 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid AHS: A Hybrid of Kalman Filter and Deep Learning for Acoustic Howling Suppression
May 04, 2023



Deep learning has been recently introduced for efficient acoustic howling suppression (AHS). However, the recurrent nature of howling creates a mismatch between offline training and streaming inference, limiting the quality of enhanced speech. To address this limitation, we propose a hybrid method that combines a Kalman filter with a self-attentive recurrent neural network (SARNN) to leverage their respective advantages for robust AHS. During offline training, a pre-processed signal obtained from the Kalman filter and an ideal microphone signal generated via teacher-forced training strategy are used to train the deep neural network (DNN). During streaming inference, the DNN's parameters are fixed while its output serves as a reference signal for updating the Kalman filter. Evaluation in both offline and streaming inference scenarios using simulated and real-recorded data shows that the proposed method efficiently suppresses howling and consistently outperforms baselines.
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 31, 2022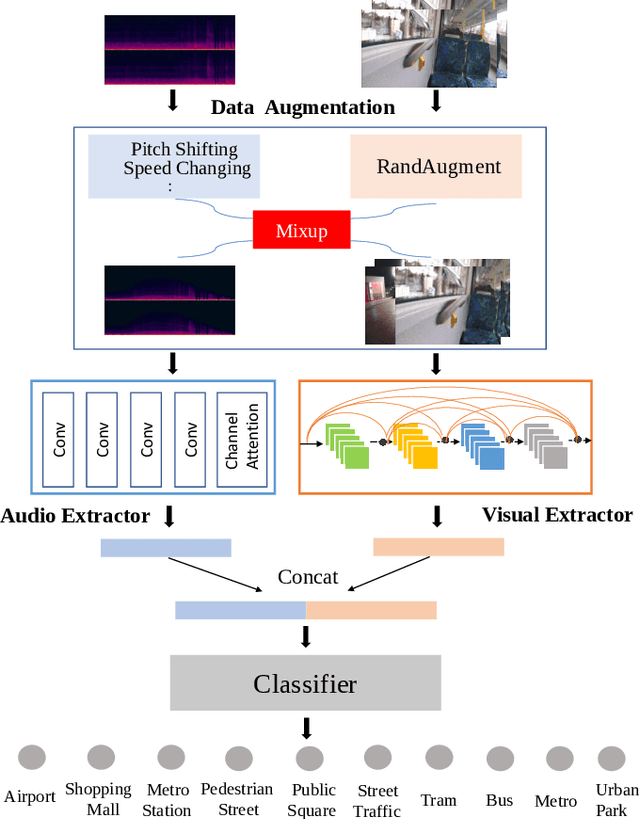
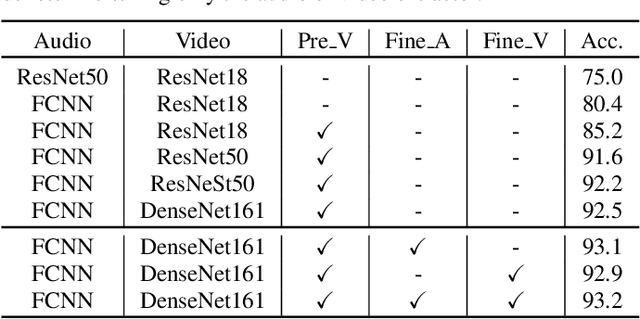
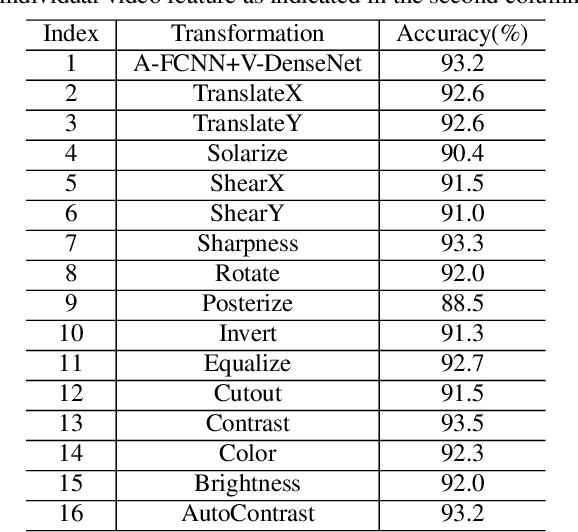
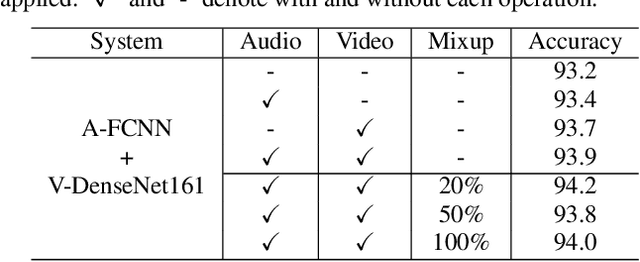
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.
