 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Sign Momentum with Local Steps for Training Transformers
Nov 26, 2024Pre-training Transformer models is resource-intensive, and recent studies have shown that sign momentum is an efficient technique for training large-scale deep learning models, particularly Transformers. However, its application in distributed training or federated learning remains underexplored. This paper investigates a novel communication-efficient distributed sign momentum method with local updates. Our proposed method allows for a broad class of base optimizers for local updates, and uses sign momentum in global updates, where momentum is generated from differences accumulated during local steps. We evaluate our method on the pre-training of various GPT-2 models, and the empirical results show significant improvement compared to other distributed methods with local updates. Furthermore, by approximating the sign operator with a randomized version that acts as a continuous analog in expectation, we present an $O(1/\sqrt{T})$ convergence for one instance of the proposed method for nonconvex smooth functions.
MoE-Pruner: Pruning Mixture-of-Experts Large Language Model using the Hints from Its Router
Oct 15, 2024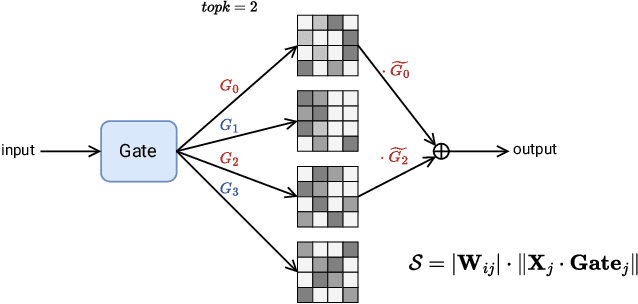

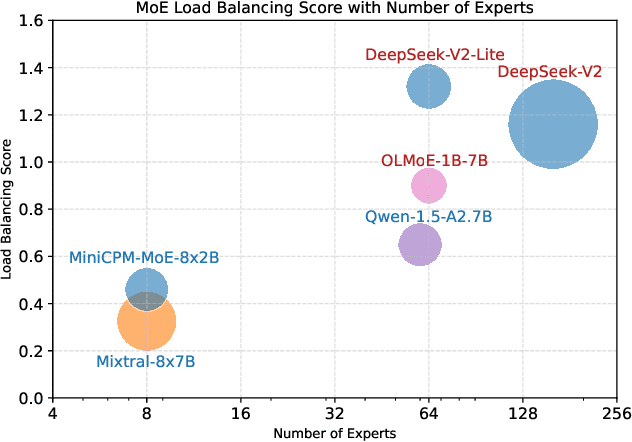
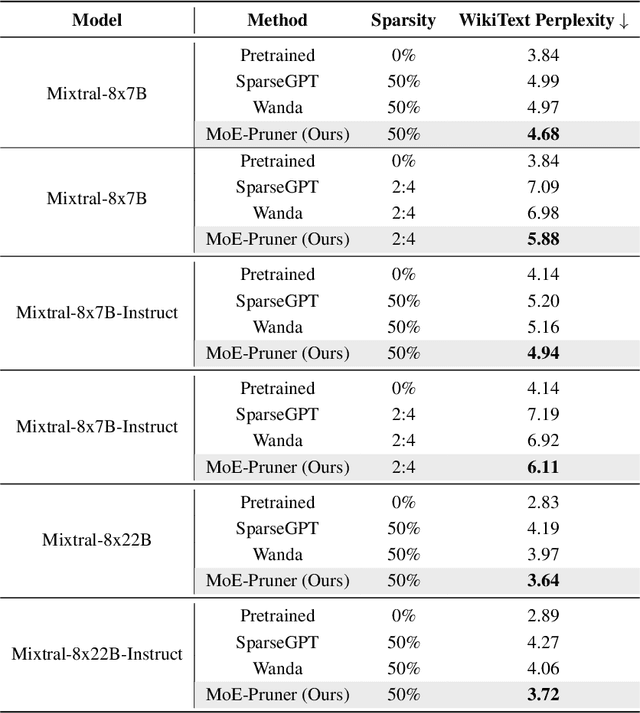
Mixture-of-Experts (MoE) architectures face challenges such as high memory consumption and redundancy in experts. Pruning MoE can reduce network weights while maintaining model performance. Motivated by the recent observation of emergent large magnitude features in Large Language Models (LLM) and MoE routing policy, we propose MoE-Pruner, a method that prunes weights with the smallest magnitudes multiplied by the corresponding input activations and router weights, on each output neuron. Our pruning method is one-shot, requiring no retraining or weight updates. We evaluate our method on Mixtral-8x7B and Mixtral-8x22B across multiple language benchmarks. Experimental results show that our pruning method significantly outperforms state-of-the-art LLM pruning methods. Furthermore, our pruned MoE models can benefit from a pretrained teacher model through expert-wise knowledge distillation, improving performance post-pruning. Experimental results demonstrate that the Mixtral-8x7B model with 50% sparsity maintains 99% of the performance of the original model after the expert-wise knowledge distillation.
