 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lottery Ticket Hypothesis Framework for Low-Complexity Device-Robust Neural Acoustic Scene Classification
Jul 03, 2021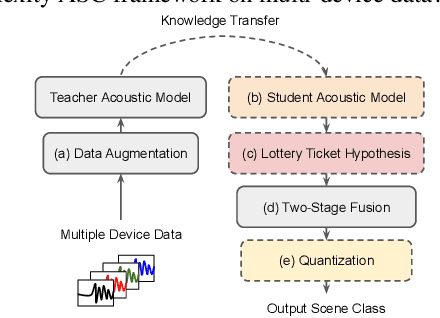
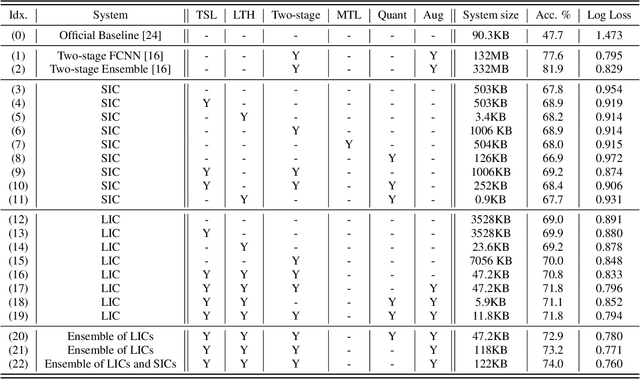
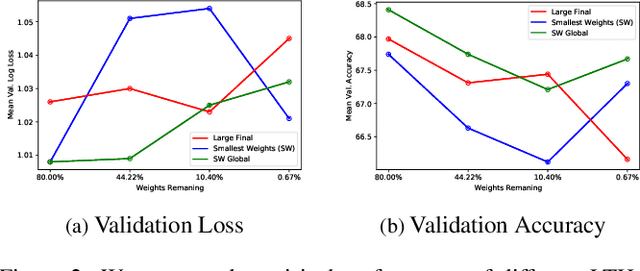

We propose a novel neural model compression strategy combining data augmentation, knowledge transfer, pruning, and quantization for device-robust acoustic scene classification (ASC). Specifically, we tackle the ASC task in a low-resource environment leveraging a recently proposed advanced neural network pruning mechanism, namely Lottery Ticket Hypothesis (LTH), to find a sub-network neural model associated with a small amount non-zero model parameters. The effectiveness of LTH for low-complexity acoustic modeling is assessed by investigating various data augmentation and compression schemes, and we report an efficient joint framework for low-complexity multi-device ASC, called Acoustic Lottery. Acoustic Lottery could compress an ASC model over $1/10^{4}$ and attain a superior performance (validation accuracy of 74.01% and Log loss of 0.76) compared to its not compressed seed model. All results reported in this work are based on a joint effort of four groups, namely GT-USTC-UKE-Tencent, aiming to address the "Low-Complexity Acoustic Scene Classification (ASC) with Multiple Devices" in the DCASE 2021 Challenge Task 1a.
* 5 figures. DCASE 2021. The project started in November 2020
A Two-Stage Approach to Device-Robust Acoustic Scene Classification
Nov 03, 2020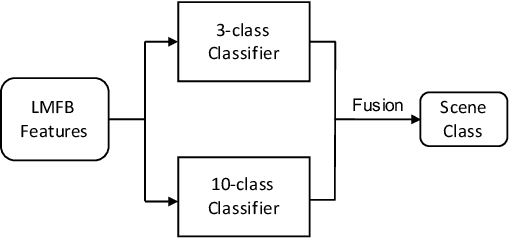

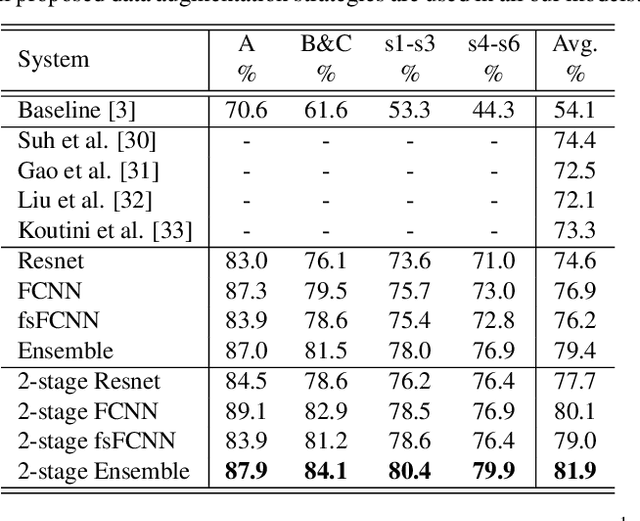
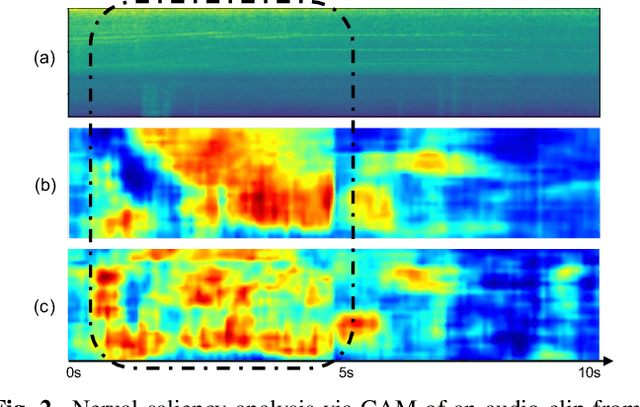
To improve device robustness, a highly desirable key feature of a competitive data-driven acoustic scene classification (ASC) system, a novel two-stage system based on fully convolutional neural networks (CNNs) is proposed. Our two-stage system leverages on an ad-hoc score combination based on two CNN classifiers: (i) the first CNN classifies acoustic inputs into one of three broad classes, and (ii) the second CNN classifies the same inputs into one of ten finer-grained classes. Three different CNN architectures are explored to implement the