Robust Feature Learning on Long-Duration Sounds for Acoustic Scene Classification
Aug 11, 2021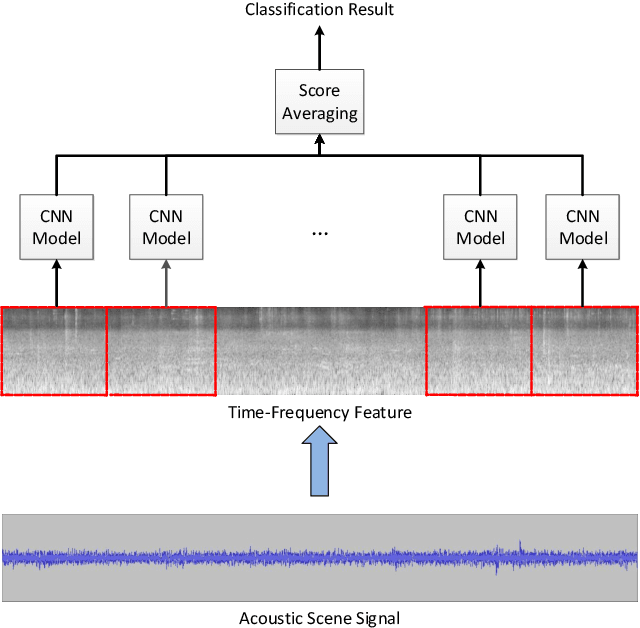
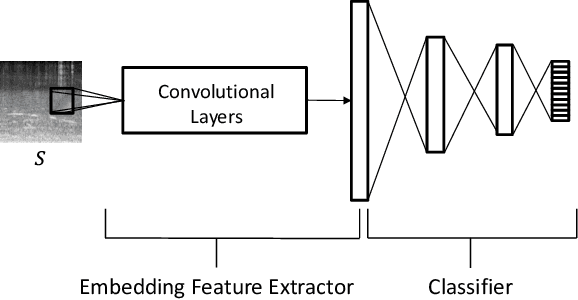
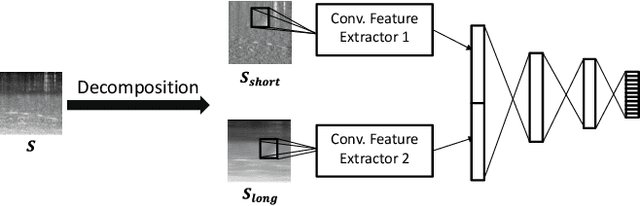
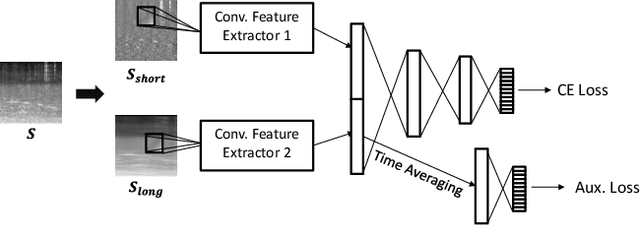
Acoustic scene classification (ASC) aims to identify the type of scene (environment) in which a given audio signal is recorded. The log-mel feature and convolutional neural network (CNN) have recently become the most popular time-frequency (TF) feature representation and classifier in ASC. An audio signal recorded in a scene may include various sounds overlapping in time and frequency. The previous study suggests that separately considering the long-duration sounds and short-duration sounds in CNN may improve ASC accuracy. This study addresses the problem of the generalization ability of acoustic scene classifiers. In practice, acoustic scene signals' characteristics may be affected by various factors, such as the choice of recording devices and the change of recording locations. When an established ASC system predicts scene classes on audios recorded in unseen scenarios, its accuracy may drop significantly. The long-duration sounds not only contain domain-independent acoustic scene information, but also contain channel information determined by the recording conditions, which is prone to over-fitting. For a more robust ASC system, We propose a robust feature learning (RFL) framework to train the CNN. The RFL framework down-weights CNN learning specifically on long-duration sounds. The proposed method is to train an auxiliary classifier with only long-duration sound information as input. The auxiliary classifier is trained with an auxiliary loss function that assigns less learning weight to poorly classified examples than the standard cross-entropy loss. The experimental results show that the proposed RFL framework can obtain a more robust acoustic scene classifier towards unseen devices and cities.
