 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Recaptioning Framework to Account for Perceptual Diversity in Multilingual Vision-Language Modeling
Paper and Code
Apr 19, 2025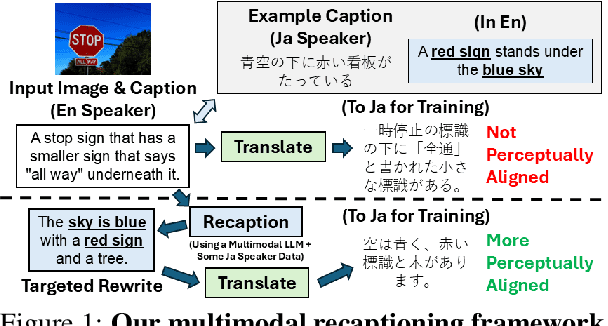
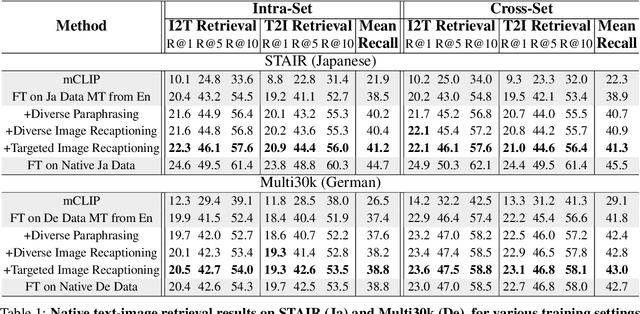


There are many ways to describe, name, and group objects when captioning an image. Differences are evident when speakers come from diverse cultures due to the unique experiences that shape perception. Machine translation of captions has pushed multilingual capabilities in vision-language models (VLMs), but data comes mainly from English speakers, indicating a perceptual bias and lack of model flexibility. In this work, we address this challenge and outline a data-efficient framework to instill multilingual VLMs with greater understanding of perceptual diversity. We specifically propose an LLM-based, multimodal recaptioning strategy that alters the object descriptions of English captions before translation. The greatest benefits are demonstrated in a targeted multimodal mechanism guided by native speaker data. By adding produced rewrites as augmentations in training, we improve on German and Japanese text-image retrieval cases studies (up to +3.5 mean recall overall, +4.7 on non-native error cases). We further propose a mechanism to analyze the specific object description differences across datasets, and we offer insights into cross-dataset and cross-language generalization.