Closing the Generalization Gap of Cross-silo Federated Medical Image Segmentation
Mar 18, 2022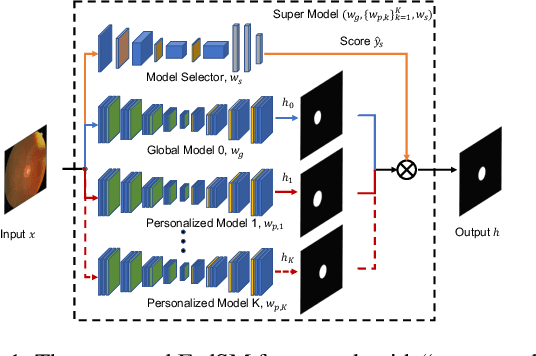
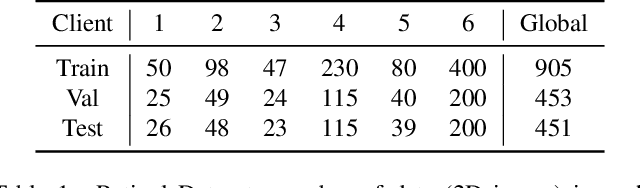
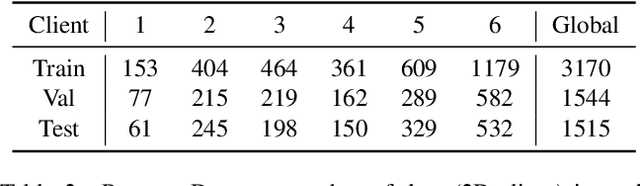
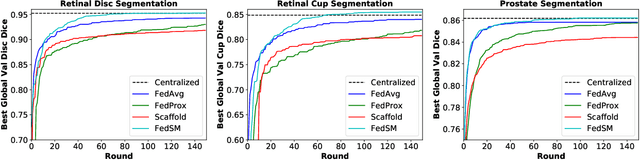
Cross-silo federated learning (FL) has attracted much attention in medical imaging analysis with deep learning in recent years as it can resolve the critical issues of insufficient data, data privacy, and training efficiency. However, there can be a generalization gap between the model trained from FL and the one from centralized training. This important issue comes from the non-iid data distribution of the local data in the participating clients and is well-known as client drift. In this work, we propose a novel training framework FedSM to avoid the client drift issue and successfully close the generalization gap compared with the centralized training for medical image segmentation tasks for the first time. We also propose a novel personalized FL objective formulation and a new method SoftPull to solve it in our proposed framework FedSM. We conduct rigorous theoretical analysis to guarantee its convergence for optimizing the non-convex smooth objective function. Real-world medical image segmentation experiments using deep FL validate the motivations and effectiveness of our proposed method.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022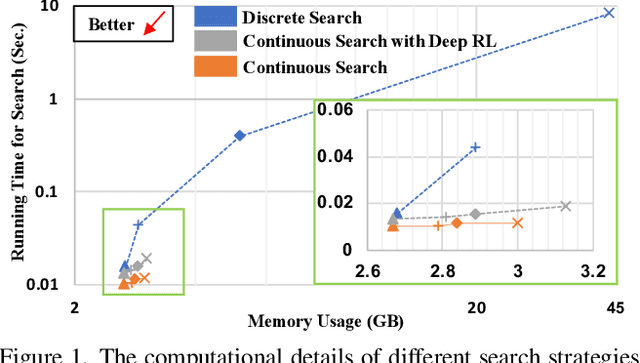

