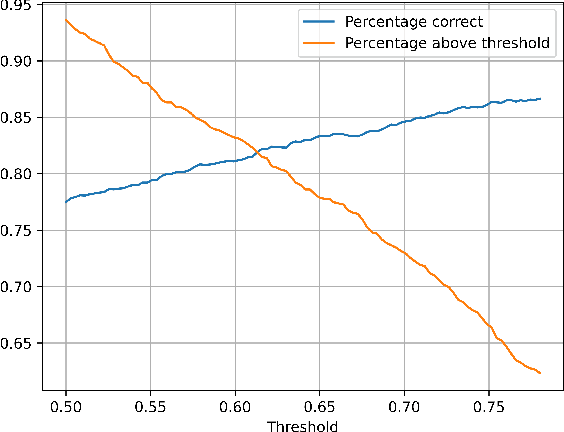
Students' perception of classes measured through their opinions on teaching surveys allows to identify deficiencies and problems, both in the environment and in the learning methodologies. The purpose of this paper is to study, through sentiment analysis using natural language processing (NLP) and machine learning (ML) techniques, those opinions in order to identify topics that are relevant for students, as well as predicting the associated sentiment via polarity analysis. As a result, it is implemented, trained and tested two algorithms to predict the associated sentiment as well as the relevant topics of such opinions. The combination of both approaches then becomes useful to identify specific properties of the students' opinions associated with each sentiment label (positive, negative or neutral opinions) and topic. Furthermore, we explore the possibility that students' perception surveys are carried out without closed questions, relying on the information that students can provide through open questions where they express their opinions about their classes.
A model for predicting price polarity of real estate properties using information of real estate market websites
Nov 19, 2019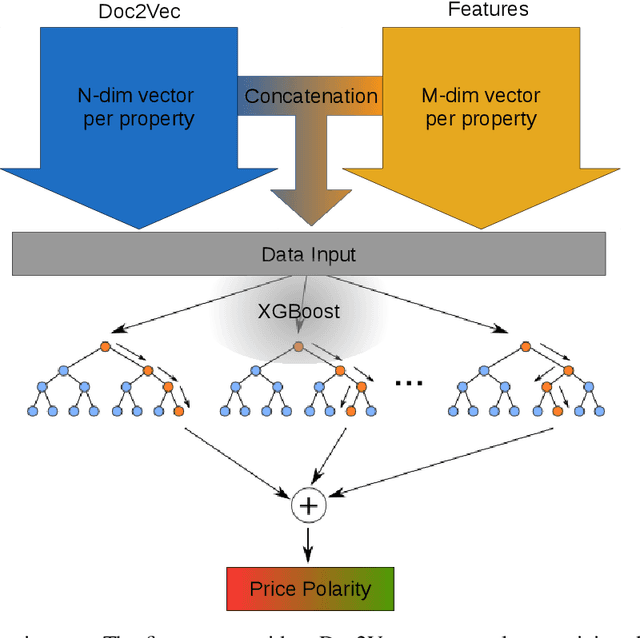


This paper presents a model that uses the information that sellers publish in real estate market websites to predict whether a property has higher or lower price than the average price of its similar properties. The model learns the correlation between price and information (text descriptions and features) of real estate properties through automatic identification of latent semantic content given by a machine learning model based on doc2vec and xgboost. The proposed model was evaluated with a data set of 57,516 publications of real estate properties collected from 2016 to 2018 of Bogot\'a city. Results show that the accuracy of a classifier that involves text descriptions is slightly higher than a classifier that only uses features of the real estate properties, as text descriptions tends to contain detailed information about the property.
Event detection in Colombian security Twitter news using fine-grained latent topic analysis
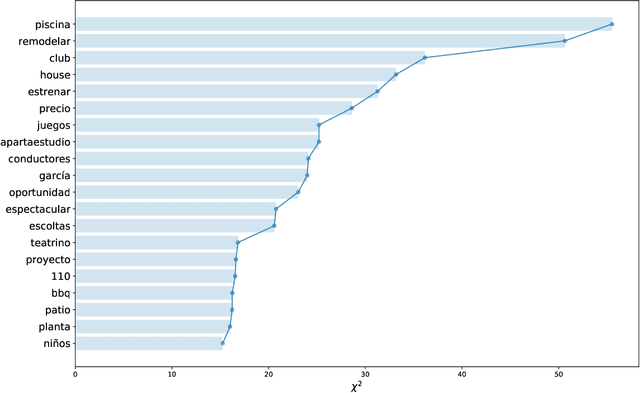
Nov 19, 2019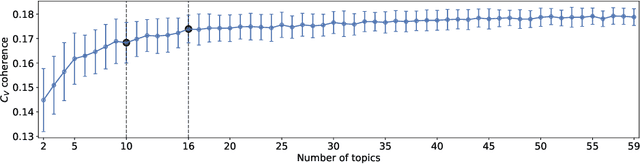

