 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
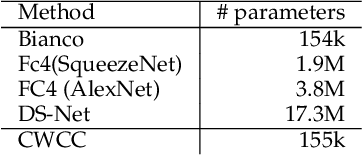
Add to EdgeRobust channel-wise illumination estimation
Nov 10, 2021

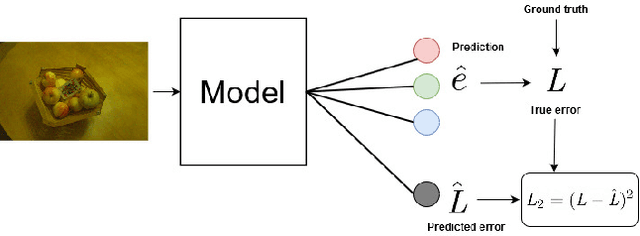
Recently, Convolutional Neural Networks (CNNs) have been widely used to solve the illuminant estimation problem and have often led to state-of-the-art results. Standard approaches operate directly on the input image. In this paper, we argue that this problem can be decomposed into three channel-wise independent and symmetric sub-problems and propose a novel CNN-based illumination estimation approach based on this decomposition. The proposed method substantially reduces the number of parameters needed to solve the task while achieving competitive experimental results compared to state-of-the-art methods. Furthermore, the practical application of illumination estimation techniques typically requires identifying the extreme error cases. This can be achieved using an uncertainty estimation technique. In this work, we propose a novel color constancy uncertainty estimation approach that augments the trained model with an auxiliary branch which learns to predict the error based on the feature representation. Intuitively, the model learns which feature combinations are robust and are thus likely to yield low errors and which combinations result in erroneous estimates. We test this approach on the proposed method and show that it can indeed be used to avoid several extreme error cases and, thus, improves the practicality of the proposed technique.
Monte Carlo Dropout Ensembles for Robust Illumination Estimation
Jul 20, 2020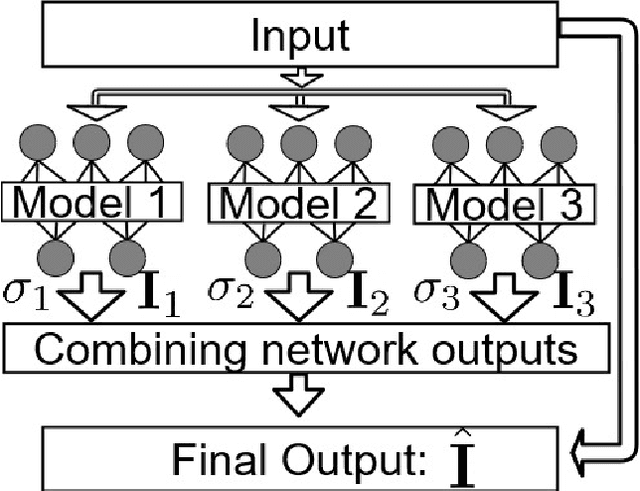
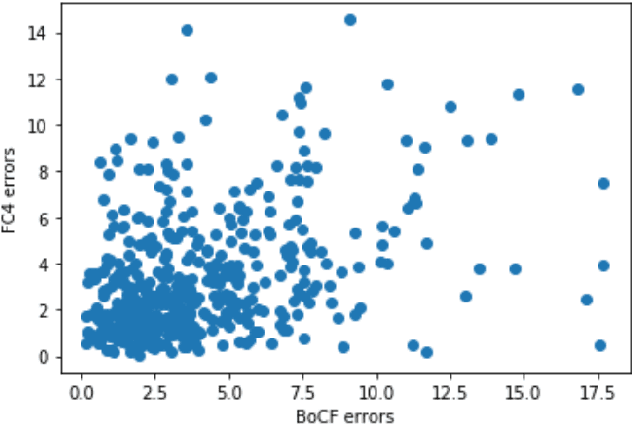

Computational color constancy is a preprocessing step used in many camera systems. The main aim is to discount the effect of the illumination on the colors in the scene and restore the original colors of the objects. Recently, several deep learning-based approaches have been proposed to solve this problem and they often led to state-of-the-art performance in terms of average errors. However, for extreme samples, these methods fail and lead to high errors. In this paper, we address this limitation by proposing to aggregate different deep learning methods according to their output uncertainty. We estimate the relative uncertainty of each approach using Monte Carlo dropout and the final illumination estimate is obtained as the sum of the different model estimates weighted by the log-inverse of their corresponding uncertainties. The proposed framework leads to state-of-the-art performance on INTEL-TAU dataset.
Probabilistic Color Constancy
May 06, 2020

