 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-Net++: Hierarchical Dynamic Chunking for Tokenizer-Free Language Modelling in Morphologically-Rich Languages
Aug 07, 2025Byte-level language models eliminate fragile tokenizers but face computational challenges in morphologically-rich languages (MRLs), where words span many bytes. We propose H-NET++, a hierarchical dynamic-chunking model that learns linguistically-informed segmentation through end-to-end training. Key innovations include: (1) a lightweight Transformer context-mixer (1.9M parameters) for cross-chunk attention, (2) a two-level latent hyper-prior for document-level consistency, (3) specialized handling of orthographic artifacts (e.g. Persian ZWNJ), and (4) curriculum-based training with staged sequence lengths. On a 1.4B-token Persian corpus, H-NET++ achieves state-of-the-art results: 0.159 BPB reduction versus BPE-based GPT-2-fa (12% better compression), 5.4pp gain on ParsGLUE, 53% improved robustness to ZWNJ corruption, and 73.8% F1 on gold morphological boundaries. Our learned chunks align with Persian morphology without explicit supervision, demonstrating that hierarchical dynamic chunking provides an effective tokenizer-free solution for MRLs while maintaining computational efficiency.
Explanation, Debate, Align: A Weak-to-Strong Framework for Language Model Generalization
Sep 11, 2024The rapid advancement of artificial intelligence systems has brought the challenge of AI alignment to the forefront of research, particularly in complex decision-making and task execution. As these systems surpass human-level performance in sophisticated problems, ensuring their alignment with human values, intentions, and ethical guidelines becomes crucial. Building on previous work in explanation generation for human-agent alignment, we address the more complex dynamics of multi-agent systems and human-AI teams. This paper introduces a novel approach to model alignment through weak-to-strong generalization in the context of language models. We present a framework where a strong model facilitates the improvement of a weaker model, bridging the gap between explanation generation and model alignment. Our method, formalized as a facilitation function, allows for the transfer of capabilities from advanced models to less capable ones without direct access to extensive training data. Our results suggest that this facilitation-based approach not only enhances model performance but also provides insights into the nature of model alignment and the potential for scalable oversight of AI systems.
SumRecom: A Personalized Summarization Approach by Learning from Users' Feedback
Aug 02, 2024Existing multi-document summarization approaches produce a uniform summary for all users without considering individuals' interests, which is highly impractical. Making a user-specific summary is a challenging task as it requires: i) acquiring relevant information about a user; ii) aggregating and integrating the information into a user-model; and iii) utilizing the provided information in making the personalized summary. Therefore, in this paper, we propose a solution to a substantial and challenging problem in summarization, i.e., recommending a summary for a specific user. The proposed approach, called SumRecom, brings the human into the loop and focuses on three aspects: personalization, interaction, and learning user's interest without the need for reference summaries. SumRecom has two steps: i) The user preference extractor to capture users' inclination in choosing essential concepts, and ii) The summarizer to discover the user's best-fitted summary based on the given feedback. Various automatic and human evaluations on the benchmark dataset demonstrate the supremacy SumRecom in generating user-specific summaries. Document summarization and Interactive summarization and Personalized summarization and Reinforcement learning.
Adapting LLMs for Efficient, Personalized Information Retrieval: Methods and Implications
Nov 21, 2023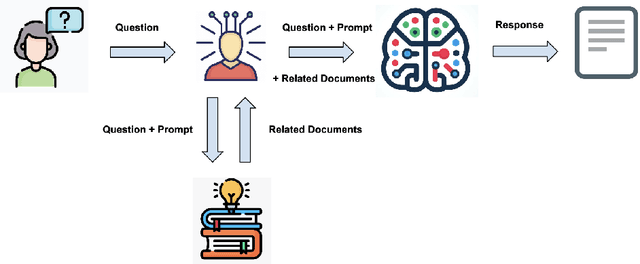
The advent of Large Language Models (LLMs) heralds a pivotal shift in online user interactions with information. Traditional Information Retrieval (IR) systems primarily relied on query-document matching, whereas LLMs excel in comprehending and generating human-like text, thereby enriching the IR experience significantly. While LLMs are often associated with chatbot functionalities, this paper extends the discussion to their explicit application in information retrieval. We explore methodologies to optimize the retrieval process, select optimal models, and effectively scale and orchestrate LLMs, aiming for cost-efficiency and enhanced result accuracy. A notable challenge, model hallucination-where the model yields inaccurate or misinterpreted data-is addressed alongside other model-specific hurdles. Our discourse extends to crucial considerations including user privacy, data optimization, and the necessity for system clarity and interpretability. Through a comprehensive examination, we unveil not only innovative strategies for integrating Language Models (LLMs) with Information Retrieval (IR) systems, but also the consequential considerations that underline the need for a balanced approach aligned with user-centric principles.
