 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised 4D Cardiac Motion Tracking with Spatiotemporal Optical Flow Networks
Jul 05, 2024Cardiac motion tracking from echocardiography can be used to estimate and quantify myocardial motion within a cardiac cycle. It is a cost-efficient and effective approach for assessing myocardial function. However, ultrasound imaging has the inherent characteristics of spatially low resolution and temporally random noise, which leads to difficulties in obtaining reliable annotation. Thus it is difficult to perform supervised learning for motion tracking. In addition, there is no end-to-end unsupervised method currently in the literature. This paper presents a motion tracking method where unsupervised optical flow networks are designed with spatial reconstruction loss and temporal-consistency loss. Our proposed loss functions make use of the pair-wise and temporal correlation to estimate cardiac motion from noisy background. Experiments using a synthetic 4D echocardiography dataset has shown the effectiveness of our approach, and its superiority over existing methods on both accuracy and running speed. To the best of our knowledge, this is the first work performed that uses unsupervised end-to-end deep learning optical flow network for 4D cardiac motion tracking.
Geo-distinctive Visual Element Matching for Location Estimation of Images
Jan 28, 2016



We propose an image representation and matching approach that substantially improves visual-based location estimation for images. The main novelty of the approach, called distinctive visual element matching (DVEM), is its use of representations that are specific to the query image whose location is being predicted. These representations are based on visual element clouds, which robustly capture the connection between the query and visual evidence from candidate locations. We then maximize the influence of visual elements that are geo-distinctive because they do not occur in images taken at many other locations. We carry out experiments and analysis for both geo-constrained and geo-unconstrained location estimation cases using two large-scale, publicly-available datasets: the San Francisco Landmark dataset with $1.06$ million street-view images and the MediaEval '15 Placing Task dataset with $5.6$ million geo-tagged images from Flickr. We present examples that illustrate the highly-transparent mechanics of the approach, which are based on common sense observations about the visual patterns in image collections. Our results show that the proposed method delivers a considerable performance improvement compared to the state of the art.
Learning Subclass Representations for Visually-varied Image Classification
Jan 12, 2016
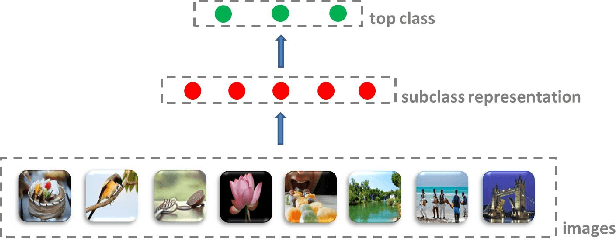
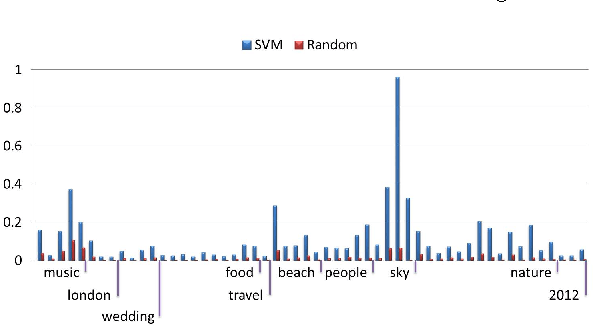
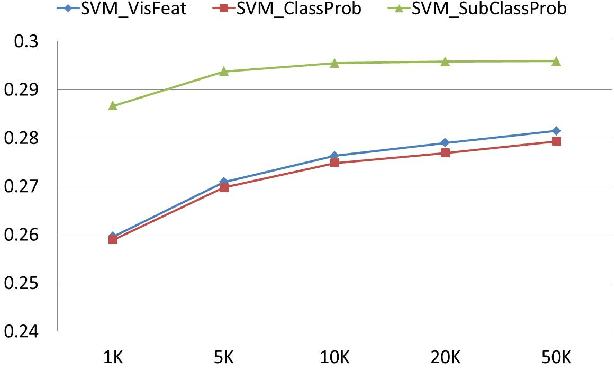
In this paper, we present a subclass-representation approach that predicts the probability of a social image belonging to one particular class. We explore the co-occurrence of user-contributed tags to find subclasses with a strong connection to the top level class. We then project each image on to the resulting subclass space to generate a subclass representation for the image. The novelty of the approach is that subclass representations make use of not only the content of the photos themselves, but also information on the co-occurrence of their tags, which determines membership in both subclasses and top-level classes. The novelty is also that the images are classified into smaller classes, which have a chance of being more visually stable and easier to model. These subclasses are used as a latent space and images are represented in this space by their probability of relatedness to all of the subclasses. In contrast to approaches directly modeling each top-level class based on the image content, the proposed method can exploit more information for visually diverse classes. The approach is evaluated on a set of $2$ million photos with 10 classes, released by the Multimedia 2013 Yahoo! Large-scale Flickr-tag Image Classification Grand Challenge. Experiments show that the proposed system delivers sound performance for visually diverse classes compared with methods that directly model top classes.