In this paper, we propose a novel unsupervised color constancy method, called Probabilistic Color Constancy (PCC). We define a framework for estimating the illumination of a scene by weighting the contribution of different image regions using a graph-based representation of the image. To estimate the weight of each (super-)pixel, we rely on two assumptions: (Super-)pixels with similar colors contribute similarly and darker (super-)pixels contribute less. The resulting system has one global optimum solution. The proposed method achieves competitive performance, compared to the state-of-the-art, on INTEL-TAU dataset.
INTEL-TAU: A Color Constancy Dataset
Nov 20, 2019


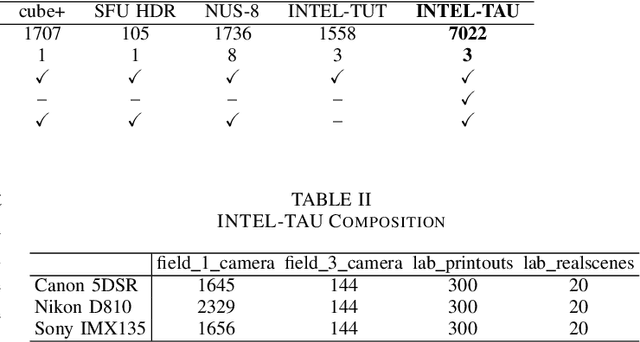
In this paper, we describe a new large dataset for illumination estimation. This dataset, called INTEL-TAU, contains 7022 images in total, which makes it the largest available high-resolution dataset for illumination estimation research. The variety of scenes captured using three different camera models, i.e., Canon 5DSR, Nikon D810, and Sony IMX135, makes the dataset appropriate for evaluating the camera and scene invariance of the different illumination estimation techniques. Privacy masking is done for sensitive information, e.g., faces. Thus, the dataset is coherent with the new General Data Protection Regulation (GDPR) regulations. Furthermore, the effect of color shading for mobile images can be evaluated with INTEL-TAU, as we provide both corrected and uncorrected versions of the raw data. We provide in this paper evaluation of several color constancy approaches
Bag of Color Features For Color Constancy
Jun 11, 2019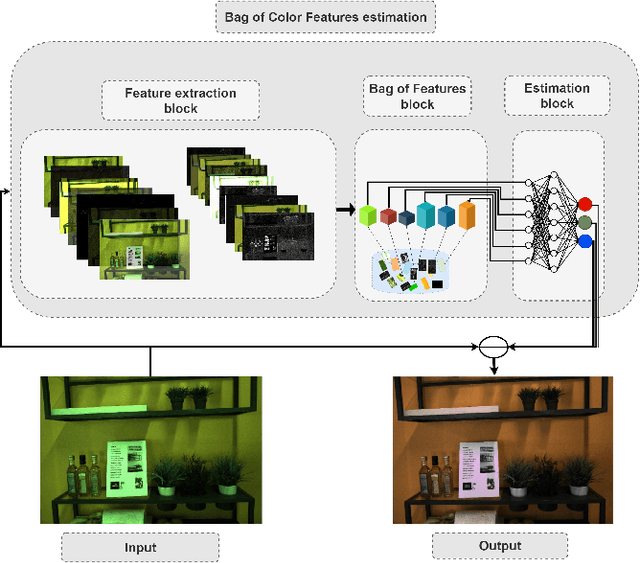
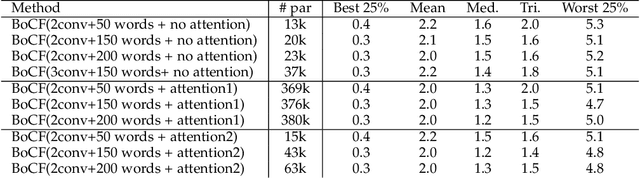

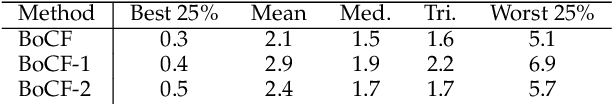
In this paper, we propose a novel color constancy approach, called Bag of Color Features (BoCF), building upon Bag-of-Features pooling. The proposed method substantially reduces the number of parameters needed for illumination estimation. At the same time, the proposed method is consistent with the color constancy assumption stating that global spatial information is not relevant for illumination estimation and local information ( edges, etc.) is sufficient. Furthermore, BoCF is consistent with color constancy statistical approaches and can be interpreted as a learning-based generalization of many statistical approaches. To further improve the illumination estimation accuracy, we propose a novel attention mechanism for the BoCF model with two variants based on self-attention. BoCF approach and its variants achieve competitive, compared to the state of the art, results while requiring much fewer parameters on three benchmark datasets: ColorChecker RECommended, INTEL-TUT version 2, and NUS8.
Color Constancy Convolutional Autoencoder
Jun 04, 2019
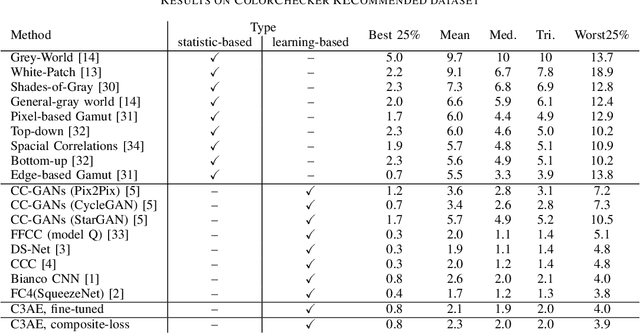

