 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Paper and Code
Mar 31, 2022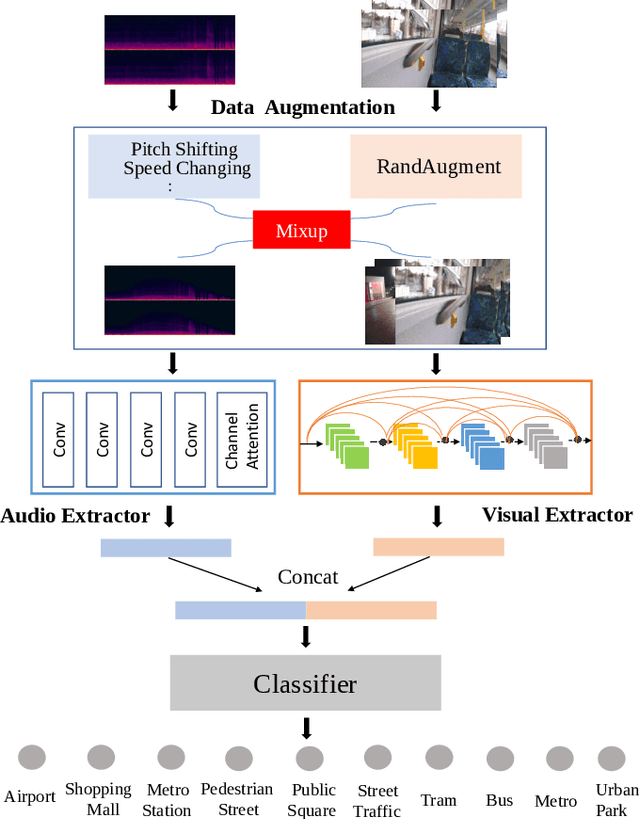
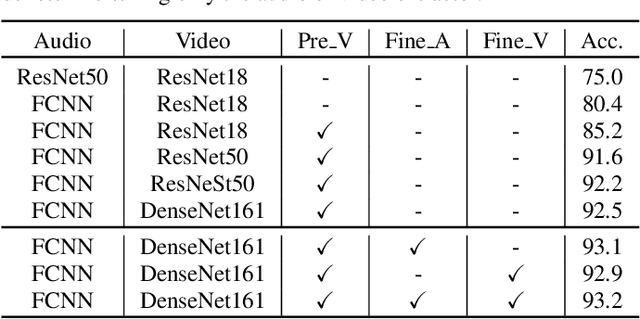
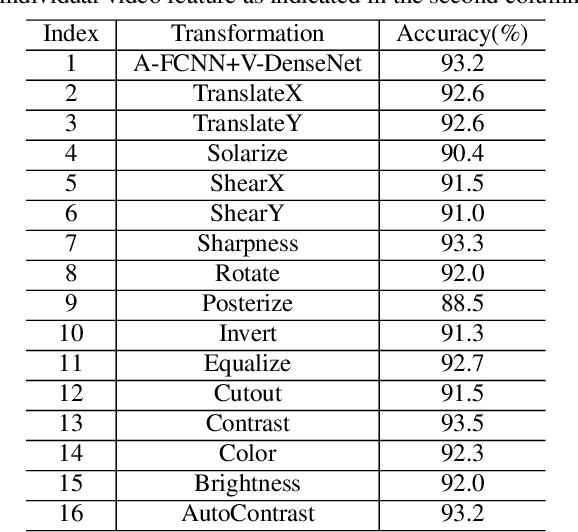
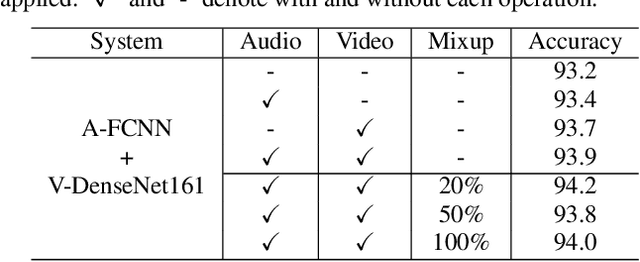
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.