 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Generative Data-Free Distillation
Paper and Code
Dec 10, 2020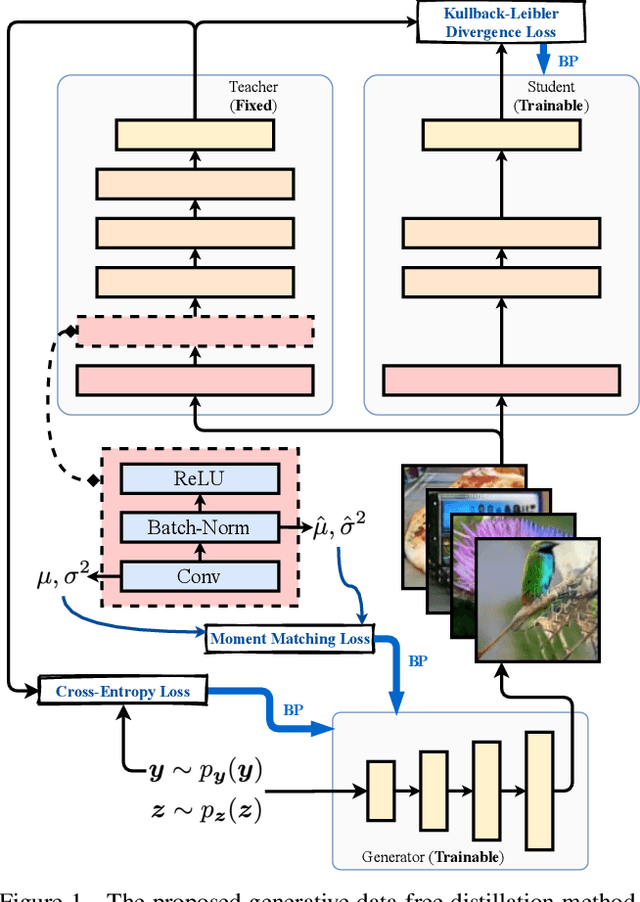
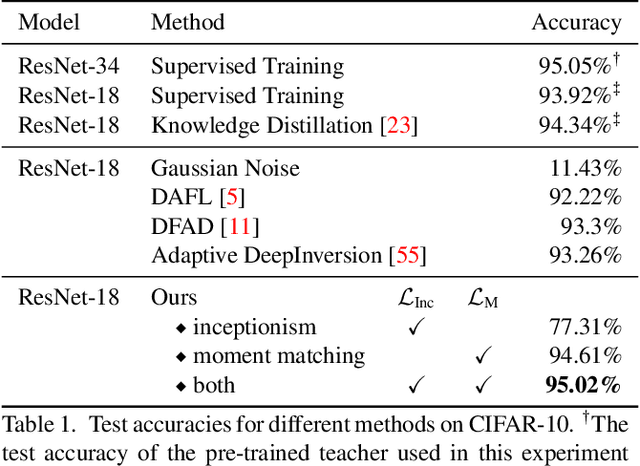

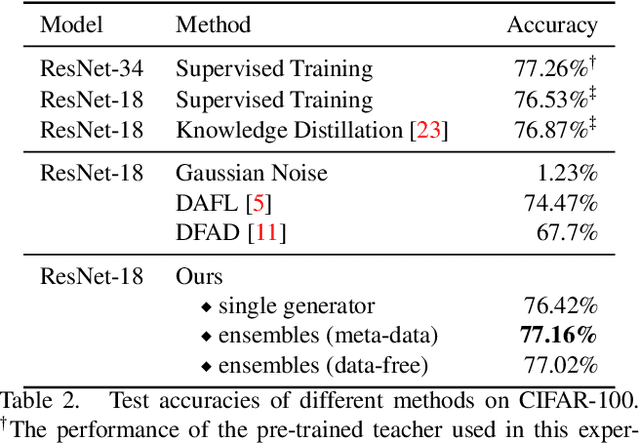
Knowledge distillation is one of the most popular and effective techniques for knowledge transfer, model compression and semi-supervised learning. Most existing distillation approaches require the access to original or augmented training samples. But this can be problematic in practice due to privacy, proprietary and availability concerns. Recent work has put forward some methods to tackle this problem, but they are either highly time-consuming or unable to scale to large datasets. To this end, we propose a new method to train a generative image model by leveraging the intrinsic normalization layers' statistics of the trained teacher network. This enables us to build an ensemble of generators without training data that can efficiently produce substitute inputs for subsequent distillation. The proposed method pushes forward the data-free distillation performance on CIFAR-10 and CIFAR-100 to 95.02% and 77.02% respectively. Furthermore, we are able to scale it to ImageNet dataset, which to the best of our knowledge, has never been done using generative models in a data-free setting.