 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDi -- an exemplar-conditioned diffusion model for low-shot counting
Dec 23, 2025Low-shot object counting addresses estimating the number of previously unobserved objects in an image using only few or no annotated test-time exemplars. A considerable challenge for modern low-shot counters are dense regions with small objects. While total counts in such situations are typically well addressed by density-based counters, their usefulness is limited by poor localization capabilities. This is better addressed by point-detection-based counters, which are based on query-based detectors. However, due to limited number of pre-trained queries, they underperform on images with very large numbers of objects, and resort to ad-hoc techniques like upsampling and tiling. We propose CoDi, the first latent diffusion-based low-shot counter that produces high-quality density maps on which object locations can be determined by non-maxima suppression. Our core contribution is the new exemplar-based conditioning module that extracts and adjusts the object prototypes to the intermediate layers of the denoising network, leading to accurate object location estimation. On FSC benchmark, CoDi outperforms state-of-the-art by 15% MAE, 13% MAE and 10% MAE in the few-shot, one-shot, and reference-less scenarios, respectively, and sets a new state-of-the-art on MCAC benchmark by outperforming the top method by 44% MAE. The code is available at https://github.com/gsustar/CoDi.
A Novel Unified Architecture for Low-Shot Counting by Detection and Segmentation
Sep 27, 2024Low-shot object counters estimate the number of objects in an image using few or no annotated exemplars. Objects are localized by matching them to prototypes, which are constructed by unsupervised image-wide object appearance aggregation. Due to potentially diverse object appearances, the existing approaches often lead to overgeneralization and false positive detections. Furthermore, the best-performing methods train object localization by a surrogate loss, that predicts a unit Gaussian at each object center. This loss is sensitive to annotation error, hyperparameters and does not directly optimize the detection task, leading to suboptimal counts. We introduce GeCo, a novel low-shot counter that achieves accurate object detection, segmentation, and count estimation in a unified architecture. GeCo robustly generalizes the prototypes across objects appearances through a novel dense object query formulation. In addition, a novel counting loss is proposed, that directly optimizes the detection task and avoids the issues of the standard surrogate loss. GeCo surpasses the leading few-shot detection-based counters by $\sim$25\% in the total count MAE, achieves superior detection accuracy and sets a new solid state-of-the-art result across all low-shot counting setups.
DAVE -- A Detect-and-Verify Paradigm for Low-Shot Counting
Apr 25, 2024Low-shot counters estimate the number of objects corresponding to a selected category, based on only few or no exemplars annotated in the image. The current state-of-the-art estimates the total counts as the sum over the object location density map, but does not provide individual object locations and sizes, which are crucial for many applications. This is addressed by detection-based counters, which, however fall behind in the total count accuracy. Furthermore, both approaches tend to overestimate the counts in the presence of other object classes due to many false positives. We propose DAVE, a low-shot counter based on a detect-and-verify paradigm, that avoids the aforementioned issues by first generating a high-recall detection set and then verifying the detections to identify and remove the outliers. This jointly increases the recall and precision, leading to accurate counts. DAVE outperforms the top density-based counters by ~20% in the total count MAE, it outperforms the most recent detection-based counter by ~20% in detection quality and sets a new state-of-the-art in zero-shot as well as text-prompt-based counting.
A Discriminative Single-Shot Segmentation Network for Visual Object Tracking
Dec 27, 2021



Template-based discriminative trackers are currently the dominant tracking paradigm due to their robustness, but are restricted to bounding box tracking and a limited range of transformation models, which reduces their localization accuracy. We propose a discriminative single-shot segmentation tracker -- D3S2, which narrows the gap between visual object tracking and video object segmentation. A single-shot network applies two target models with complementary geometric properties, one invariant to a broad range of transformations, including non-rigid deformations, the other assuming a rigid object to simultaneously achieve robust online target segmentation. The overall tracking reliability is further increased by decoupling the object and feature scale estimation. Without per-dataset finetuning, and trained only for segmentation as the primary output, D3S2 outperforms all published trackers on the recent short-term tracking benchmark VOT2020 and performs very close to the state-of-the-art trackers on the GOT-10k, TrackingNet, OTB100 and LaSoT. D3S2 outperforms the leading segmentation tracker SiamMask on video object segmentation benchmarks and performs on par with top video object segmentation algorithms.
DAL -- A Deep Depth-aware Long-term Tracker
Dec 02, 2019

