 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Vehicle Detection in Satellite Video
Apr 14, 2022



This work presents a deep learning approach for vehicle detection in satellite video. Vehicle detection is perhaps impossible in single EO satellite images due to the tininess of vehicles (4-10 pixel) and their similarity to the background. Instead, we consider satellite video which overcomes the lack of spatial information by temporal consistency of vehicle movement. A new spatiotemporal model of a compact $3 \times 3$ convolutional, neural network is proposed which neglects pooling layers and uses leaky ReLUs. Then we use a reformulation of the output heatmap including Non-Maximum-Suppression (NMS) for the final segmentation. Empirical results on two new annotated satellite videos reconfirm the applicability of this approach for vehicle detection. They more importantly indicate that pre-training on WAMI data and then fine-tuning on few annotated video frames for a new video is sufficient. In our experiment only five annotated images yield a $F_1$ score of 0.81 on a new video showing more complex traffic patterns than the Las Vegas video. Our best result on Las Vegas is a $F_1$ score of 0.87 which makes the proposed approach a leading method for this benchmark.
The Problem of Fragmented Occlusion in Object Detection
Apr 27, 2020



Object detection in natural environments is still a very challenging task, even though deep learning has brought a tremendous improvement in performance over the last years. A fundamental problem of object detection based on deep learning is that neither the training data nor the suggested models are intended for the challenge of fragmented occlusion. Fragmented occlusion is much more challenging than ordinary partial occlusion and occurs frequently in natural environments such as forests. A motivating example of fragmented occlusion is object detection through foliage which is an essential requirement in green border surveillance. This paper presents an analysis of state-of-the-art detectors with imagery of green borders and proposes to train Mask R-CNN on new training data which captures explicitly the problem of fragmented occlusion. The results show clear improvements of Mask R-CNN with this new training strategy (also against other detectors) for data showing slight fragmented occlusion.
On Learning Vehicle Detection in Satellite Video
Jan 29, 2020
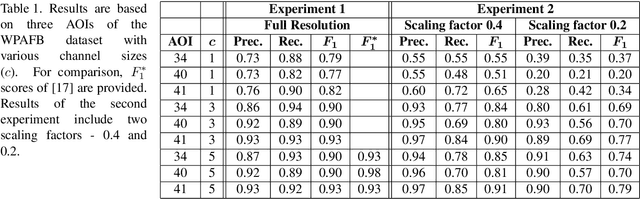