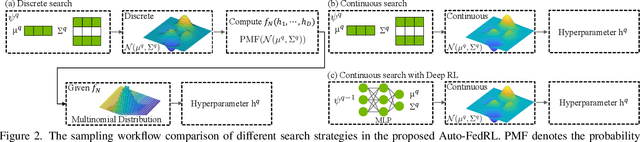

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Double Momentum SGD for Federated Learning
Feb 08, 2021
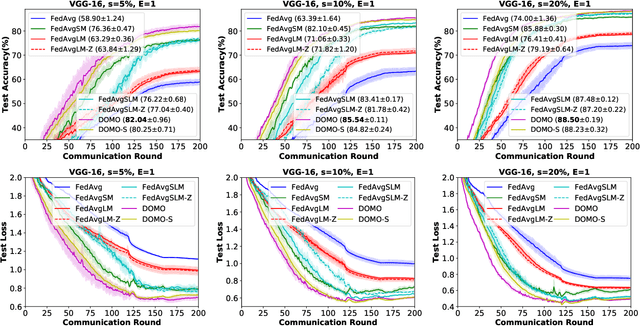
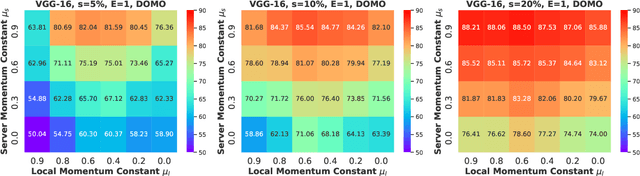
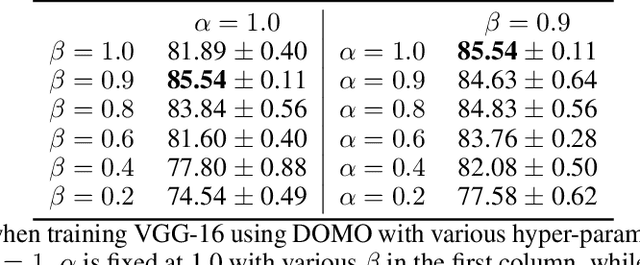
Communication efficiency is crucial in federated learning. Conducting many local training steps in clients to reduce the communication frequency between clients and the server is a common method to address this issue. However, the client drift problem arises as the non-i.i.d. data distributions in different clients can severely deteriorate the performance of federated learning. In this work, we propose a new SGD variant named as DOMO to improve the model performance in federated learning, where double momentum buffers are maintained. One momentum buffer tracks the server update direction, while the other tracks the local update direction. We introduce a novel server momentum fusion technique to coordinate the server and local momentum SGD. We also provide the first theoretical analysis involving both the server and local momentum SGD. Extensive experimental results show a better model performance of DOMO than FedAvg and existing momentum SGD variants in federated learning tasks.