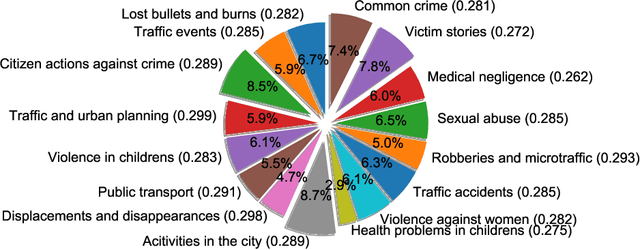
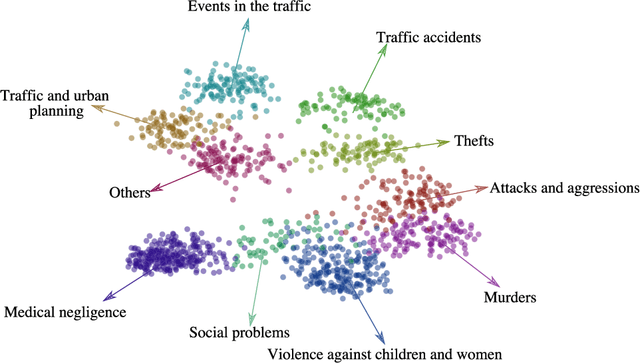
Cultural and social dynamics are important concepts that must be understood in order to grasp what a community cares about. To that end, an excellent source of information on what occurs in a community is the news, especially in recent years, when mass media giants use social networks to communicate and interact with their audience. In this work, we use a method to discover latent topics in tweets from Colombian Twitter news accounts in order to identify the most prominent events in the country. We pay particular attention to security, violence and crime-related tweets because of the violent environment that surrounds Colombian society. The latent topic discovery method that we use builds vector representations of the tweets by using FastText and finds clusters of tweets through the K-means clustering algorithm. The number of clusters is found by measuring the $C_V$ coherence for a range of number of topics of the Latent Dirichlet Allocation (LDA) model. We finally use Uniform Manifold Approximation and Projection (UMAP) for dimensionality reduction to visualise the tweets vectors. Once the clusters related to security, violence and crime are identified, we proceed to apply the same method within each cluster to perform a fine-grained analysis in which specific events mentioned in the news are grouped together. Our method is able to discover event-specific sets of news, which is the baseline to perform an extensive analysis of how people engage in Twitter threads on the different types of news, with an emphasis on security, violence and crime-related tweets.
Automatic Identification of Traditional Colombian Music Genres based on Audio Content Analysis and Machine Learning Technique
Nov 08, 2019


Colombia has a diversity of genres in traditional music, which allows to express the richness of the Colombian culture according to the region. This musical diversity is the result of a mixture of African, native Indigenous, and European influences. Organizing large collections of songs is a time consuming task that requires that a human listens to fragments of audio to identify genre, singer, year, instruments and other relevant characteristics that allow to index the song dataset. This paper presents a method to automatically identify the genre of a Colombian song by means of its audio content. The method extracts audio features that are used to train a machine learning model that learns to classify the genre. The method was evaluated in a dataset of 180 musical pieces belonging to six folkloric Colombian music genres: Bambuco, Carranga, Cumbia, Joropo, Pasillo, and Vallenato. Results show that it is possible to automatically identify the music genre in spite of the complexity of Colombian rhythms reaching an average accuracy of 69\%.
Predicting city safety perception based on visual image content
Feb 19, 2019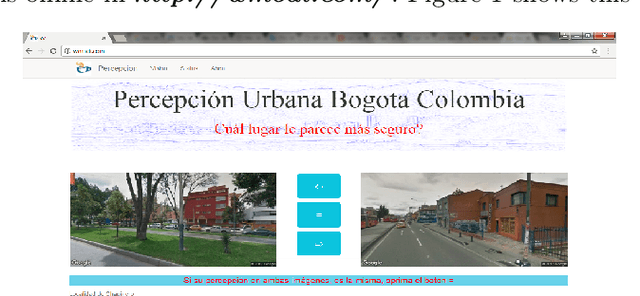
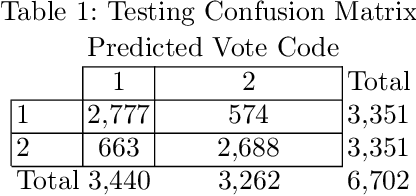


Safety perception measurement has been a subject of interest in many cities of the world. This is due to its social relevance, and to its effect on some local economic activities. Even though people safety perception is a subjective topic, sometimes it is possible to find out common patterns given a restricted geographical and sociocultural context. This paper presents an approach that makes use of image processing and machine learning techniques to detect with high accuracy urban environment patterns that could affect citizen's safety perception.