 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference skipping for more efficient real-time speech enhancement with parallel RNNs
Paper and Code
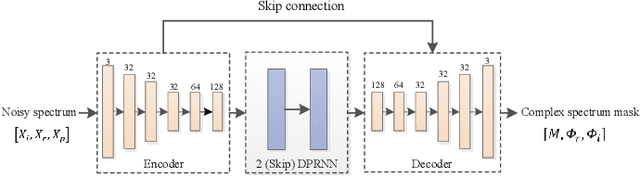
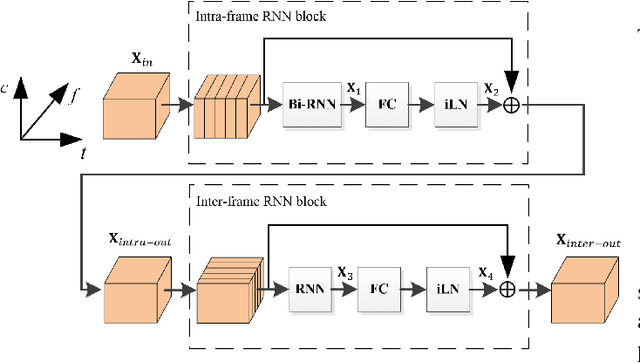
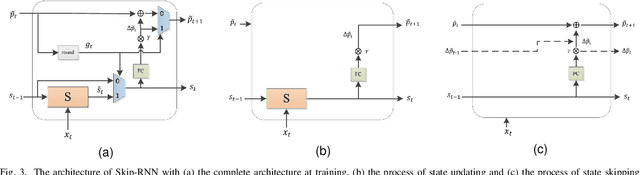
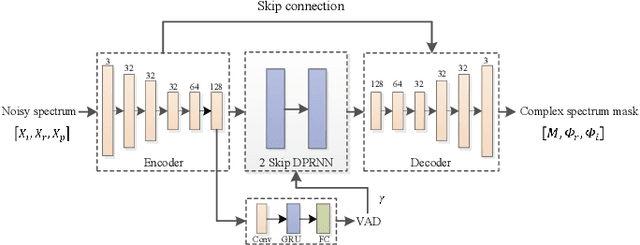
Deep neural network (DNN) based speech enhancement models have attracted extensive attention due to their promising performance. However, it is difficult to deploy a powerful DNN in real-time applications because of its high computational cost. Typical compression methods such as pruning and quantization do not make good use of the data characteristics. In this paper, we introduce the Skip-RNN strategy into speech enhancement models with parallel RNNs. The states of the RNNs update intermittently without interrupting the update of the output mask, which leads to significant reduction of computational load without evident audio artifacts. To better leverage the difference between the voice and the noise, we further regularize the skipping strategy with voice activity detection (VAD) guidance, saving more computational load. Experiments on a high-performance speech enhancement model, dual-path convolutional recurrent network (DPCRN), show the superiority of our strategy over strategies like network pruning or directly training a smaller model. We also validate the generalization of the proposed strategy on two other competitive speech enhancement models.