Privacy-Preserving Asynchronous Federated Learning Algorithms for Multi-Party Vertically Collaborative Learning
Aug 14, 2020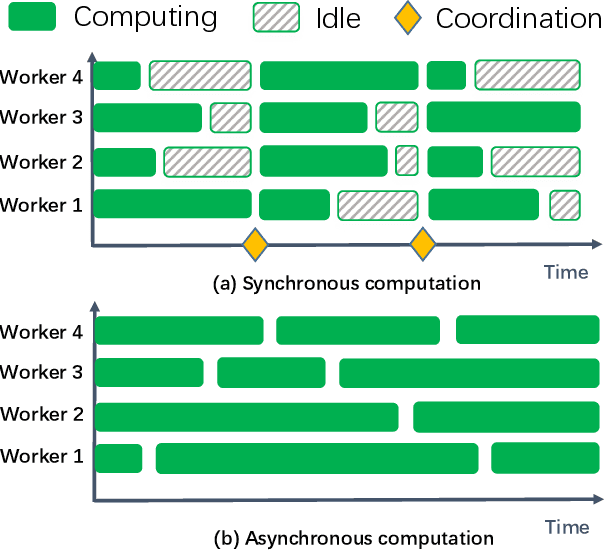

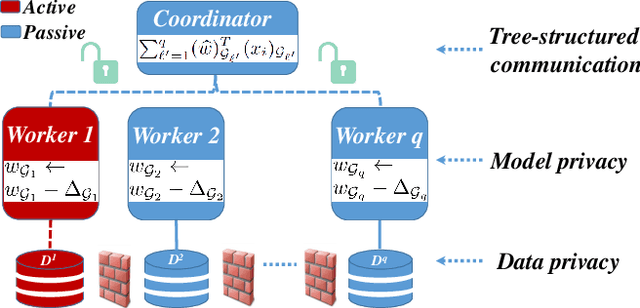
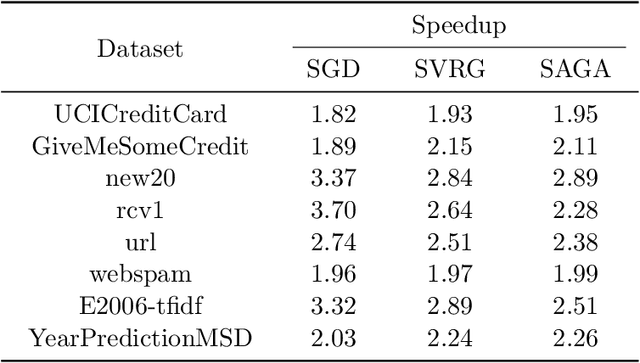
The privacy-preserving federated learning for vertically partitioned data has shown promising results as the solution of the emerging multi-party joint modeling application, in which the data holders (such as government branches, private finance and e-business companies) collaborate throughout the learning process rather than relying on a trusted third party to hold data. However, existing federated learning algorithms for vertically partitioned data are limited to synchronous computation. To improve the efficiency when the unbalanced computation/communication resources are common among the parties in the federated learning system, it is essential to develop asynchronous training algorithms for vertically partitioned data while keeping the data privacy. In this paper, we propose an asynchronous federated SGD (AFSGD-VP) algorithm and its SVRG and SAGA variants on the vertically partitioned data. Moreover, we provide the convergence analyses of AFSGD-VP and its SVRG and SAGA variants under the condition of strong convexity. We also discuss their model privacy, data privacy, computational complexities and communication costs. To the best of our knowledge, AFSGD-VP and its SVRG and SAGA variants are the first asynchronous federated learning algorithms for vertically partitioned data. Extensive experimental results on a variety of vertically partitioned datasets not only verify the theoretical results of AFSGD-VP and its SVRG and SAGA variants, but also show that our algorithms have much higher efficiency than the corresponding synchronous algorithms.
