 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalization of Tactile Image Generation: Reference-Free Evaluation in a Leakage-Free Setting
Mar 10, 2025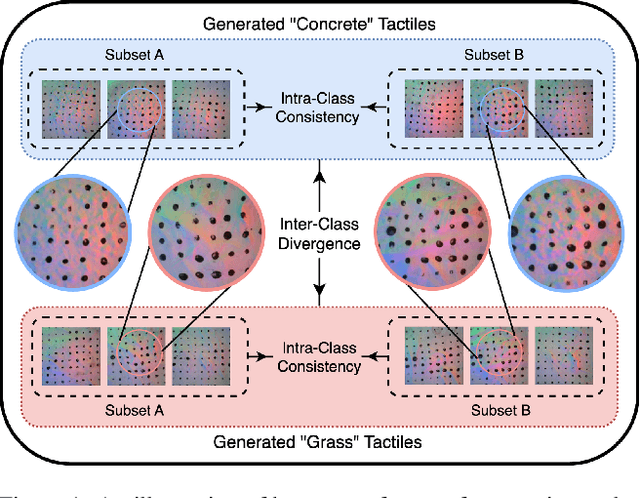
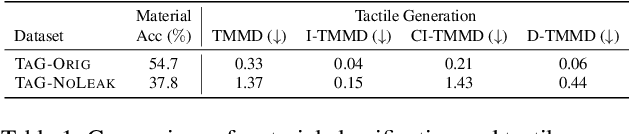
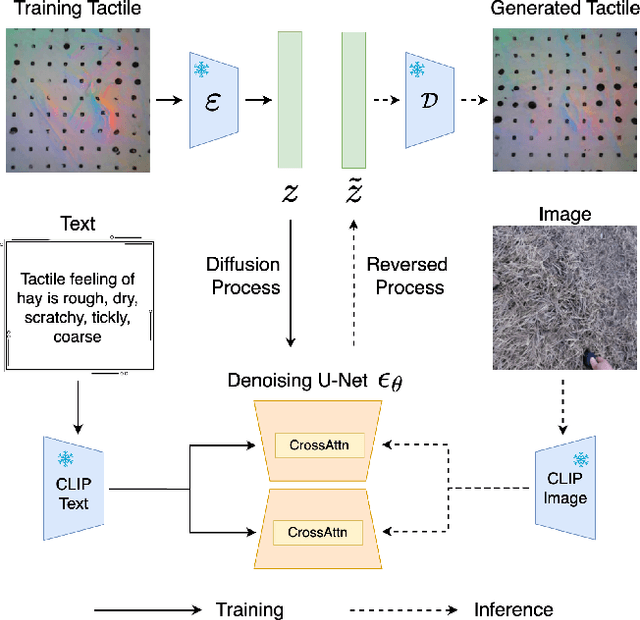

Tactile sensing, which relies on direct physical contact, is critical for human perception and underpins applications in computer vision, robotics, and multimodal learning. Because tactile data is often scarce and costly to acquire, generating synthetic tactile images provides a scalable solution to augment real-world measurements. However, ensuring robust generalization in synthesizing tactile images-capturing subtle, material-specific contact features-remains challenging. We demonstrate that overlapping training and test samples in commonly used datasets inflate performance metrics, obscuring the true generalizability of tactile models. To address this, we propose a leakage-free evaluation protocol coupled with novel, reference-free metrics-TMMD, I-TMMD, CI-TMMD, and D-TMMD-tailored for tactile generation. Moreover, we propose a vision-to-touch generation method that leverages text as an intermediate modality by incorporating concise, material-specific descriptions during training to better capture essential tactile features. Experiments on two popular visuo-tactile datasets, Touch and Go and HCT, show that our approach achieves superior performance and enhanced generalization in a leakage-free setting.
Integrating Audio Narrations to Strengthen Domain Generalization in Multimodal First-Person Action Recognition
Sep 15, 2024
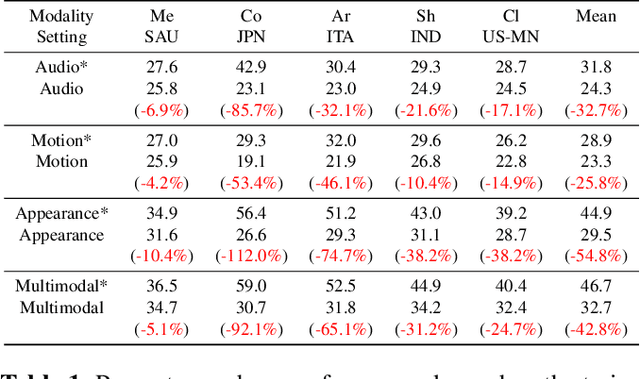
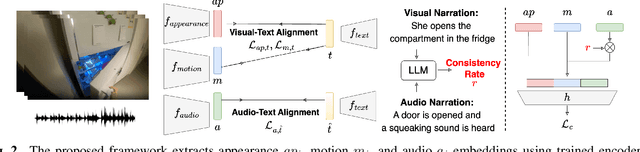