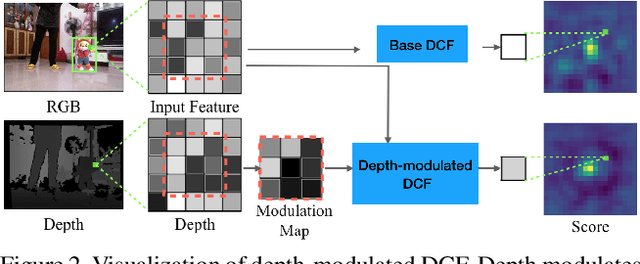
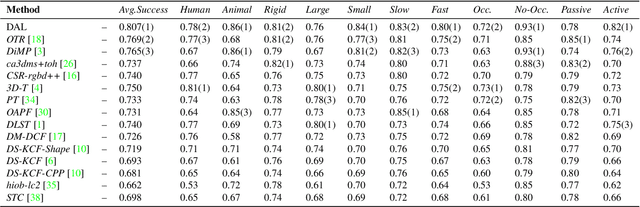
The best RGBD trackers provide high accuracy but are slow to run. On the other hand, the best RGB trackers are fast but clearly inferior on the RGBD datasets. In this work, we propose a deep depth-aware long-term tracker that achieves state-of-the-art RGBD tracking performance and is fast to run. We reformulate deep discriminative correlation filter (DCF) to embed the depth information into deep features. Moreover, the same depth-aware correlation filter is used for target re-detection. Comprehensive evaluations show that the proposed tracker achieves state-of-the-art performance on the Princeton RGBD, STC, and the newly-released CDTB benchmarks and runs 20 fps.
D3S -- A Discriminative Single Shot Segmentation Tracker
Nov 20, 2019

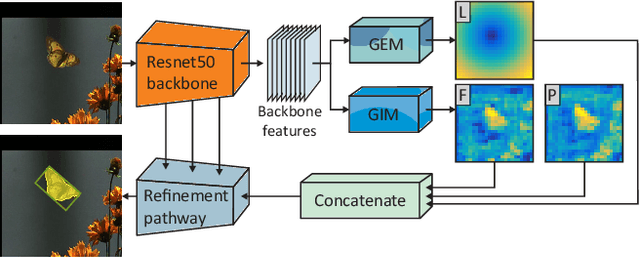

Template-based discriminative trackers are currently the dominant tracking paradigm due to their robustness, but are restricted to bounding box tracking and a limited range of transformation models, which reduces their localization accuracy. We propose a discriminative single-shot segmentation tracker - D3S, which narrows the gap between visual object tracking and video object segmentation. A single-shot network applies two target models with complementary geometric properties, one invariant to a broad range of transformations, including non-rigid deformations, the other assuming a rigid object to simultaneously achieve high robustness and online target segmentation. Without per-dataset finetuning and trained only for segmentation as the primary output, D3S outperforms all trackers on VOT2016, VOT2018 and GOT-10k benchmarks and performs close to the state-of-the-art trackers on the TrackingNet. D3S outperforms the leading segmentation tracker SiamMask on video object segmentation benchmark and performs on par with top video object segmentation algorithms, while running an order of magnitude faster, close to real-time.
CDTB: A Color and Depth Visual Object Tracking Dataset and Benchmark
Jul 01, 2019


