 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Language Agnostic Multilingual Streaming On-Device ASR System
Aug 29, 2022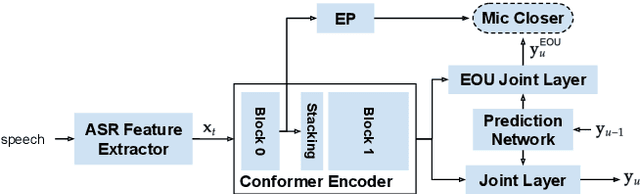
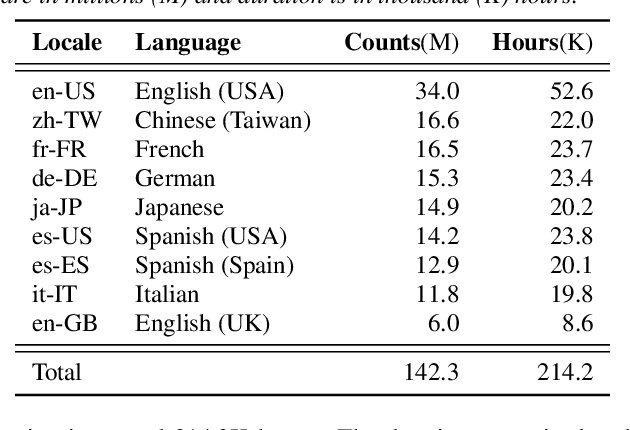
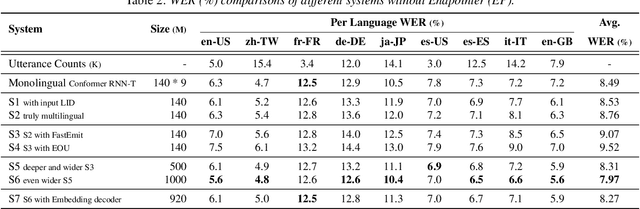
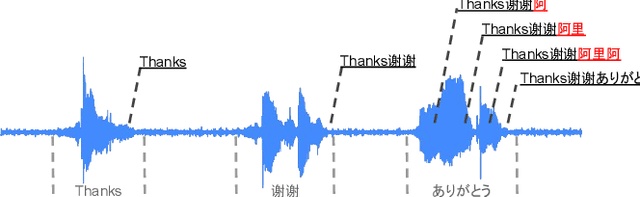
On-device end-to-end (E2E) models have shown improvements over a conventional model on English Voice Search tasks in both quality and latency. E2E models have also shown promising results for multilingual automatic speech recognition (ASR). In this paper, we extend our previous capacity solution to streaming applications and present a streaming multilingual E2E ASR system that runs fully on device with comparable quality and latency to individual monolingual models. To achieve that, we propose an Encoder Endpointer model and an End-of-Utterance (EOU) Joint Layer for a better quality and latency trade-off. Our system is built in a language agnostic manner allowing it to natively support intersentential code switching in real time. To address the feasibility concerns on large models, we conducted on-device profiling and replaced the time consuming LSTM decoder with the recently developed Embedding decoder. With these changes, we managed to run such a system on a mobile device in less than real time.
U-Net Based Multi-instance Video Object Segmentation
May 19, 2019

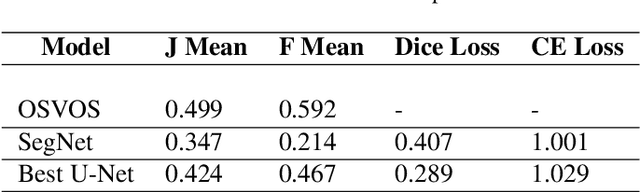

Multi-instance video object segmentation is to segment specific instances throughout a video sequence in pixel level, given only an annotated first frame. In this paper, we implement an effective fully convolutional networks with U-Net similar structure built on top of OSVOS fine-tuned layer. We use instance isolation to transform this multi-instance segmentation problem into binary labeling problem, and use weighted cross entropy loss and dice coefficient loss as our loss function. Our best model achieves F mean of 0.467 and J mean of 0.424 on DAVIS dataset, which is a comparable performance with the State-of-the-Art approach. But case analysis shows this model can achieve a smoother contour and better instance coverage, meaning it better for recall focused segmentation scenario. We also did experiments on other convolutional neural networks, including Seg-Net, Mask R-CNN, and provide insightful comparison and discussion.
Conditioning LSTM Decoder and Bi-directional Attention Based Question Answering System
May 02, 2019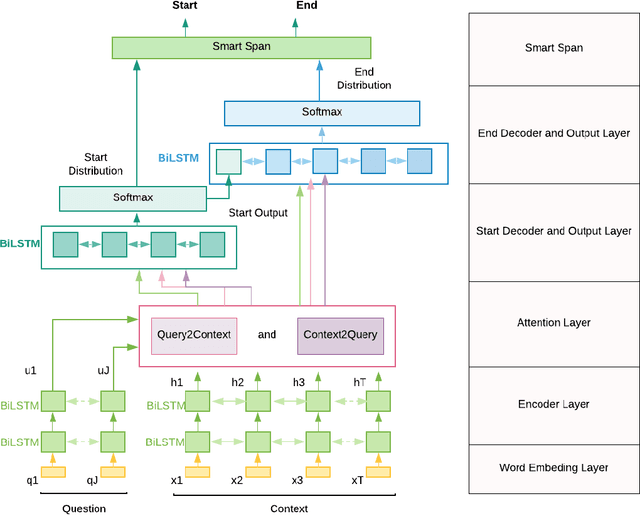


Applying neural-networks on Question Answering has gained increasing popularity in recent years. In this paper, I implemented a model with Bi-directional attention flow layer, connected with a Multi-layer LSTM encoder, connected with one start-index decoder and one conditioning end-index decoder. I introduce a new end-index decoder layer, conditioning on start-index output. The Experiment shows this has increased model performance by 15.16%. For prediction, I proposed a new smart-span equation, rewarding both short answer length and high probability in start-index and end-index, which further improved the prediction accuracy. The best single model achieves an F1 score of 73.97% and EM score of 64.95% on test set.