 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Performance Inference Graph Convolutional Networks for Skeleton-Based Action Recognition
May 30, 2023



Recently, significant achievements have been made in skeleton-based human action recognition with the emergence of graph convolutional networks (GCNs). However, the state-of-the-art (SOTA) models used for this task focus on constructing more complex higher-order connections between joint nodes to describe skeleton information, which leads to complex inference processes and high computational costs, resulting in reduced model's practicality. To address the slow inference speed caused by overly complex model structures, we introduce re-parameterization and over-parameterization techniques to GCNs, and propose two novel high-performance inference graph convolutional networks, namely HPI-GCN-RP and HPI-GCN-OP. HPI-GCN-RP uses re-parameterization technique to GCNs to achieve a higher inference speed with competitive model performance. HPI-GCN-OP further utilizes over-parameterization technique to bring significant performance improvement with inference speed slightly decreased. Experimental results on the two skeleton-based action recognition datasets demonstrate the effectiveness of our approach. Our HPI-GCN-OP achieves an accuracy of 93% on the cross-subject split of the NTU-RGB+D 60 dataset, and 90.1% on the cross-subject benchmark of the NTU-RGB+D 120 dataset and is 4.5 times faster than HD-GCN at the same accuracy.
Binary Neural Networks as a general-propose compute paradigm for on-device computer vision
Feb 08, 2022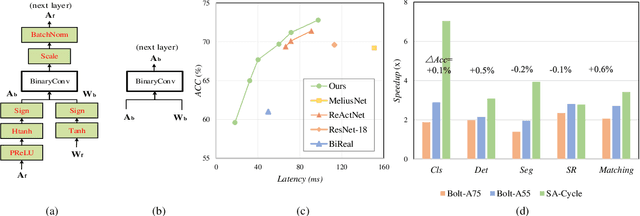

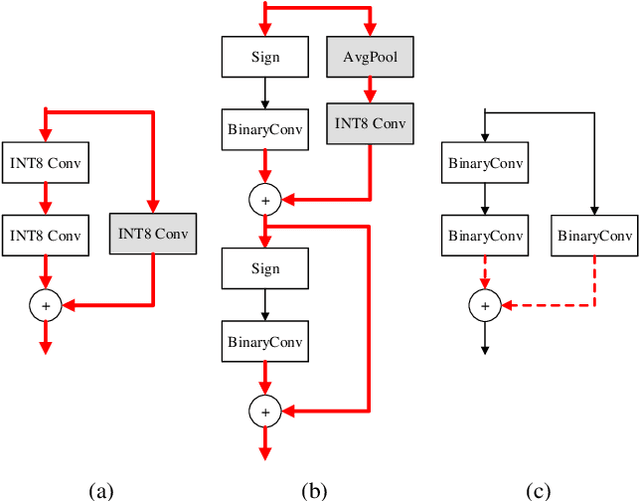
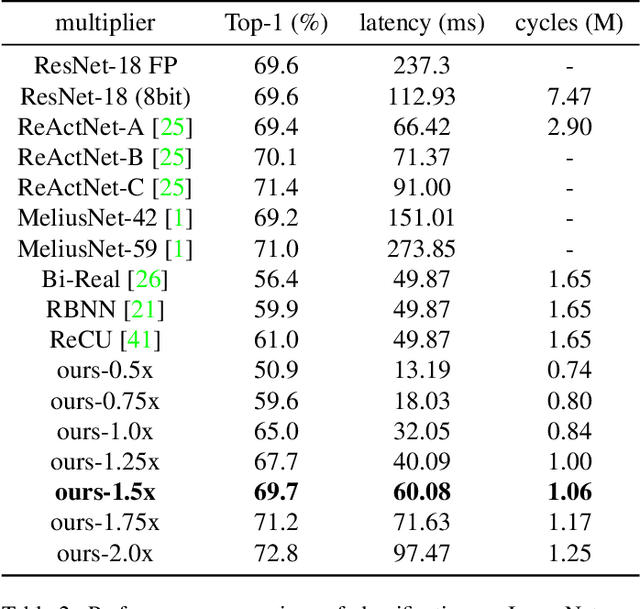
For binary neural networks (BNNs) to become the mainstream on-device computer vision algorithm, they must achieve a superior speed-vs-accuracy tradeoff than 8-bit quantization and establish a similar degree of general applicability in vision tasks. To this end, we propose a BNN framework comprising 1) a minimalistic inference scheme for hardware-friendliness, 2) an over-parameterized training scheme for high accuracy, and 3) a simple procedure to adapt to different vision tasks. The resultant framework overtakes 8-bit quantization in the speed-vs-accuracy tradeoff for classification, detection, segmentation, super-resolution and matching: our BNNs not only retain the accuracy levels of their 8-bit baselines but also showcase 1.3-2.4$\times$ faster FPS on mobile CPUs. Similar conclusions can be drawn for prototypical systolic-array-based AI accelerators, where our BNNs promise 2.8-7$\times$ fewer execution cycles than 8-bit and 2.1-2.7$\times$ fewer cycles than alternative BNN designs. These results suggest that the time for large-scale BNN adoption could be upon us.