A Personalized Reinforcement Learning Summarization Service for Learning Structure from Unstructured Data
Jul 09, 2023



The exponential growth of textual data has created a crucial need for tools that assist users in extracting meaningful insights. Traditional document summarization approaches often fail to meet individual user requirements and lack structure for efficient information processing. To address these limitations, we propose Summation, a hierarchical personalized concept-based summarization approach. It synthesizes documents into a concise hierarchical concept map and actively engages users by learning and adapting to their preferences. Using a Reinforcement Learning algorithm, Summation generates personalized summaries for unseen documents on specific topics. This framework enhances comprehension, enables effective navigation, and empowers users to extract meaningful insights from large document collections aligned with their unique requirements.
Towards Personalized and Human-in-the-Loop Document Summarization
Aug 21, 2021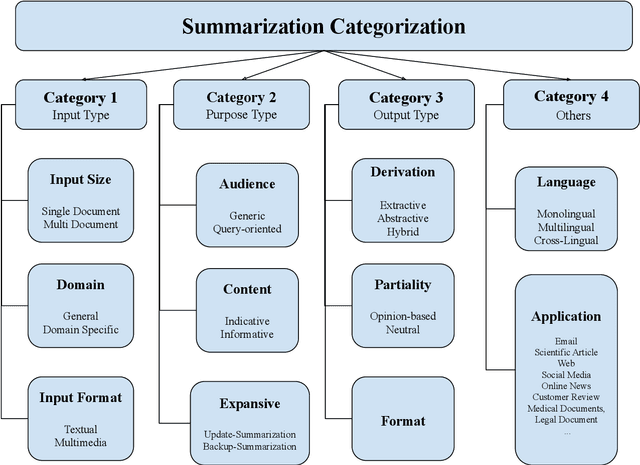
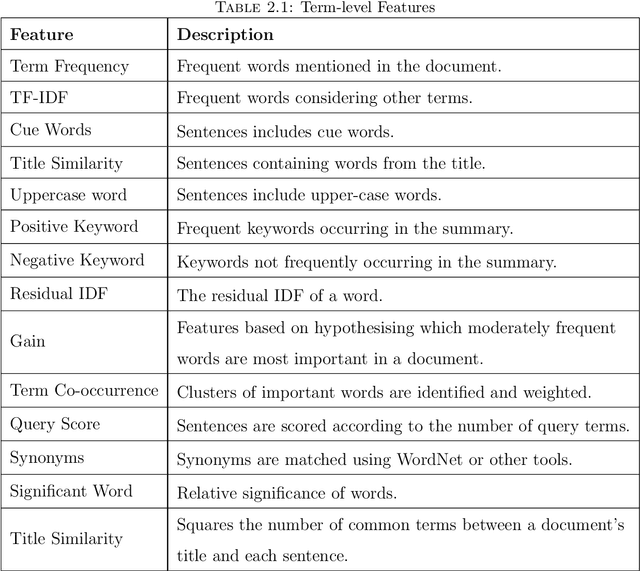
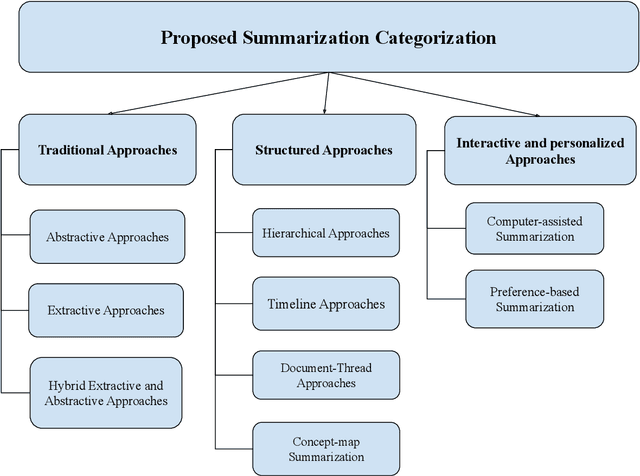
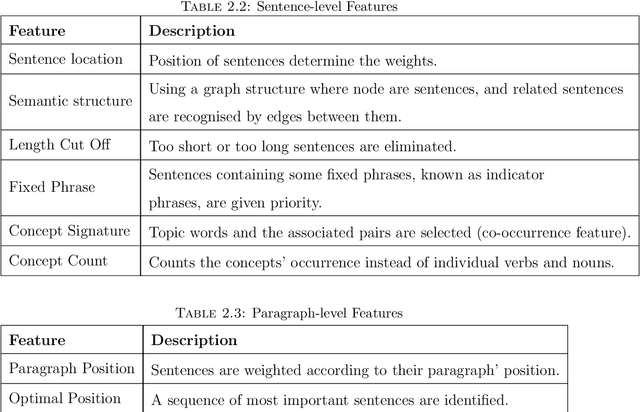
The ubiquitous availability of computing devices and the widespread use of the internet have generated a large amount of data continuously. Therefore, the amount of available information on any given topic is far beyond humans' processing capacity to properly process, causing what is known as information overload. To efficiently cope with large amounts of information and generate content with significant value to users, we require identifying, merging and summarising information. Data summaries can help gather related information and collect it into a shorter format that enables answering complicated questions, gaining new insight and discovering conceptual boundaries. This thesis focuses on three main challenges to alleviate information overload using