 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSE-NeRF: Learning Sensor Modeling Errors for Deblured Neural Radiance Fields with RGB-Event Stereo
Sep 09, 2024

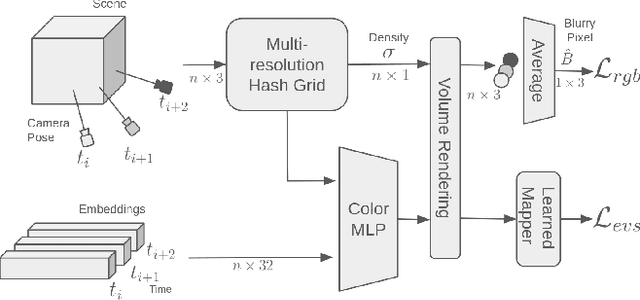

We present a method for reconstructing a clear Neural Radiance Field (NeRF) even with fast camera motions. To address blur artifacts, we leverage both (blurry) RGB images and event camera data captured in a binocular configuration. Importantly, when reconstructing our clear NeRF, we consider the camera modeling imperfections that arise from the simple pinhole camera model as learned embeddings for each camera measurement, and further learn a mapper that connects event camera measurements with RGB data. As no previous dataset exists for our binocular setting, we introduce an event camera dataset with captures from a 3D-printed stereo configuration between RGB and event cameras. Empirically, we evaluate our introduced dataset and EVIMOv2 and show that our method leads to improved reconstructions. Our code and dataset are available at https://github.com/ubc-vision/LSENeRF.
MonoCap: Monocular Human Motion Capture using a CNN Coupled with a Geometric Prior
Mar 09, 2018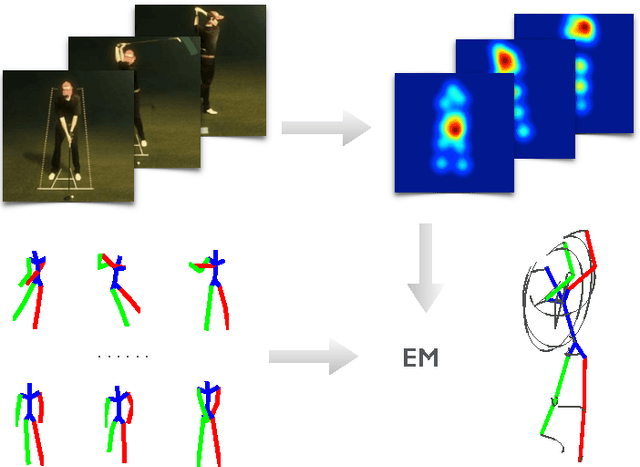



Recovering 3D full-body human pose is a challenging problem with many applications. It has been successfully addressed by motion capture systems with body worn markers and multiple cameras. In this paper, we address the more challenging case of not only using a single camera but also not leveraging markers: going directly from 2D appearance to 3D geometry. Deep learning approaches have shown remarkable abilities to discriminatively learn 2D appearance features. The missing piece is how to integrate 2D, 3D and temporal information to recover 3D geometry and account for the uncertainties arising from the discriminative model. We introduce a novel approach that treats 2D joint locations as latent variables whose uncertainty distributions are given by a deep fully convolutional neural network. The unknown 3D poses are modeled by a sparse representation and the 3D parameter estimates are realized via an Expectation-Maximization algorithm, where it is shown that the 2D joint location uncertainties can be conveniently marginalized out during inference. Extensive evaluation on benchmark datasets shows that the proposed approach achieves greater accuracy over state-of-the-art baselines. Notably, the proposed approach does not require synchronized 2D-3D data for training and is applicable to "in-the-wild" images, which is demonstrated with the MPII dataset.