 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploit Where Optimizer Explores via Residuals
Paper and Code
Apr 11, 2020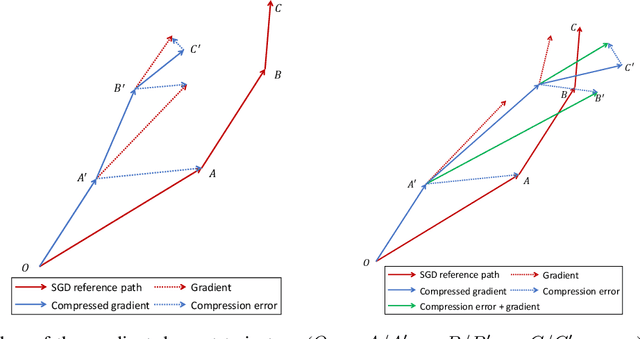
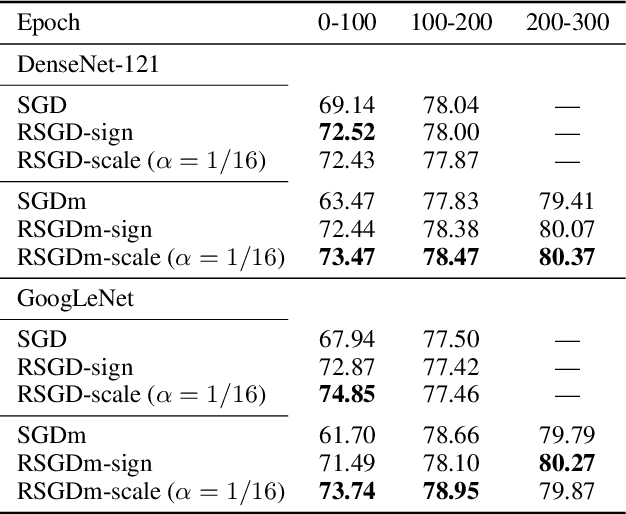
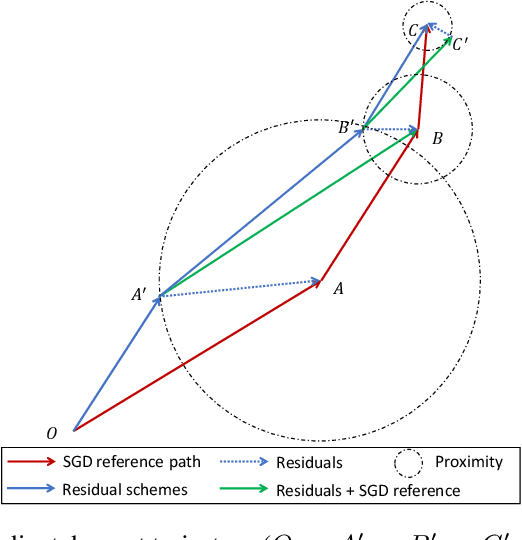
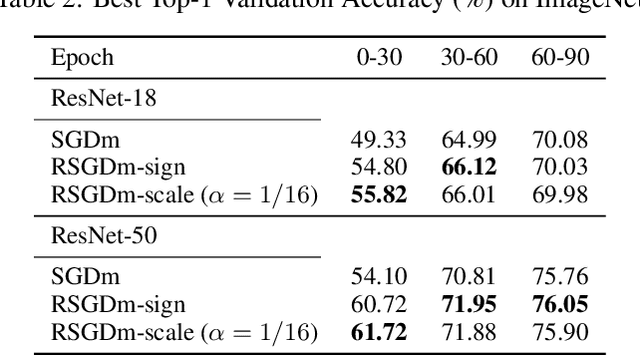
To train neural networks faster, many research efforts have been devoted to exploring a better gradient descent trajectory, but few have been put into exploiting the intermediate results. In this work we propose a novel optimization method named (momentum) stochastic gradient descent with residuals (RSGD(m)) to exploit the gradient descent trajectory using proper residual schemes, which leads to a performance boost of both the convergence and generalization. We provide theoretic analysis to show that RSGD can achieve a smaller growth rate of the generalization error and the same convergence rate compared with SGD. Extensive deep learning experimental results of the image classification and word-level language model empirically show that both the convergence and generalization of our RSGD(m) method are improved significantly compared with the existing SGD(m) algorithm.