novel summarisation techniques. It further intends to facilitate the analysis of documents to support personalised information extraction. This thesis separates the research issues into four areas, covering (i) feature engineering in document summarisation, (ii) traditional static and inflexible summaries, (iii) traditional generic summarisation approaches, and (iv) the need for reference summaries. We propose novel approaches to tackle these challenges, by: i)enabling automatic intelligent feature engineering, ii) enabling flexible and interactive summarisation, iii) utilising intelligent and personalised summarisation approaches. The experimental results prove the efficiency of the proposed approaches compared to other state-of-the-art models. We further propose solutions to the information overload problem in different domains through summarisation, covering network traffic data, health data and business process data.
A Query Language for Summarizing and Analyzing Business Process Data
May 23, 2021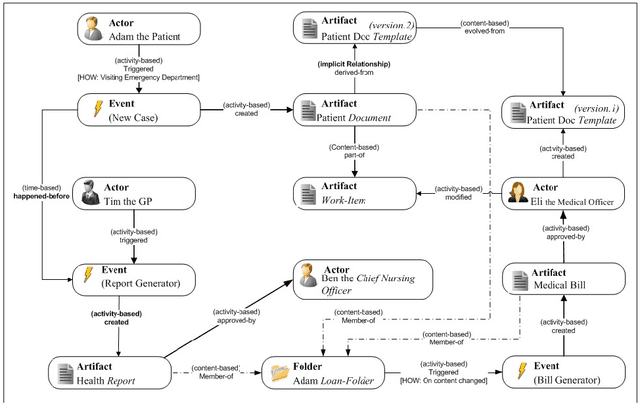
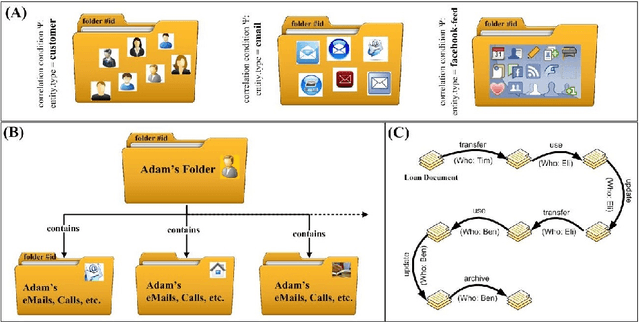
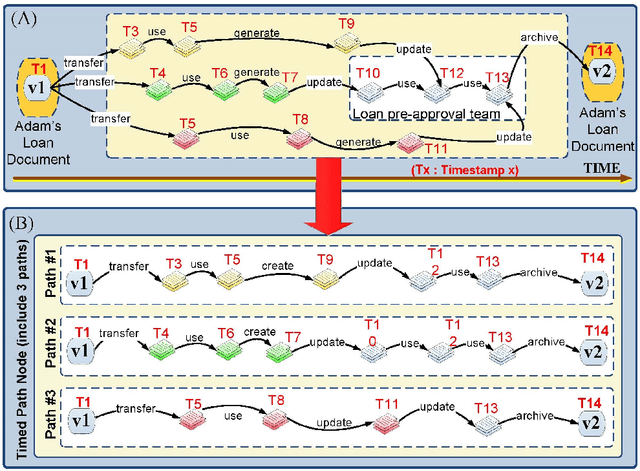
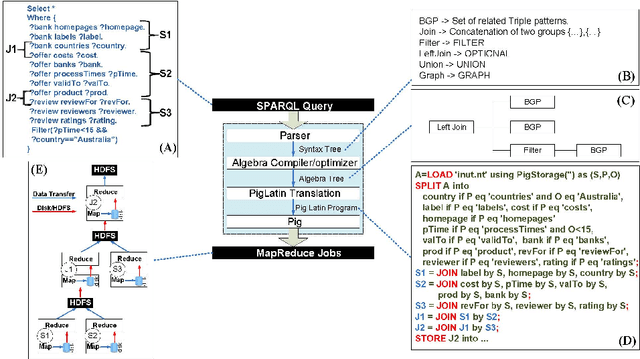
In modern enterprises, Business Processes (BPs) are realized over a mix of workflows, IT systems, Web services and direct collaborations of people. Accordingly, process data (i.e., BP execution data such as logs containing events, interaction messages and other process artifacts) is scattered across several systems and data sources, and increasingly show all typical properties of the Big Data. Understanding the execution of process data is challenging as key business insights remain hidden in the interactions among process entities: most objects are interconnected, forming complex, heterogeneous but often semi-structured networks. In the context of business processes, we consider the Big Data problem as a massive number of interconnected data islands from personal, shared and business data. We