 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSQ: Growing Mixed-Precision Quantization Scheme with Bi-level Continuous Sparsification
Dec 06, 2022Mixed-precision quantization has been widely applied on deep neural networks (DNNs) as it leads to significantly better efficiency-accuracy tradeoffs compared to uniform quantization. Meanwhile, determining the exact precision of each layer remains challenging. Previous attempts on bit-level regularization and pruning-based dynamic precision adjustment during training suffer from noisy gradients and unstable convergence. In this work, we propose Continuous Sparsification Quantization (CSQ), a bit-level training method to search for mixed-precision quantization schemes with improved stability. CSQ stabilizes the bit-level mixed-precision training process with a bi-level gradual continuous sparsification on both the bit values of the quantized weights and the bit selection in determining the quantization precision of each layer. The continuous sparsification scheme enables fully-differentiable training without gradient approximation while achieving an exact quantized model in the end.A budget-aware regularization of total model size enables the dynamic growth and pruning of each layer's precision towards a mixed-precision quantization scheme of the desired size. Extensive experiments show CSQ achieves better efficiency-accuracy tradeoff than previous methods on multiple models and datasets.
Binary Neural Networks as a general-propose compute paradigm for on-device computer vision
Feb 08, 2022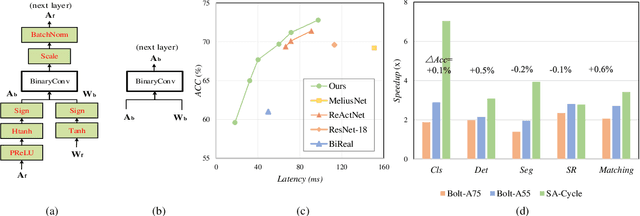

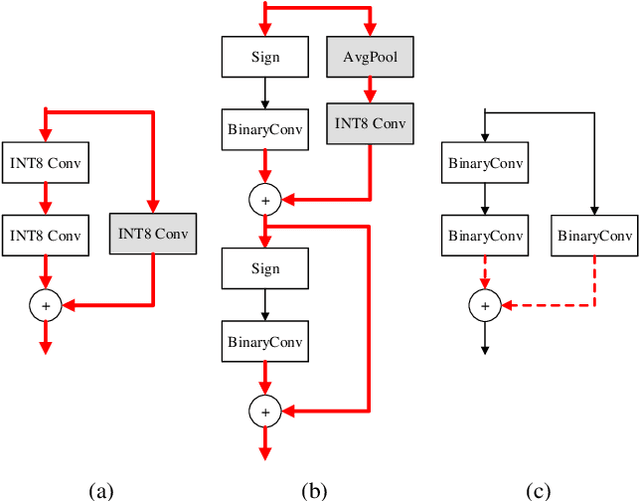
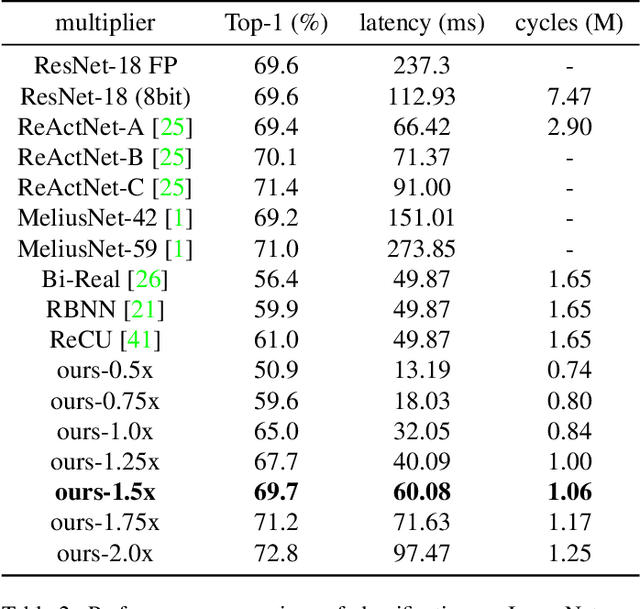
For binary neural networks (BNNs) to become the mainstream on-device computer vision algorithm, they must achieve a superior speed-vs-accuracy tradeoff than 8-bit quantization and establish a similar degree of general applicability in vision tasks. To this end, we propose a BNN framework comprising 1) a minimalistic inference scheme for hardware-friendliness, 2) an over-parameterized training scheme for high accuracy, and 3) a simple procedure to adapt to different vision tasks. The resultant framework overtakes 8-bit quantization in the speed-vs-accuracy tradeoff for classification, detection, segmentation, super-resolution and matching: our BNNs not only retain the accuracy levels of their 8-bit baselines but also showcase 1.3-2.4$\times$ faster FPS on mobile CPUs. Similar conclusions can be drawn for prototypical systolic-array-based AI accelerators, where our BNNs promise 2.8-7$\times$ fewer execution cycles than 8-bit and 2.1-2.7$\times$ fewer cycles than alternative BNN designs. These results suggest that the time for large-scale BNN adoption could be upon us.