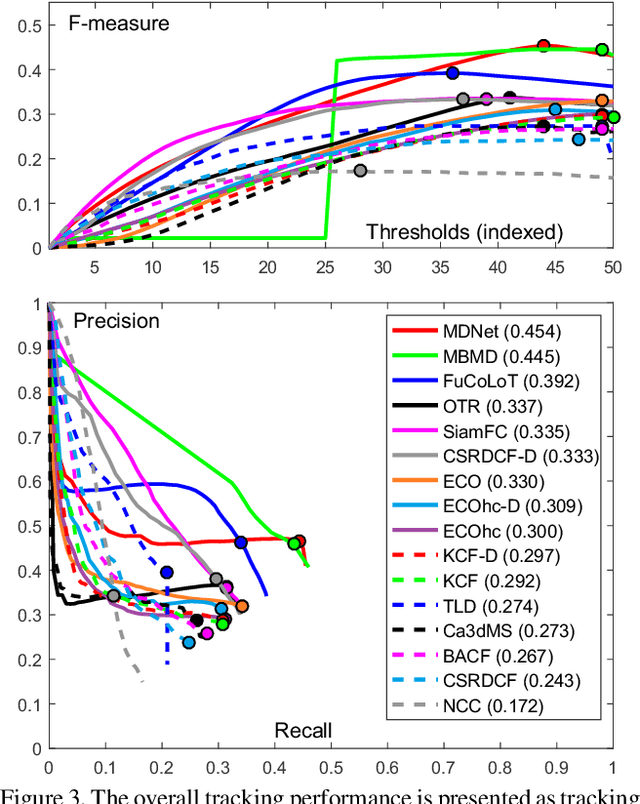
A long-term visual object tracking performance evaluation methodology and a benchmark are proposed. Performance measures are designed by following a long-term tracking definition to maximize the analysis probing strength. The new measures outperform existing ones in interpretation potential and in better distinguishing between different tracking behaviors. We show that these measures generalize the short-term performance measures, thus linking the two tracking problems. Furthermore, the new measures are highly robust to temporal annotation sparsity and allow annotation of sequences hundreds of times longer than in the current datasets without increasing manual annotation labor. A new challenging dataset of carefully selected sequences with many target disappearances is proposed. A new tracking taxonomy is proposed to position trackers on the short-term/long-term spectrum. The benchmark contains an extensive evaluation of the largest number of long-term tackers and comparison to state-of-the-art short-term trackers. We analyze the influence of tracking architecture implementations to long-term performance and explore various re-detection strategies as well as influence of visual model update strategies to long-term tracking drift. The methodology is integrated in the VOT toolkit to automate experimental analysis and benchmarking and to facilitate future development of long-term trackers.
Performance Evaluation Methodology for Long-Term Visual Object Tracking
Jun 19, 2019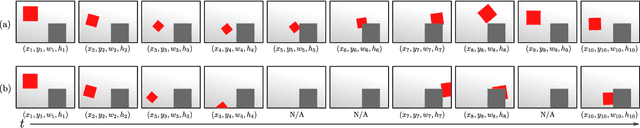
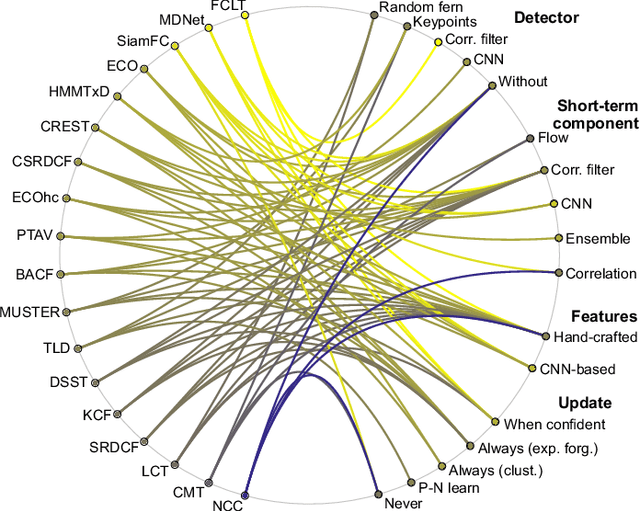
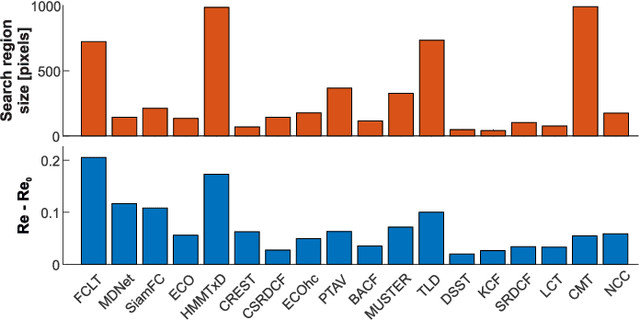
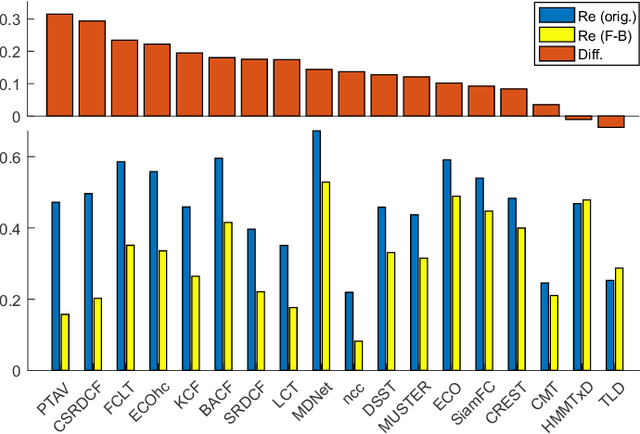
A long-term visual object tracking performance evaluation methodology and a benchmark are proposed. Performance measures are designed by following a long-term tracking definition to maximize the analysis probing strength. The new measures outperform existing ones in interpretation potential and in better distinguishing between different tracking behaviors. We show that these measures generalize the short-term performance measures, thus linking the two tracking problems. Furthermore, the new measures are highly robust to temporal annotation sparsity and allow annotation of sequences hundreds of times longer than in the current datasets without increasing manual annotation labor. A new challenging dataset of carefully selected sequences with many target disappearances is proposed. A new tracking taxonomy is proposed to position trackers on the short-term/long-term spectrum. The benchmark contains an extensive evaluation of the largest number of long-term tackers and comparison to state-of-the-art short-term trackers. We analyze the influence of tracking architecture implementations to long-term performance and explore various re-detection strategies as well as influence of visual model update strategies to long-term tracking drift. The methodology is integrated in the VOT toolkit to automate experimental analysis and benchmarking and to facilitate future development of long-term trackers.
Now you see me: evaluating performance in long-term visual tracking
Apr 19, 2018


