 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Role of Context in Region-Word Alignment for Object Detection
Paper and Code
Mar 17, 2023

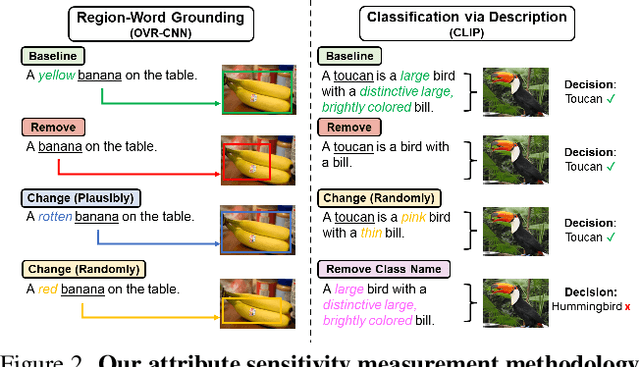

Vision-language pretraining to learn a fine-grained, region-word alignment between image-caption pairs has propelled progress in open-vocabulary object detection. We observe that region-word alignment methods are typically used in detection with respect to only object nouns, and the impact of other rich context in captions, such as attributes, is unclear. In this study, we explore how language context affects downstream object detection and propose to enhance the role of context. In particular, we show how to strategically contextualize the grounding pretraining objective for improved alignment. We further hone in on attributes as especially useful object context and propose a novel adjective and noun-based negative sampling strategy for increasing their focus in contrastive learning. Overall, our methods enhance object detection when compared to the state-of-the-art in region-word pretraining. We also highlight the fine-grained utility of an attribute-sensitive model through text-region retrieval and phrase grounding analysis.