present a framework to model process data as graphs, i.e., Process Graph, and present abstractions to summarize the process graph and to discover concept hierarchies for entities based on both data objects and their interactions in process graphs. We present a language, namely BP-SPARQL, for the explorative querying and understanding of process graphs from various user perspectives. We have implemented a scalable architecture for querying, exploration and analysis of process graphs. We report on experiments performed on both synthetic and real-world datasets that show the viability and efficiency of the approach.
Am I Rare? An Intelligent Summarization Approach for Identifying Hidden Anomalies
Dec 24, 2020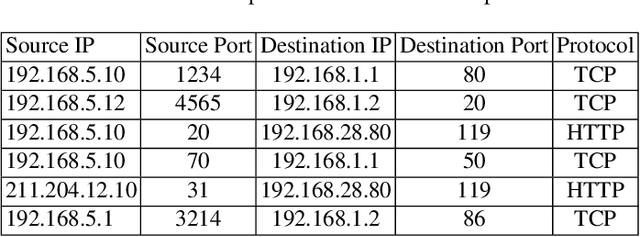
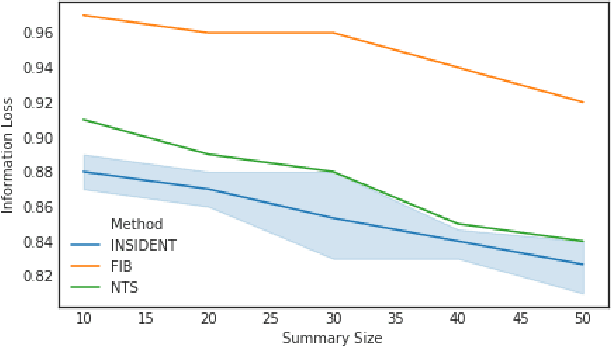
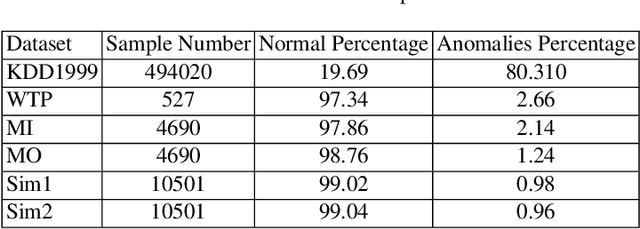
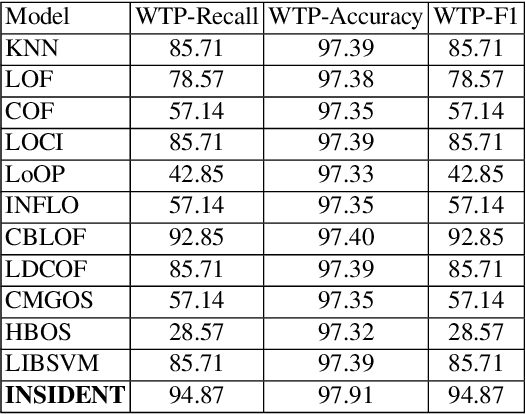
Monitoring network traffic data to detect any hidden patterns of anomalies is a challenging and time-consuming task that requires high computing resources. To this end, an appropriate summarization technique is of great importance, where it can be a substitute for the original data. However, the summarized data is under the threat of removing anomalies. Therefore, it is vital to create a summary that can reflect the same pattern as the original data. Therefore, in this paper, we propose an INtelligent Summarization approach for IDENTifying hidden anomalies, called INSIDENT. The proposed approach guarantees to keep the original data distribution in summarized data. Our approach is a clustering-based algorithm that dynamically maps original feature space to a new feature space by locally weighting features in each cluster. Therefore, in new feature space, similar samples are closer, and consequently, outliers are more detectable. Besides, selecting representatives based on cluster size keeps the same distribution as the original data in summarized data. INSIDENT can be used both as the preprocess approach before performing anomaly detection algorithms and anomaly detection algorithm. The experimental results on benchmark datasets prove a summary of the data can be a substitute for original data in the anomaly detection task.
