 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3S -- A Discriminative Single Shot Segmentation Tracker
Paper and Code


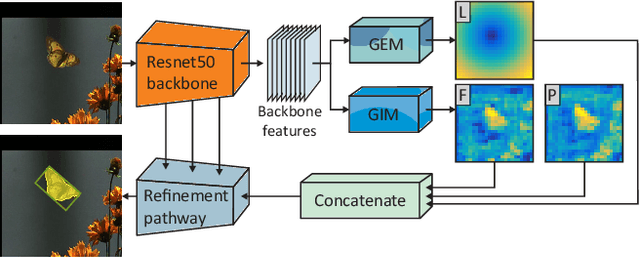

Template-based discriminative trackers are currently the dominant tracking paradigm due to their robustness, but are restricted to bounding box tracking and a limited range of transformation models, which reduces their localization accuracy. We propose a discriminative single-shot segmentation tracker - D3S, which narrows the gap between visual object tracking and video object segmentation. A single-shot network applies two target models with complementary geometric properties, one invariant to a broad range of transformations, including non-rigid deformations, the other assuming a rigid object to simultaneously achieve high robustness and online target segmentation. Without per-dataset finetuning and trained only for segmentation as the primary output, D3S outperforms all trackers on VOT2016, VOT2018 and GOT-10k benchmarks and performs close to the state-of-the-art trackers on the TrackingNet. D3S outperforms the leading segmentation tracker SiamMask on video object segmentation benchmark and performs on par with top video object segmentation algorithms, while running an order of magnitude faster, close to real-time.