 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Fast and Slow: Memory-Guided Mobile Video Object Detection
Paper and Code
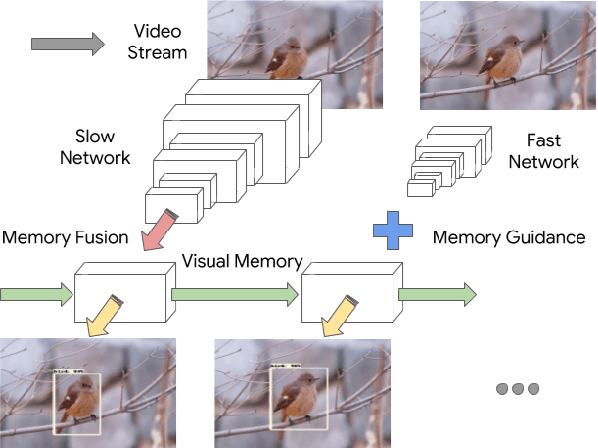
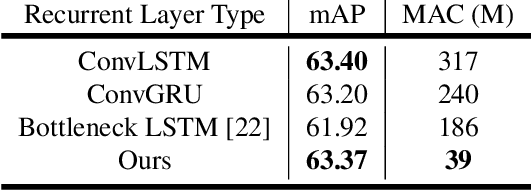
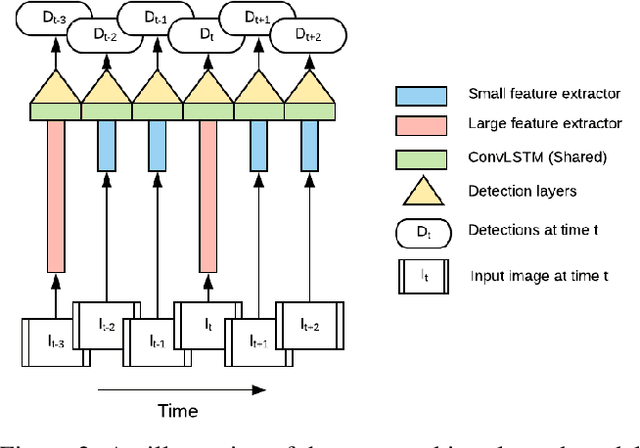
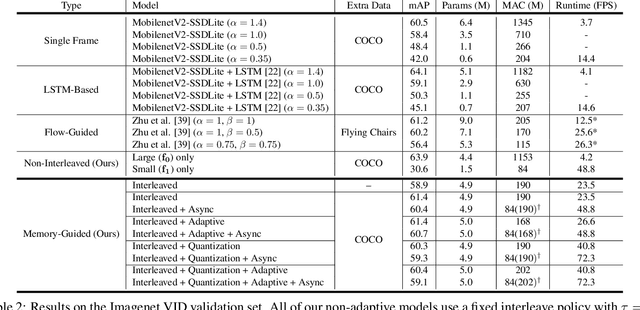
With a single eye fixation lasting a fraction of a second, the human visual system is capable of forming a rich representation of a complex environment, reaching a holistic understanding which facilitates object recognition and detection. This phenomenon is known as recognizing the "gist" of the scene and is accomplished by relying on relevant prior knowledge. This paper addresses the analogous question of whether using memory in computer vision systems can not only improve the accuracy of object detection in video streams, but also reduce the computation time. By interleaving conventional feature extractors with extremely lightweight ones which only need to recognize the gist of the scene, we show that minimal computation is required to produce accurate detections when temporal memory is present. In addition, we show that the memory contains enough information for deploying reinforcement learning algorithms to learn an adaptive inference policy. Our model achieves state-of-the-art performance among mobile methods on the Imagenet VID 2015 dataset, while running at speeds of up to 70+ FPS on a Pixel 3 phone.