 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Feature Learning on Long-Duration Sounds for Acoustic Scene Classification
Paper and Code
Aug 11, 2021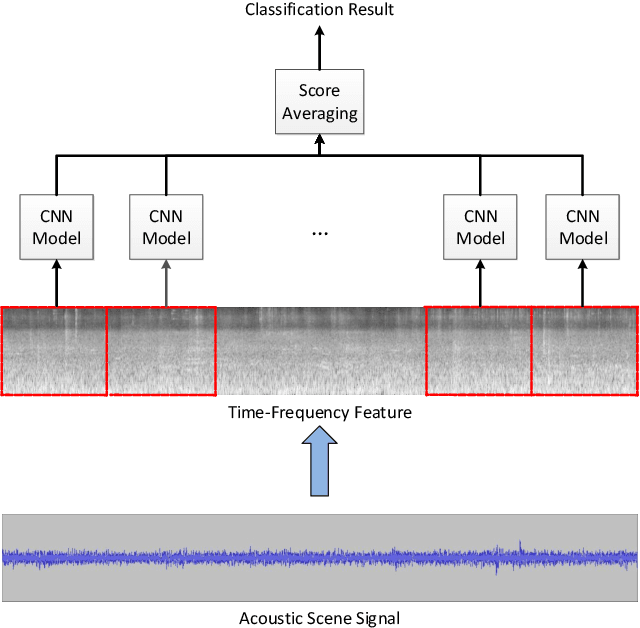
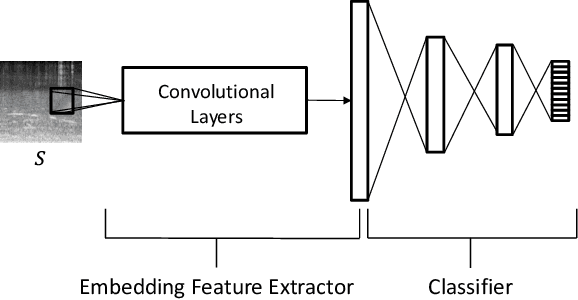
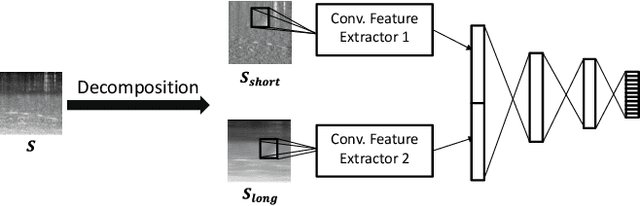
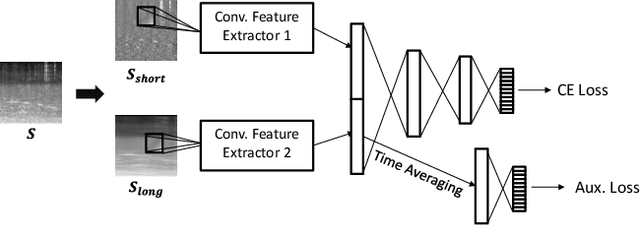
Acoustic scene classification (ASC) aims to identify the type of scene (environment) in which a given audio signal is recorded. The log-mel feature and convolutional neural network (CNN) have recently become the most popular time-frequency (TF) feature representation and classifier in ASC. An audio signal recorded in a scene may include various sounds overlapping in time and frequency. The previous study suggests that separately considering the long-duration sounds and short-duration sounds in CNN may improve ASC accuracy. This study addresses the problem of the generalization ability of acoustic scene classifiers. In practice, acoustic scene signals' characteristics may be affected by various factors, such as the choice of recording devices and the change of recording locations. When an established ASC system predicts scene classes on audios recorded in unseen scenarios, its accuracy may drop significantly. The long-duration sounds not only contain domain-independent acoustic scene information, but also contain channel information determined by the recording conditions, which is prone to over-fitting. For a more robust ASC system, We propose a robust feature learning (RFL) framework to train the CNN. The RFL framework down-weights CNN learning specifically on long-duration sounds. The proposed method is to train an auxiliary classifier with only long-duration sound information as input. The auxiliary classifier is trained with an auxiliary loss function that assigns less learning weight to poorly classified examples than the standard cross-entropy loss. The experimental results show that the proposed RFL framework can obtain a more robust acoustic scene classifier towards unseen devices and cities.