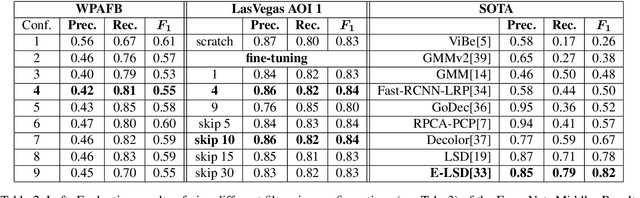
Vehicle detection in aerial and satellite images is still challenging due to their tiny appearance in pixels compared to the overall size of remote sensing imagery. Classical methods of object detection very often fail in this scenario due to violation of implicit assumptions made such as rich texture, small to moderate ratios between image size and object size. Satellite video is a very new modality which introduces temporal consistency as inductive bias. Approaches for vehicle detection in satellite video use either background subtraction, frame differencing or subspace methods showing moderate performance (0.26 - 0.82 $F_1$ score). This work proposes to apply recent work on deep learning for wide-area motion imagery (WAMI) on satellite video. We show in a first approach comparable results (0.84 $F_1$) on Planet's SkySat-1 LasVegas video with room for further improvement.
An In-Depth Analysis of Visual Tracking with Siamese Neural Networks
Aug 02, 2018
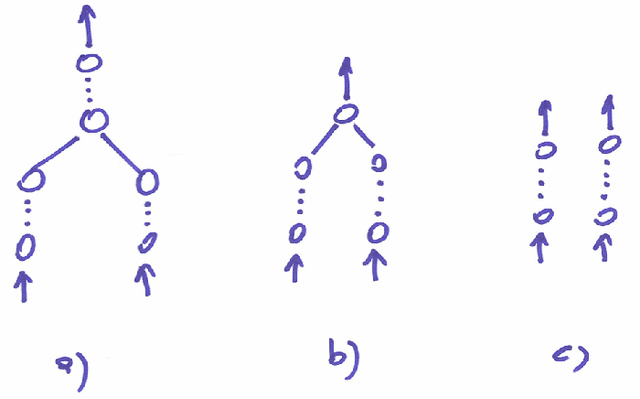
This survey presents a deep analysis of the learning and inference capabilities in nine popular trackers. It is neither intended to study the whole literature nor is it an attempt to review all kinds of neural networks proposed for visual tracking. We focus instead on Siamese neural networks which are a promising starting point for studying the challenging problem of tracking. These networks integrate efficiently feature learning and the temporal matching and have so far shown state-of-the-art performance. In particular, the branches of Siamese networks, their layers connecting these branches, specific aspects of training and the embedding of these networks into the tracker are highlighted. Quantitative results from existing papers are compared with the conclusion that the current evaluation methodology shows problems with the reproducibility and the comparability of results. The paper proposes a novel Lisp-like formalism for a better comparison of trackers. This assumes a certain functional design and functional decomposition of trackers. The paper tries to give foundation for tracker design by a formulation of the problem based on the theory of machine learning and by the interpretation of a tracker as a decision function. The work concludes with promising lines of research and suggests future work.
A Novel Performance Evaluation Methodology for Single-Target Trackers
Jan 08, 2016
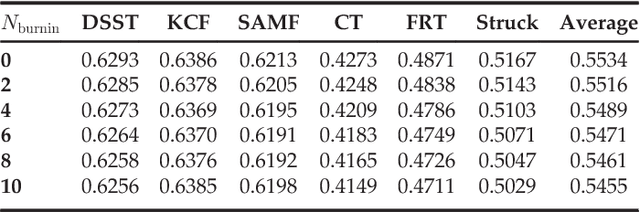
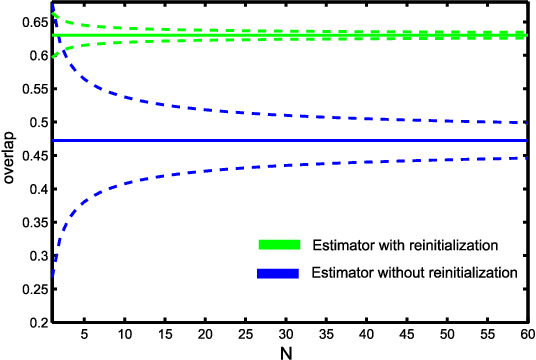
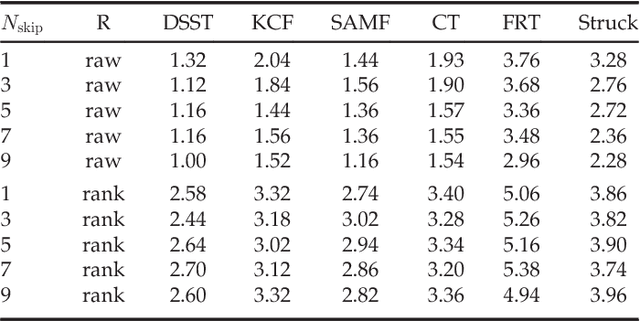
This paper addresses the problem of single-target tracker performance evaluation. We consider the performance measures, the dataset and the evaluation system to be the most important components of tracker evaluation and propose requirements for each of them. The requirements are the basis of a new evaluation methodology that aims at a simple and easily interpretable tracker comparison. The ranking-based methodology addresses tracker equivalence in terms of statistical significance and practical differences. A fully-annotated dataset with per-frame annotations with several visual attributes is introduced. The diversity of its visual properties is maximized in a novel way by clustering a large number of videos according to their visual attributes. This makes it the most sophistically constructed and annotated dataset to date. A multi-platform evaluation system allowing easy integration of third-party trackers is presented as well. The proposed evaluation methodology was tested on the VOT2014 challenge on the new dataset and 38 trackers, making it the largest benchmark to date. Most of the tested trackers are indeed state-of-the-art since they outperform the standard baselines, resulting in a highly-challenging benchmark. An exhaustive analysis of the dataset from the perspective of tracking difficulty is carried out. To facilitate tracker comparison a new performance visualization technique is proposed.