Adaptive Summaries: A Personalized Concept-based Summarization Approach by Learning from Users' Feedback
Dec 24, 2020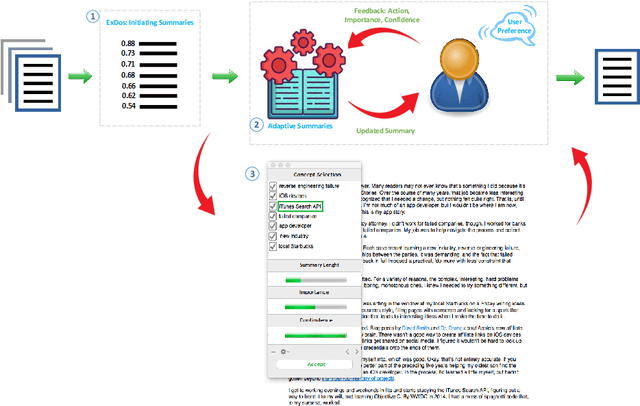
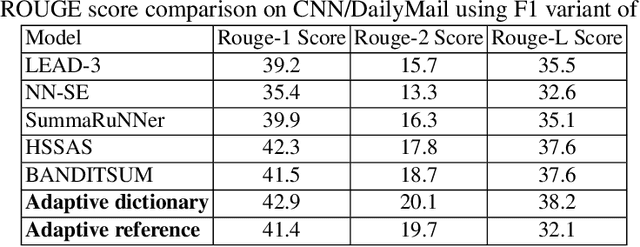
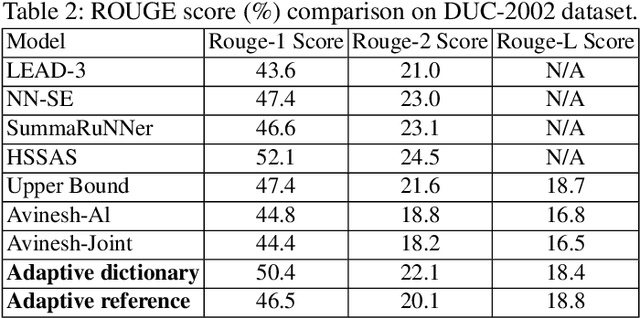
Exploring the tremendous amount of data efficiently to make a decision, similar to answering a complicated question, is challenging with many real-world application scenarios. In this context, automatic summarization has substantial importance as it will provide the foundation for big data analytic. Traditional summarization approaches optimize the system to produce a short static summary that fits all users that do not consider the subjectivity aspect of summarization, i.e., what is deemed valuable for different users, making these approaches impractical in real-world use cases. This paper proposes an interactive concept-based summarization model, called Adaptive Summaries, that helps users make their desired summary instead of producing a single inflexible summary. The system learns from users' provided information gradually while interacting with the system by giving feedback in an iterative loop. Users can choose either reject or accept action for selecting a concept being included in the summary with the importance of that concept from users' perspectives and confidence level of their feedback. The proposed approach can guarantee interactive speed to keep the user engaged in the process. Furthermore, it eliminates the need for reference summaries, which is a challenging issue for summarization tasks. Evaluations show that Adaptive Summaries helps users make high-quality summaries based on their preferences by maximizing the user-desired content in the generated summaries.