A Lottery Ticket Hypothesis Framework for Low-Complexity Device-Robust Neural Acoustic Scene Classification
Jul 03, 2021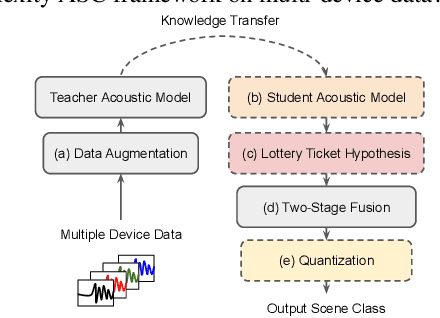
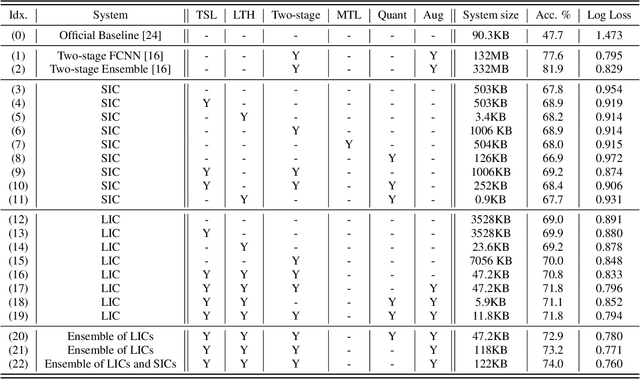
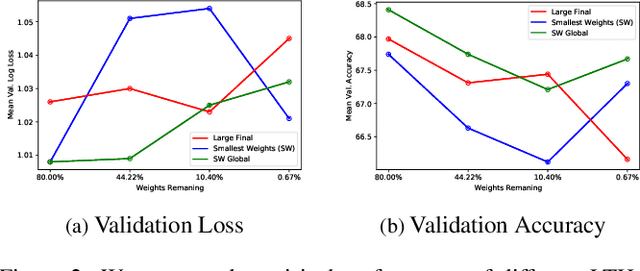

We propose a novel neural model compression strategy combining data augmentation, knowledge transfer, pruning, and quantization for device-robust acoustic scene classification (ASC). Specifically, we tackle the ASC task in a low-resource environment leveraging a recently proposed advanced neural network pruning mechanism, namely Lottery Ticket Hypothesis (LTH), to find a sub-network neural model associated with a small amount non-zero model parameters. The effectiveness of LTH for low-complexity acoustic modeling is assessed by investigating various data augmentation and compression schemes, and we report an efficient joint framework for low-complexity multi-device ASC, called Acoustic Lottery. Acoustic Lottery could compress an ASC model over $1/10^{4}$ and attain a superior performance (validation accuracy of 74.01% and Log loss of 0.76) compared to its not compressed seed model. All results reported in this work are based on a joint effort of four groups, namely GT-USTC-UKE-Tencent, aiming to address the "Low-Complexity Acoustic Scene Classification (ASC) with Multiple Devices" in the DCASE 2021 Challenge Task 1a.
* 5 figures. DCASE 2021. The project started in November 2020
Enhancing Sound Texture in CNN-Based Acoustic Scene Classification
Jan 06, 2019



Acoustic scene classification is the task of identifying the scene from which the audio signal is recorded. Convolutional neural network (CNN) models are widely adopted with proven successes in acoustic scene classification. However, there is little insight on how an audio scene is perceived in CNN, as what have been demonstrated in image recognition research. In the present study, the Class Activation Mapping (CAM) is utilized to analyze how the log-magnitude Mel-scale filter-bank (log-Mel) features of different acoustic scenes are learned in a CNN classifier. It is noted that distinct high-energy time-frequency components of audio signals generally do not correspond to strong activation on CAM, while the background sound texture are well learned in CNN. In order to make the sound texture more salient, we propose to apply the Difference of Gaussian (DoG) and Sobel operator to process the log-Mel features and enhance edge information of the time-frequency image. Experimental results on the DCASE 2017 ASC challenge show that using edge enhanced log-Mel images as input feature of CNN significantly improves the performance of audio scene classification.