 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Anomaly Detection Through Density Matrices
Aug 14, 2024This paper introduces a novel anomaly detection framework that combines the robust statistical principles of density-estimation-based anomaly detection methods with the representation-learning capabilities of deep learning models. The method originated from this framework is presented in two different versions: a shallow approach employing a density-estimation model based on adaptive Fourier features and density matrices, and a deep approach that integrates an autoencoder to learn a low-dimensional representation of the data. By estimating the density of new samples, both methods are able to find normality scores. The methods can be seamlessly integrated into an end-to-end architecture and optimized using gradient-based optimization techniques. To evaluate their performance, extensive experiments were conducted on various benchmark datasets. The results demonstrate that both versions of the method can achieve comparable or superior performance when compared to other state-of-the-art methods. Notably, the shallow approach performs better on datasets with fewer dimensions, while the autoencoder-based approach shows improved performance on datasets with higher dimensions.
LEAN-DMKDE: Quantum Latent Density Estimation for Anomaly Detection
Nov 15, 2022



This paper presents an anomaly detection model that combines the strong statistical foundation of density-estimation-based anomaly detection methods with the representation-learning ability of deep-learning models. The method combines an autoencoder, for learning a low-dimensional representation of the data, with a density-estimation model based on random Fourier features and density matrices in an end-to-end architecture that can be trained using gradient-based optimization techniques. The method predicts a degree of normality for new samples based on the estimated density. A systematic experimental evaluation was performed on different benchmark datasets. The experimental results show that the method performs on par with or outperforms other state-of-the-art methods.
AD-DMKDE: Anomaly Detection through Density Matrices and Fourier Features
Oct 26, 2022


This paper presents a novel density estimation method for anomaly detection using density matrices (a powerful mathematical formalism from quantum mechanics) and Fourier features. The method can be seen as an efficient approximation of Kernel Density Estimation (KDE). A systematic comparison of the proposed method with eleven state-of-the-art anomaly detection methods on various data sets is presented, showing competitive performance on different benchmark data sets. The method is trained efficiently and it uses optimization to find the parameters of data embedding. The prediction phase complexity of the proposed algorithm is constant relative to the training data size, and it performs well in data sets with different anomaly rates. Its architecture allows vectorization and can be implemented on GPU/TPU hardware.
InQMAD: Incremental Quantum Measurement Anomaly Detection
Oct 11, 2022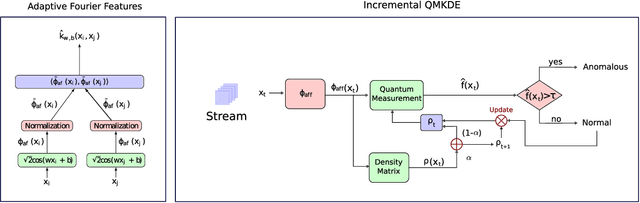
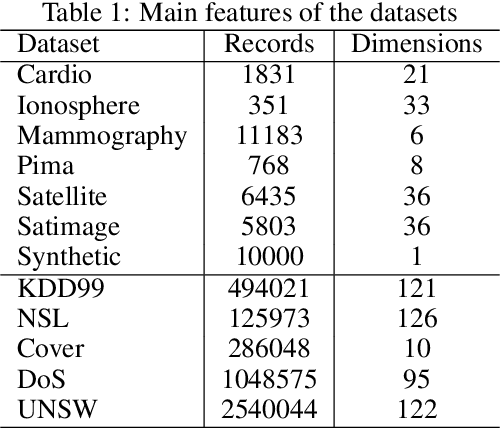
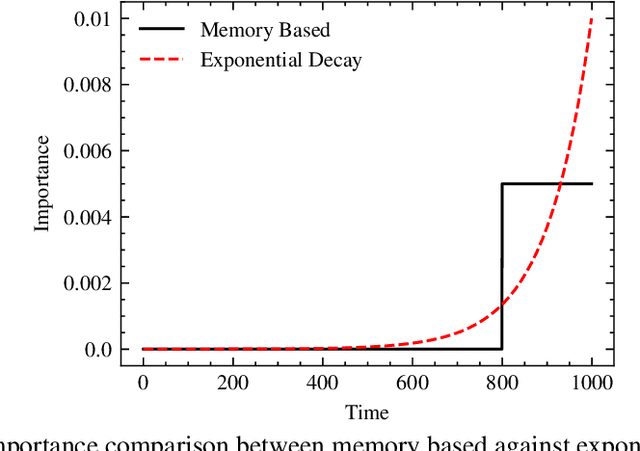
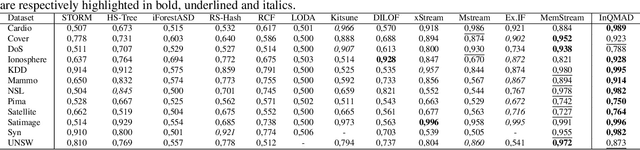
Streaming anomaly detection refers to the problem of detecting anomalous data samples in streams of data. This problem poses challenges that classical and deep anomaly detection methods are not designed to cope with, such as conceptual drift and continuous learning. State-of-the-art flow anomaly detection methods rely on fixed memory using hash functions or nearest neighbors that may not be able to constrain high-frequency values as in a moving average or remove seamless outliers and cannot be trained in an end-to-end deep learning architecture. We present a new incremental anomaly detection method that performs continuous density estimation based on random Fourier features and the mechanism of quantum measurements and density matrices that can be viewed as an exponential moving average density. It can process potentially endless data and its update complexity is constant $O(1)$. A systematic evaluation against 12 state-of-the-art streaming anomaly detection algorithms using 12 streaming datasets is presented.
