 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Net Based Multi-instance Video Object Segmentation
Paper and Code


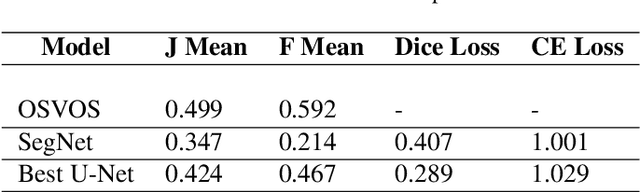

Multi-instance video object segmentation is to segment specific instances throughout a video sequence in pixel level, given only an annotated first frame. In this paper, we implement an effective fully convolutional networks with U-Net similar structure built on top of OSVOS fine-tuned layer. We use instance isolation to transform this multi-instance segmentation problem into binary labeling problem, and use weighted cross entropy loss and dice coefficient loss as our loss function. Our best model achieves F mean of 0.467 and J mean of 0.424 on DAVIS dataset, which is a comparable performance with the State-of-the-Art approach. But case analysis shows this model can achieve a smoother contour and better instance coverage, meaning it better for recall focused segmentation scenario. We also did experiments on other convolutional neural networks, including Seg-Net, Mask R-CNN, and provide insightful comparison and discussion.