Are We On The Same Page? Hierarchical Explanation Generation for Planning Tasks in Human-Robot Teaming using Reinforcement Learning
Dec 22, 2020
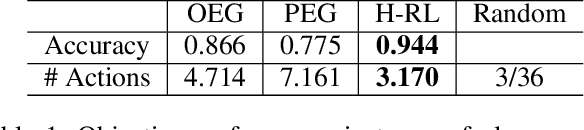
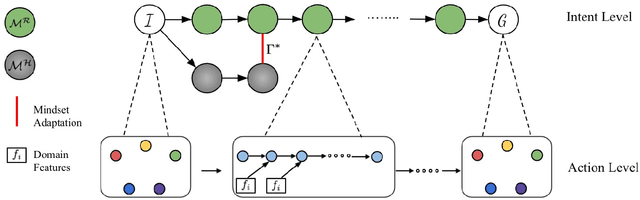
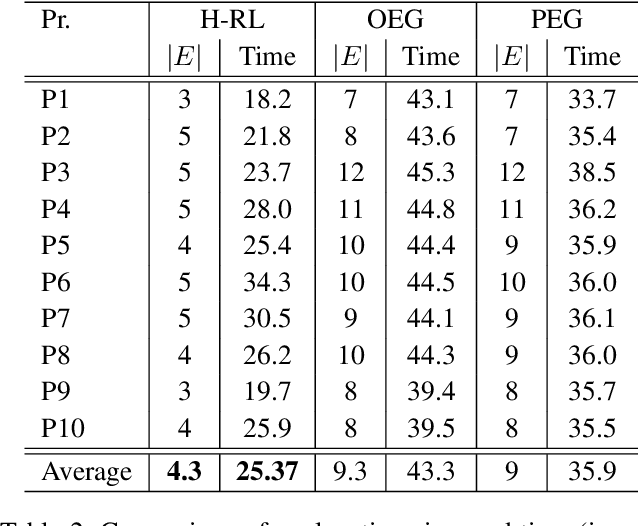
Providing explanations is considered an imperative ability for an AI agent in a human-robot teaming framework. The right explanation provides the rationale behind an AI agent's decision making. However, to maintain the human teammate's cognitive demand to comprehend the provided explanations, prior works have focused on providing explanations in a specific order or intertwining the explanation generation with plan execution. These approaches, however, do not consider the degree of details they share throughout the provided explanations. In this work, we argue that the explanations, especially the complex ones, should be abstracted to be aligned with the level of details the teammate desires to maintain the cognitive load of the recipient. The challenge here is to learn a hierarchical model of explanations and details the agent requires to yield the explanations as an objective. Moreover, the agent needs to follow a high-level plan in a task domain such that the agent can transfer learned teammate preferences to a scenario where lower-level control policies are different, while the high-level plan remains the same. Results confirmed our hypothesis that the process of understanding an explanation was a dynamic hierarchical process. The human preference that reflected this aspect corresponded exactly to creating and employing abstraction for knowledge assimilation hidden deeper in our cognitive process. We showed that hierarchical explanations achieved better task performance and behavior interpretability while reduced cognitive load. These results shed light on designing explainable agents utilizing reinforcement learning and planning across various domains.