 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGNet:Edge Guidance Network for Salient Object Detection
Aug 22, 2019
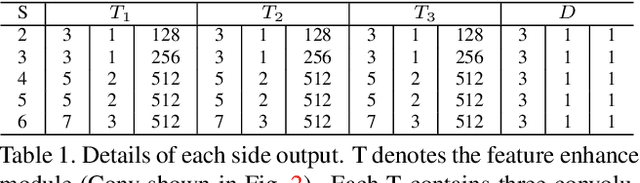
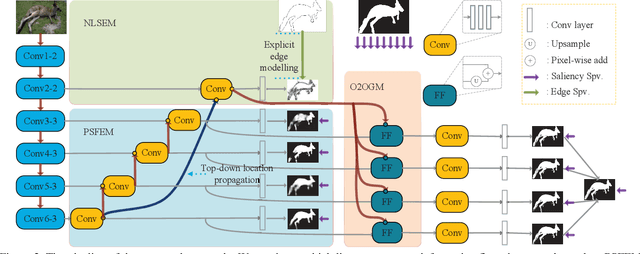
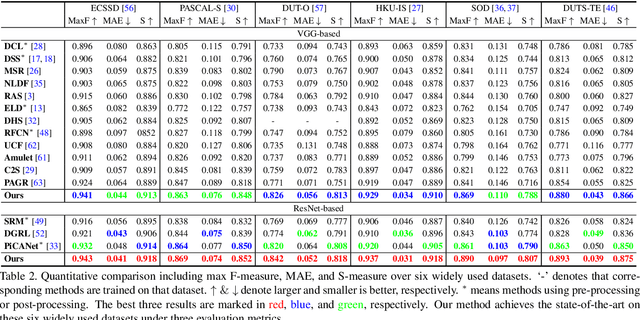
Fully convolutional neural networks (FCNs) have shown their advantages in the salient object detection task. However, most existing FCNs-based methods still suffer from coarse object boundaries. In this paper, to solve this problem, we focus on the complementarity between salient edge information and salient object information. Accordingly, we present an edge guidance network (EGNet) for salient object detection with three steps to simultaneously model these two kinds of complementary information in a single network. In the first step, we extract the salient object features by a progressive fusion way. In the second step, we integrate the local edge information and global location information to obtain the salient edge features. Finally, to sufficiently leverage these complementary features, we couple the same salient edge features with salient object features at various resolutions. Benefiting from the rich edge information and location information in salient edge features, the fused features can help locate salient objects, especially their boundaries more accurately. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art methods on six widely used datasets without any pre-processing and post-processing. The source code is available at http: //mmcheng.net/egnet/.
Rethinking RGB-D Salient Object Detection: Models, Datasets, and Large-Scale Benchmarks
Jul 15, 2019



The use of RGB-D information for salient object detection has been explored in recent years. However, relatively few efforts have been spent in modeling salient object detection over real-world human activity scenes with RGB-D. In this work, we fill the gap by making the following contributions to RGB-D salient object detection. First, we carefully collect a new salient person (SIP) dataset, which consists of 1K high-resolution images that cover diverse real-world scenes from various viewpoints, poses, occlusion, illumination, and background. Second, we conduct a large-scale and so far the most comprehensive benchmark comparing contemporary methods, which has long been missing in the area and can serve as a baseline for future research. We systematically summarized 31 popular models, evaluated 17 state-of-the-art methods over seven datasets with totally about 91K images. Third, we propose a simple baseline architecture, called Deep Depth-Depurator Network (D3Net). It consists of a depth depurator unit and a feature learning module, performing initial low-quality depth map filtering and cross-modal feature learning respectively. These components form a nested structure and are elaborately designed to be learned jointly. D3Net exceeds the performance of any prior contenders across five metrics considered, thus serves as a strong baseline to advance the research frontier. We also demonstrate that D3Net can be used to efficiently extract salient person masks from the real scenes, enabling effective background changed book cover application with 20 fps on a single GPU. All the saliency maps, our new SIP dataset, baseline model, and evaluation tools are made publicly available at https://github.com/DengPingFan/D3NetBenchmark.