 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Weakly Supervised Object Detection using Fusion and Priors from Hallucinated Depth
Paper and Code
Mar 20, 2023

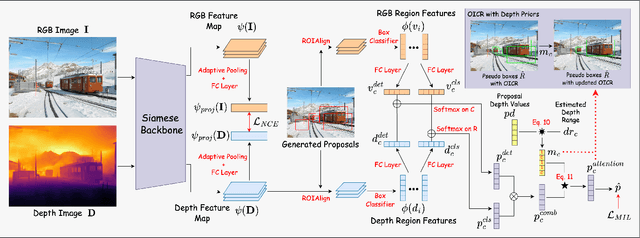

Despite recent attention and exploration of depth for various tasks, it is still an unexplored modality for weakly-supervised object detection (WSOD). We propose an amplifier method for enhancing the performance of WSOD by integrating depth information. Our approach can be applied to any WSOD method based on multiple-instance learning, without necessitating additional annotations or inducing large computational expenses. Our proposed method employs a monocular depth estimation technique to obtain hallucinated depth information, which is then incorporated into a Siamese WSOD network using contrastive loss and fusion. By analyzing the relationship between language context and depth, we calculate depth priors to identify the bounding box proposals that may contain an object of interest. These depth priors are then utilized to update the list of pseudo ground-truth boxes, or adjust the confidence of per-box predictions. Our proposed method is evaluated on six datasets (COCO, PASCAL VOC, Conceptual Captions, Clipart1k, Watercolor2k, and Comic2k) by implementing it on top of two state-of-the-art WSOD methods, and we demonstrate a substantial enhancement in performance.