two-stage classifiers, and a frequency sub-sampling scheme is investigated. Moreover, novel data augmentation schemes for ASC are also investigated. Evaluated on DCASE 2020 Task 1a, our results show that the proposed ASC system attains a state-of-the-art accuracy on the development set, where our best system, a two-stage fusion of CNN ensembles, delivers a 81.9% average accuracy among multi-device test data, and it obtains a significant improvement on unseen devices. Finally, neural saliency analysis with class activation mapping (CAM) gives new insights on the patterns learnt by our models.
Device-Robust Acoustic Scene Classification Based on Two-Stage Categorization and Data Augmentation
Aug 27, 2020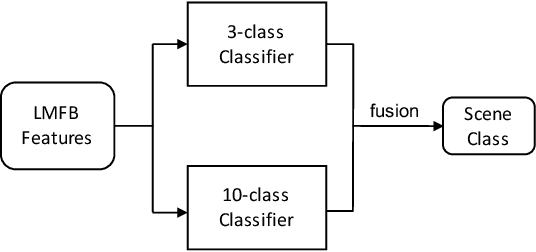
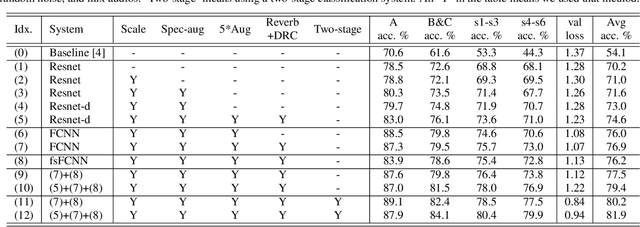
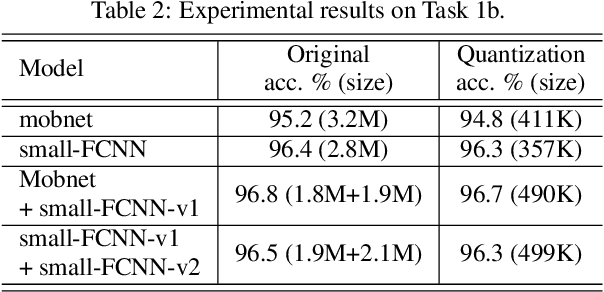
In this technical report, we present a joint effort of four groups, namely GT, USTC, Tencent, and UKE, to tackle Task 1 - Acoustic Scene Classification (ASC) in the DCASE 2020 Challenge. Task 1 comprises two different sub-tasks: (i) Task 1a focuses on ASC of audio signals recorded with multiple (real and simulated) devices into ten different fine-grained classes, and (ii) Task 1b concerns with classification of data into three higher-level classes using low-complexity solutions. For Task 1a, we propose a novel two-stage ASC system leveraging upon ad-hoc score combination of two convolutional neural networks (CNNs), classifying the acoustic input according to three classes, and then ten classes, respectively. Four different CNN-based architectures are explored to implement the two-stage classifiers, and several data augmentation techniques are also investigated. For Task 1b, we leverage upon a quantization method to reduce the complexity of two of our top-accuracy three-classes CNN-based architectures. On Task 1a development data set, an ASC accuracy of 76.9\% is attained using our best single classifier and data augmentation. An accuracy of 81.9\% is then attained by a final model fusion of our two-stage ASC classifiers. On Task 1b development data set, we achieve an accuracy of 96.7\% with a model size smaller than 500KB. Code is available: https://github.com/MihawkHu/DCASE2020_task1.