Risk Automatic Prediction for Social Economy Companies using Camels
Oct 10, 2022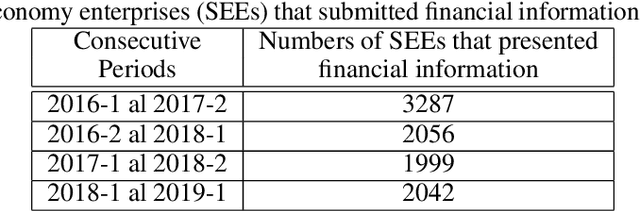
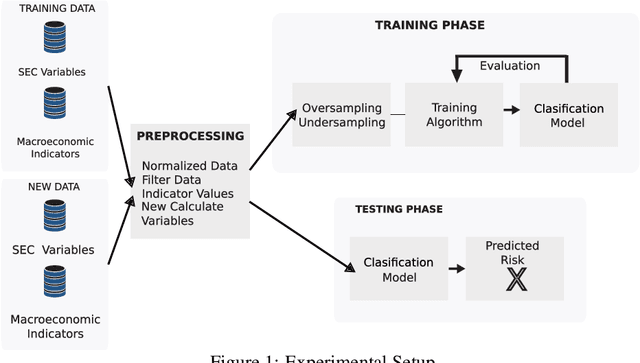
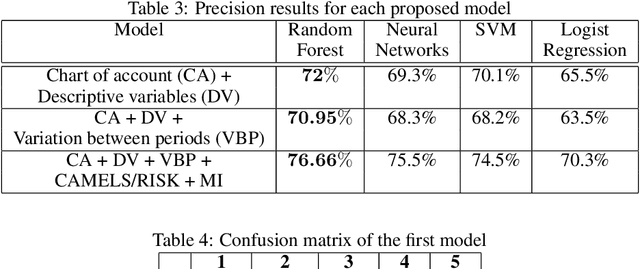
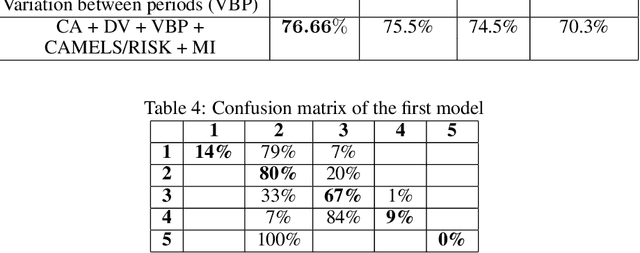
Governments have to supervise and inspect social economy enterprises (SEEs). However, inspecting all SEEs is not possible due to the large number of SEEs and the low number of inspectors in general. We proposed a prediction model based on a machine learning approach. The method was trained with the random forest algorithm with historical data provided by each SEE. Three consecutive periods of data were concatenated. The proposed method uses these periods as input data and predicts the risk of each SEE in the fourth period. The model achieved 76\% overall accuracy. In addition, it obtained good accuracy in predicting the high risk of a SEE. We found that the legal nature and the variation of the past-due portfolio are good predictors of the future risk of a SEE. Thus, the risk of a SEE in a future period can be predicted by a supervised machine learning method. Predicting the high risk of a SEE improves the daily work of each inspector by focusing only on high-risk SEEs.