Training Faster with Compressed Gradient
Aug 13, 2020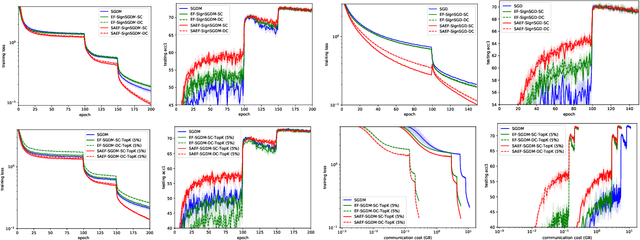
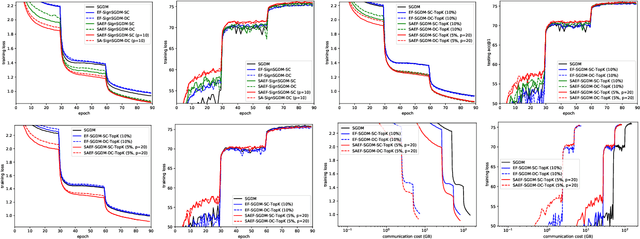
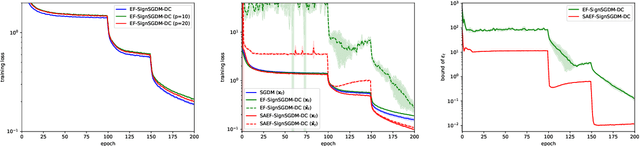
Although the distributed machine learning methods show the potential for the speed-up of training large deep neural networks, the communication cost has been the notorious bottleneck to constrain the performance. To address this challenge, the gradient compression based communication-efficient distributed learning methods were designed to reduce the communication cost, and more recently the local error feedback was incorporated to compensate for the performance loss. However, in this paper, we will show the "gradient mismatch" problem of the local error feedback in centralized distributed training and this issue can lead to degraded performance compared with full-precision training. To solve this critical problem, we propose two novel techniques: 1) step ahead; 2) error averaging. Both our theoretical and empirical results show that our new methods can alleviate the "gradient mismatch" problem. Experiments show that we can even train \textbf{faster with compressed gradient} than full-precision training \textbf{regarding training epochs}.
Exploit Where Optimizer Explores via Residuals
Apr 11, 2020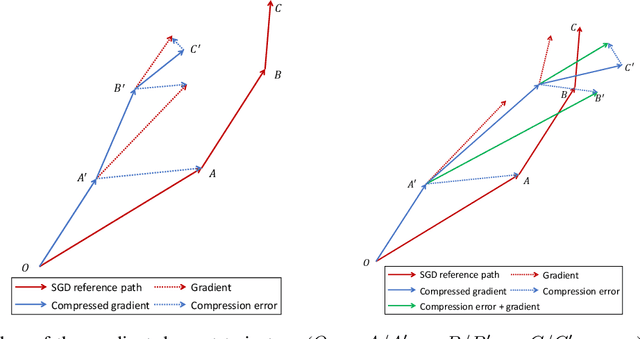
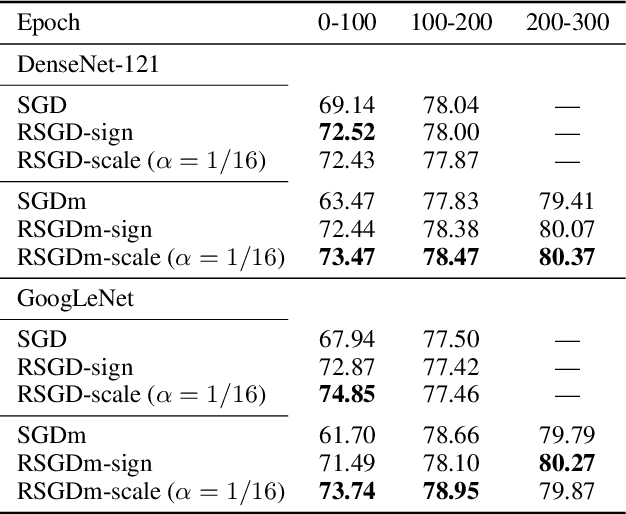
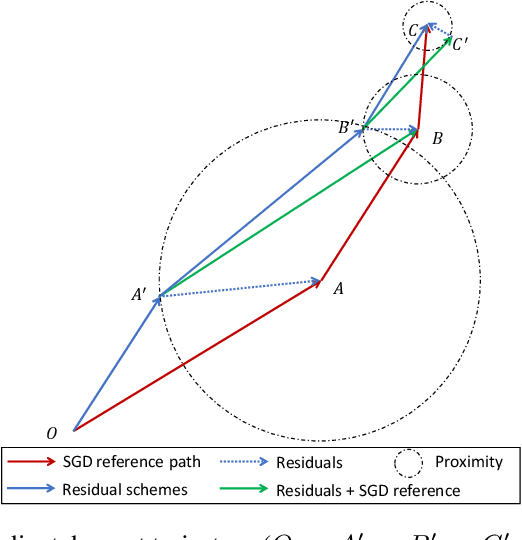
To train neural networks faster, many research efforts have been devoted to exploring a better gradient descent trajectory, but few have been put into exploiting the intermediate results. In this work we propose a novel optimization method named (momentum) stochastic gradient descent with residuals (RSGD(m)) to exploit the gradient descent trajectory using