 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement
Paper and Code
Jul 12, 2021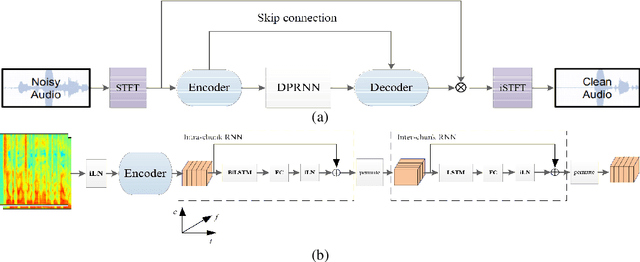
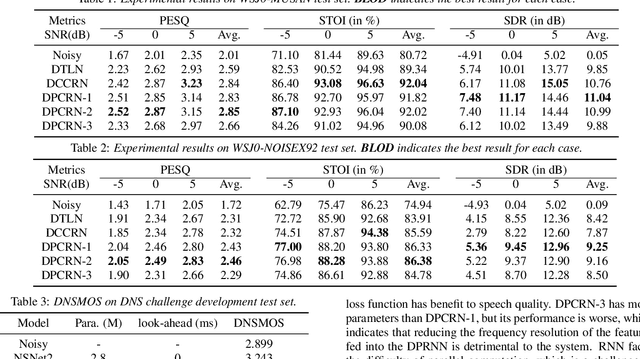
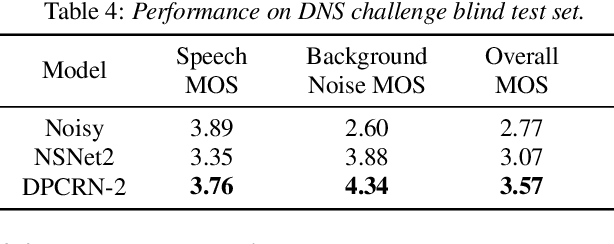
The dual-path RNN (DPRNN) was proposed to more effectively model extremely long sequences for speech separation in the time domain. By splitting long sequences to smaller chunks and applying intra-chunk and inter-chunk RNNs, the DPRNN reached promising performance in speech separation with a limited model size. In this paper, we combine the DPRNN module with Convolution Recurrent Network (CRN) and design a model called Dual-Path Convolution Recurrent Network (DPCRN) for speech enhancement in the time-frequency domain. We replace the RNNs in the CRN with DPRNN modules, where the intra-chunk RNNs are used to model the spectrum pattern in a single frame and the inter-chunk RNNs are used to model the dependence between consecutive frames. With only 0.8M parameters, the submitted DPCRN model achieves an overall mean opinion score (MOS) of 3.57 in the wide band scenario track of the Interspeech 2021 Deep Noise Suppression (DNS) challenge. Evaluations on some other test sets also show the efficacy of our model.