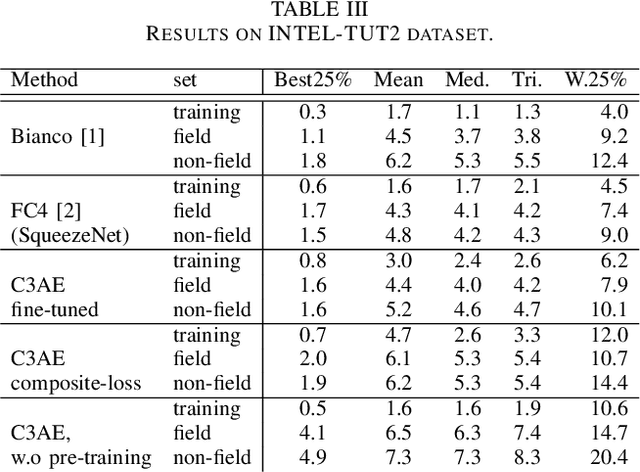
In this paper, we study the importance of pre-training for the generalization capability in the color constancy problem. We propose two novel approaches based on convolutional autoencoders: an unsupervised pre-training algorithm using a fine-tuned encoder and a semi-supervised pre-training algorithm using a novel composite-loss function. This enables us to solve the data scarcity problem and achieve competitive, to the state-of-the-art, results while requiring much fewer parameters on ColorChecker RECommended dataset. We further study the over-fitting phenomenon on the recently introduced version of INTEL-TUT Dataset for Camera Invariant Color Constancy Research, which has both field and non-field scenes acquired by three different camera models.
On Finding Gray Pixels
Jan 12, 2019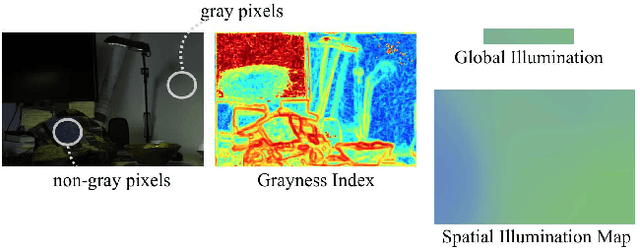
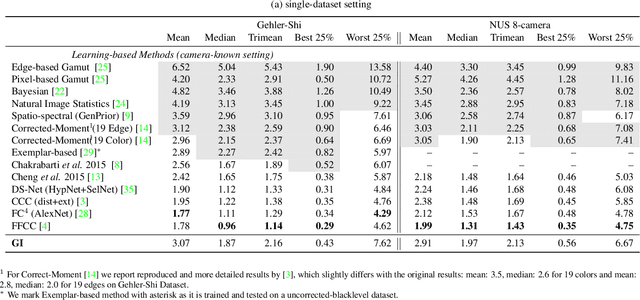