First-person activity recognition is rapidly growing due to the widespread use of wearable cameras but faces challenges from domain shifts across different environments, such as varying objects or background scenes. We propose a multimodal framework that improves domain generalization by integrating motion, audio, and appearance features. Key contributions include analyzing the resilience of audio and motion features to domain shifts, using audio narrations for enhanced audio-text alignment, and applying consistency ratings between audio and visual narrations to optimize the impact of audio in recognition during training. Our approach achieves state-of-the-art performance on the ARGO1M dataset, effectively generalizing across unseen scenarios and locations.
Enhancing Weakly-Supervised Object Detection on Static Images through (Hallucinated) Motion
Sep 15, 2024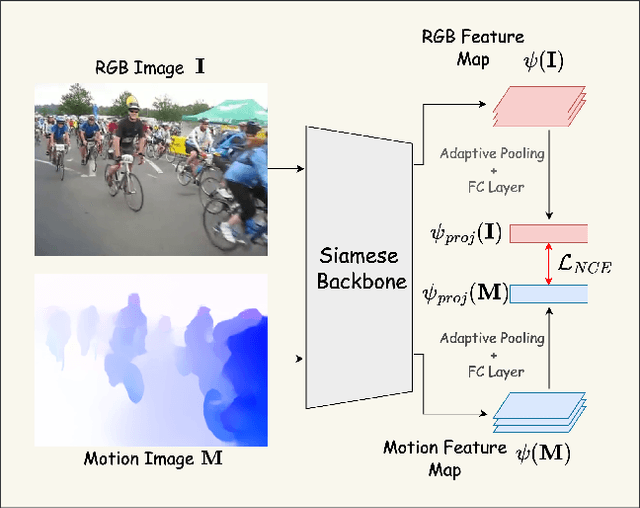
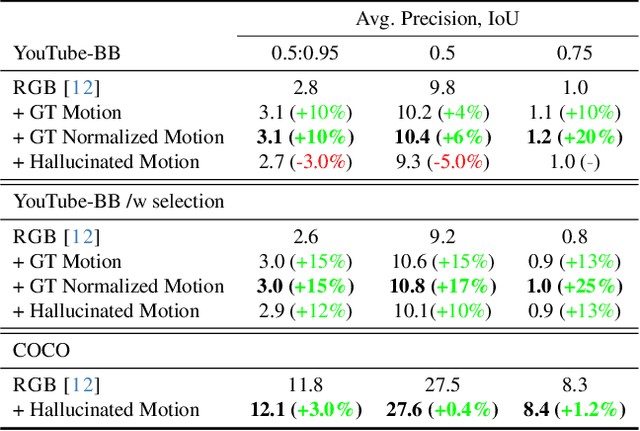


While motion has garnered attention in various tasks, its potential as a modality for weakly-supervised object detection (WSOD) in static images remains unexplored. Our study introduces an approach to enhance WSOD methods by integrating motion information. This method involves leveraging hallucinated motion from static images to improve WSOD on image datasets, utilizing a Siamese network for enhanced representation learning with motion, addressing camera motion through motion normalization, and selectively training images based on object motion. Experimental validation on the COCO and YouTube-BB datasets demonstrates improvements over a state-of-the-art method.
Boosting Weakly Supervised Object Detection using Fusion and Priors from Hallucinated Depth
Mar 20, 2023

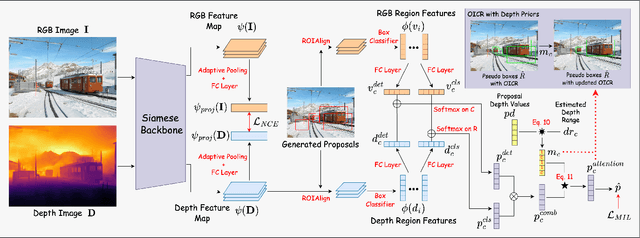

Despite recent attention and exploration of depth for various tasks, it is still an unexplored modality for weakly-supervised object detection (WSOD). We propose an amplifier method for enhancing the performance of WSOD by integrating depth information. Our approach can be applied to any WSOD method based on multiple-instance learning, without necessitating additional annotations or inducing large computational expenses. Our proposed method employs a monocular depth estimation technique to obtain hallucinated depth information, which is then incorporated into a Siamese WSOD network using contrastive loss and fusion. By analyzing the relationship between language context and depth, we calculate depth priors to identify the bounding box proposals that may contain an object of interest. These depth priors are then utilized to update the list of pseudo ground-truth boxes, or adjust the confidence of per-box predictions. Our proposed method is evaluated on six datasets (COCO, PASCAL VOC, Conceptual Captions, Clipart1k, Watercolor2k, and Comic2k) by implementing it on top of two state-of-the-art WSOD methods, and we demonstrate a substantial enhancement in performance.