proper residual schemes, which leads to a performance boost of both the convergence and generalization. We provide theoretic analysis to show that RSGD can achieve a smaller growth rate of the generalization error and the same convergence rate compared with SGD. Extensive deep learning experimental results of the image classification and word-level language model empirically show that both the convergence and generalization of our RSGD(m) method are improved significantly compared with the existing SGD(m) algorithm.
Optimal Gradient Quantization Condition for Communication-Efficient Distributed Training
Feb 25, 2020

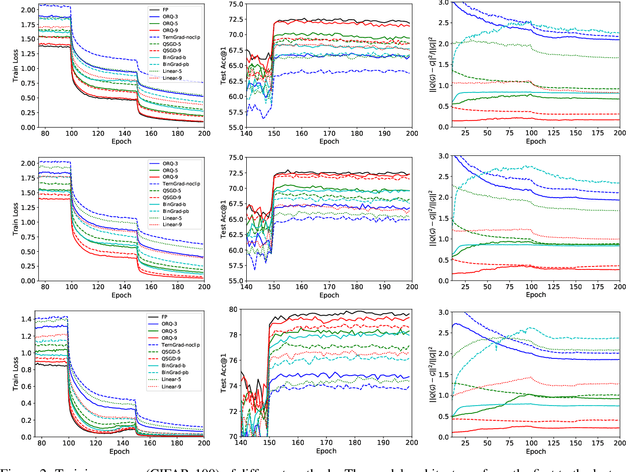
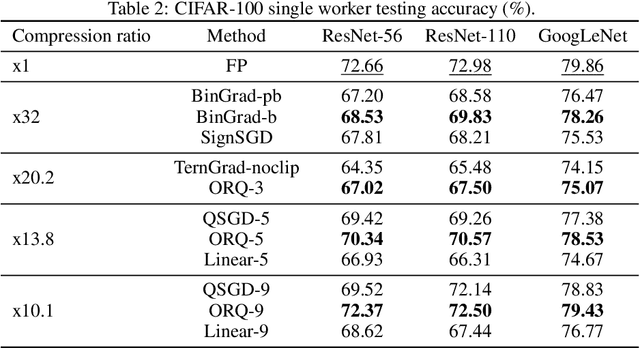
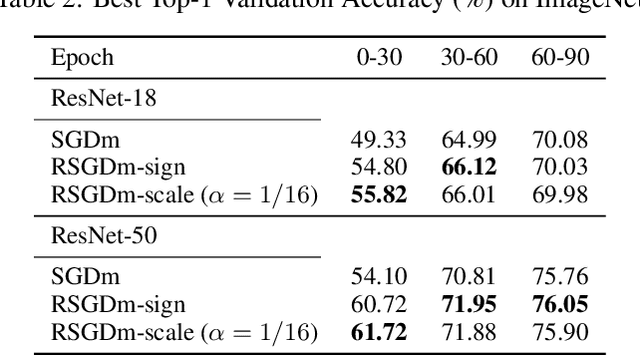
The communication of gradients is costly for training deep neural networks with multiple devices in computer vision applications. In particular, the growing size of deep learning models leads to higher communication overheads that defy the ideal linear training speedup regarding the number of devices. Gradient quantization is one of the common methods to reduce communication costs. However, it can lead to quantization error in the training and result in model performance degradation. In this work, we deduce the optimal condition of both the binary and multi-level gradient quantization for \textbf{ANY} gradient distribution. Based on the optimal condition, we develop two novel quantization schemes: biased BinGrad and unbiased ORQ for binary and multi-level gradient quantization respectively, which dynamically determine the optimal quantization levels. Extensive experimental results on CIFAR and ImageNet datasets with several popular convolutional neural networks show the superiority of our proposed methods.
