 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting LLMs for Efficient, Personalized Information Retrieval: Methods and Implications
Paper and Code
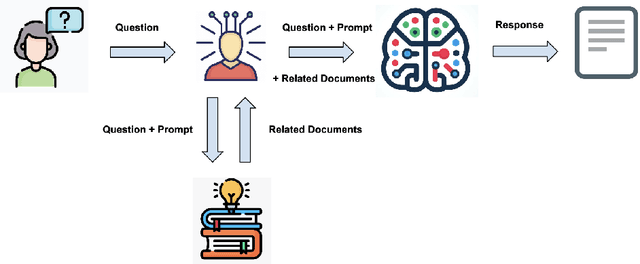
The advent of Large Language Models (LLMs) heralds a pivotal shift in online user interactions with information. Traditional Information Retrieval (IR) systems primarily relied on query-document matching, whereas LLMs excel in comprehending and generating human-like text, thereby enriching the IR experience significantly. While LLMs are often associated with chatbot functionalities, this paper extends the discussion to their explicit application in information retrieval. We explore methodologies to optimize the retrieval process, select optimal models, and effectively scale and orchestrate LLMs, aiming for cost-efficiency and enhanced result accuracy. A notable challenge, model hallucination-where the model yields inaccurate or misinterpreted data-is addressed alongside other model-specific hurdles. Our discourse extends to crucial considerations including user privacy, data optimization, and the necessity for system clarity and interpretability. Through a comprehensive examination, we unveil not only innovative strategies for integrating Language Models (LLMs) with Information Retrieval (IR) systems, but also the consequential considerations that underline the need for a balanced approach aligned with user-centric principles.