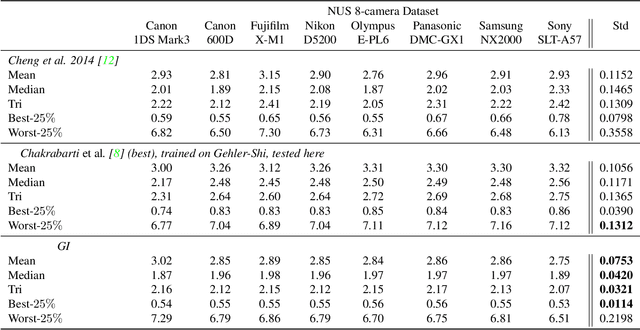
We propose a novel grayness index for finding gray pixels and demonstrate its effectiveness and efficiency in illumination estimation. The grayness index, GI in short, is derived using the Dichromatic Reflection Model and is learning-free. The proposed GI allows estimating one or multiple illumination sources in color-biased images. On standard single-illumination and multiple-illumination estimation benchmarks, GI outperforms state-of-the-art statistical methods and many recent deep net methods. GI is simple and fast, written in a few dozen lines, processing a 1080p image in about 0.4 seconds with a non-optimized Matlab code.
Dichromatic Gray Pixel for Camera-agnostic Color Constancy
Jul 05, 2018
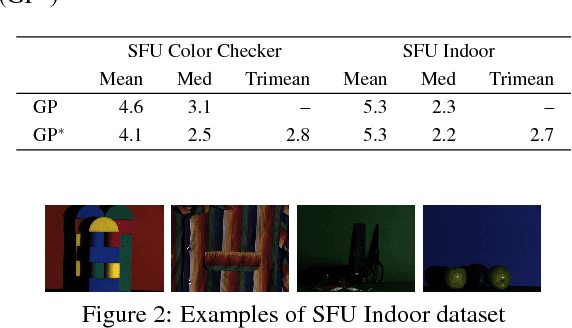
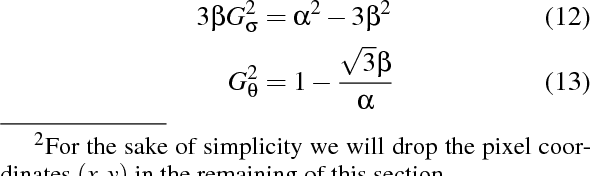
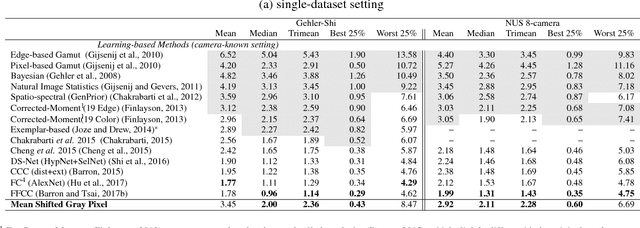
We present a statistical color constancy method that relies on novel gray pixel detection and mean shift clustering. The method, called Mean Shifted Grey Pixel -- MSGP -- is compact, easy to compute and requires no training. Experiments on different datasets show that the proposed approach outperforms state-of-the-art methods in the camera-agnostic scenario. In the setting where the camera is known, MSGP outperforms all statistical methods.
INTEL-TUT Dataset for Camera Invariant Color Constancy Research
Mar 31, 2017



In this paper, we provide a novel dataset designed for camera invariant color constancy research. Camera invariance corresponds to the robustness of an algorithm's performance when run on images of the same scene taken by different cameras. Accordingly, images in the database correspond to several lab and field scenes each of which are captured by three different cameras with minimal registration errors. The lab scenes are also captured under five different illuminations. The spectral responses of cameras and the spectral power distributions of the lab light sources are also provided, as they may prove beneficial for training future algorithms to achieve color constancy. For a fair evaluation of future methods, we provide guidelines for supervised methods with indicated training, validation and testing partitions. Accordingly, we evaluate a recently proposed convolutional neural network based color constancy algorithm as a baseline for future research. As a side contribution, this dataset also includes images taken by a mobile camera with color shading corrected and uncorrected results. This allows research on the effect of color shading as well.
* Download Link for the Dataset: https://etsin.avointiede.fi/dataset/urn-nbn-fi-csc-kata20170321084219004008 Submission Info: Submitted to IEEE TIP
Deep Structured-Output Regression Learning for Computational Color Constancy
Aug 11, 2016
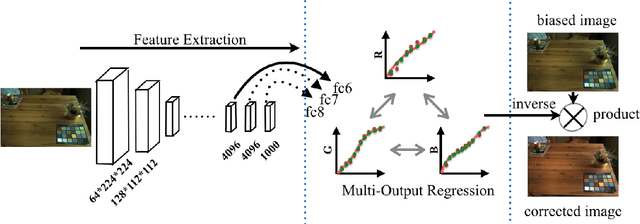


Computational color constancy that requires esti- mation of illuminant colors of images is a fundamental yet active problem in computer vision, which can be formulated into a regression problem. To learn a robust regressor for color constancy, obtaining meaningful imagery features and capturing latent correlations across output variables play a vital role. In this work, we introduce a novel deep structured-output regression learning framework to achieve both goals simultaneously. By borrowing the power of deep convolutional neural networks (CNN) originally designed for visual recognition, the proposed framework can automatically discover strong features for white balancing over different illumination conditions and learn a multi-output regressor beyond underlying relationships between features and targets to find the complex interdependence of dif- ferent dimensions of target variables. Experiments on two public benchmarks demonstrate that our method achieves competitive performance in comparison with the state-of-the-art approaches.