Diversely Stale Parameters for Efficient Training of CNNs
Sep 24, 2019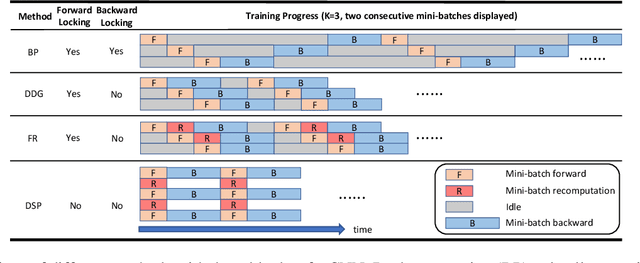
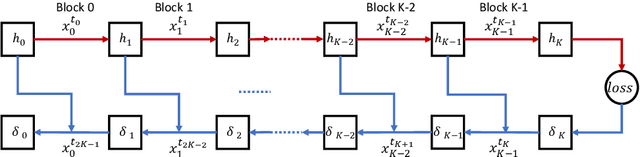
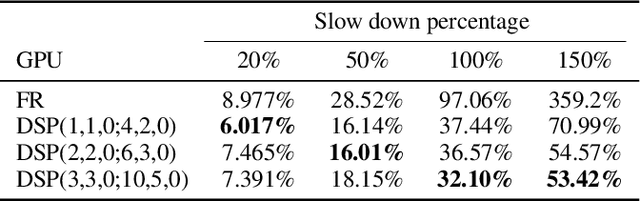
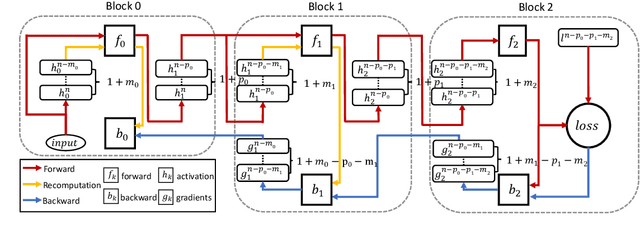
The backpropagation algorithm is the most popular algorithm training neural networks nowadays. However, it suffers from the forward locking, backward locking and update locking problems, especially when a neural network is so large that its layers are distributed across multiple devices. Existing solutions either can only handle one locking problem or lead to severe accuracy loss or memory inefficiency. Moreover, none of them consider the straggler problem among devices. In this paper, we propose Layer-wise Staleness and a novel efficient training algorithm, Diversely Stale Parameters (DSP), which can address all these challenges without loss of accuracy nor memory issue. We also analyze the convergence of DSP with two popular gradient-based methods and prove that both of them are guaranteed to converge to critical points for non-convex problems. Finally, extensive experimental results on training deep convolutional neural networks demonstrate that our proposed DSP algorithm can achieve significant training speedup with stronger robustness and better generalization than compared methods.