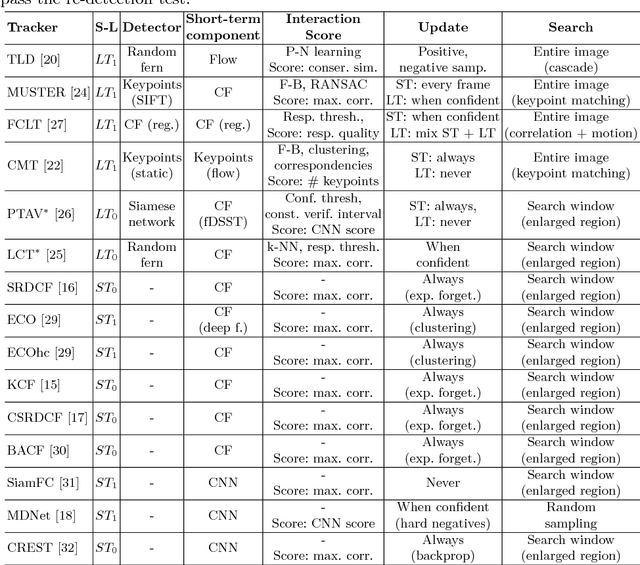
We propose a new long-term tracking performance evaluation methodology and present a new challenging dataset of carefully selected sequences with many target disappearances. We perform an extensive evaluation of six long-term and nine short-term state-of-the-art trackers, using new performance measures, suitable for evaluating long-term tracking - tracking precision, recall and F-score. The evaluation shows that a good model update strategy and the capability of image-wide re-detection are critical for long-term tracking performance. We integrated the methodology in the VOT toolkit to automate experimental analysis and benchmarking and to facilitate the development of long-term trackers.
Discriminative Correlation Filter with Channel and Spatial Reliability
Jan 17, 2018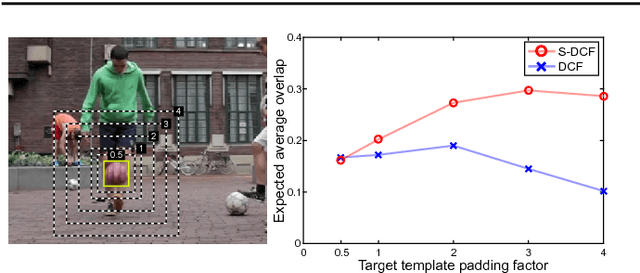



Short-term tracking is an open and challenging problem for which discriminative correlation filters (DCF) have shown excellent performance. We introduce the channel and spatial reliability concepts to DCF tracking and provide a novel learning algorithm for its efficient and seamless integration in the filter update and the tracking process. The spatial reliability map adjusts the filter support to the part of the object suitable for tracking. This both allows to enlarge the search region and improves tracking of non-rectangular objects. Reliability scores reflect channel-wise quality of the learned filters and are used as feature weighting coefficients in localization. Experimentally, with only two simple standard features, HoGs and Colornames, the novel CSR-DCF method -- DCF with Channel and Spatial Reliability -- achieves state-of-the-art results on VOT 2016, VOT 2015 and OTB100. The CSR-DCF runs in real-time on a CPU.