 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAP: Evaluation of Persuasive and Creative Image Generation
Dec 10, 2024
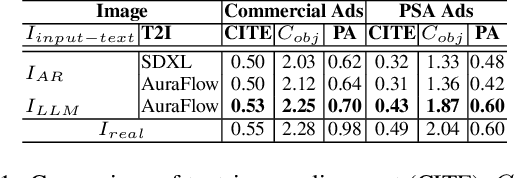
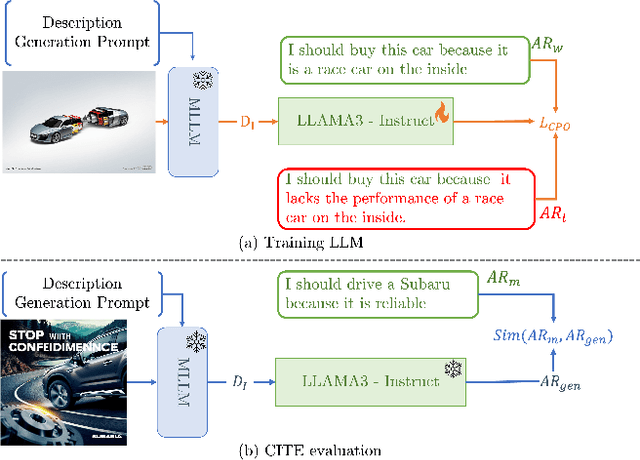
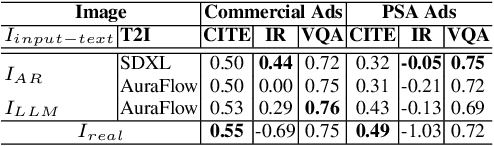
We address the task of advertisement image generation and introduce three evaluation metrics to assess Creativity, prompt Alignment, and Persuasiveness (CAP) in generated advertisement images. Despite recent advancements in Text-to-Image (T2I) generation and their performance in generating high-quality images for explicit descriptions, evaluating these models remains challenging. Existing evaluation methods focus largely on assessing alignment with explicit, detailed descriptions, but evaluating alignment with visually implicit prompts remains an open problem. Additionally, creativity and persuasiveness are essential qualities that enhance the effectiveness of advertisement images, yet are seldom measured. To address this, we propose three novel metrics for evaluating the creativity, alignment, and persuasiveness of generated images. Our findings reveal that current T2I models struggle with creativity, persuasiveness, and alignment when the input text is implicit messages. We further introduce a simple yet effective approach to enhance T2I models' capabilities in producing images that are better aligned, more creative, and more persuasive.
Benchmarking VLMs' Reasoning About Persuasive Atypical Images
Sep 16, 2024



Vision language models (VLMs) have shown strong zero-shot generalization across various tasks, especially when integrated with large language models (LLMs). However, their ability to comprehend rhetorical and persuasive visual media, such as advertisements, remains understudied. Ads often employ atypical imagery, using surprising object juxtapositions to convey shared properties. For example, Fig. 1 (e) shows a beer with a feather-like texture. This requires advanced reasoning to deduce that this atypical representation signifies the beer's lightness. We introduce three novel tasks, Multi-label Atypicality Classification, Atypicality Statement Retrieval, and Aypical Object Recognition, to benchmark VLMs' understanding of atypicality in persuasive images. We evaluate how well VLMs use atypicality to infer an ad's message and test their reasoning abilities by employing semantically challenging negatives. Finally, we pioneer atypicality-aware verbalization by extracting comprehensive image descriptions sensitive to atypical elements. Our findings reveal that: (1) VLMs lack advanced reasoning capabilities compared to LLMs; (2) simple, effective strategies can extract atypicality-aware information, leading to comprehensive image verbalization; (3) atypicality aids persuasive advertisement understanding. Code and data will be made available.
A Novel Distributed Approximate Nearest Neighbor Method for Real-time Face Recognition
May 12, 2020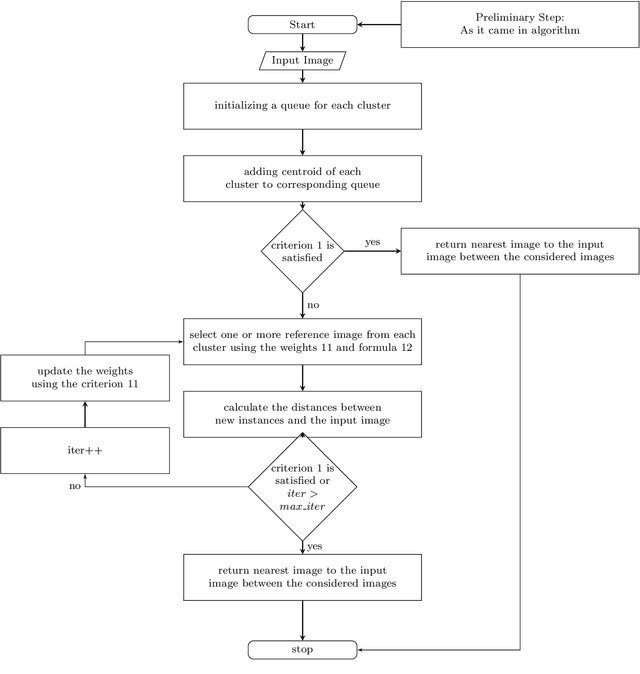

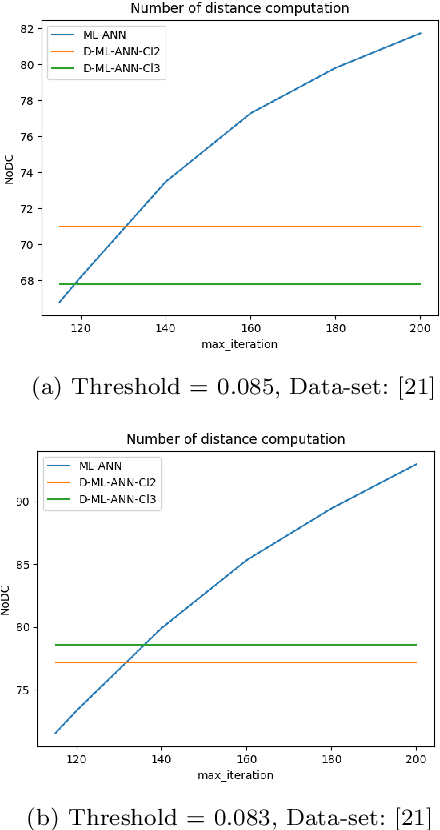
Nowadays face recognition and more generally, image recognition have many applications in the modern world and are widely used in our daily tasks. In this paper, we propose a novel distributed approximate nearest neighbor (ANN) method for real-time face recognition with a big data-set that involves a lot of classes. The proposed approach is based on using a clustering method to separate the data-set into different clusters, and specifying the importance of each cluster by defining cluster weights. Reference instances are selected from each cluster based on the cluster weights and by using a maximum likelihood approach. This process leads to a more informed selection of instances, and so enhances the performance of the algorithm. Experimental results confirm the efficiency of the proposed method and its out-performance in terms of accuracy and processing time.