 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing YOLO v7 to Detect Kidney in Magnetic Resonance Imaging
Feb 12, 2024



Introduction This study explores the use of the latest You Only Look Once (YOLO V7) object detection method to enhance kidney detection in medical imaging by training and testing a modified YOLO V7 on medical image formats. Methods Study includes 878 patients with various subtypes of renal cell carcinoma (RCC) and 206 patients with normal kidneys. A total of 5657 MRI scans for 1084 patients were retrieved. 326 patients with 1034 tumors recruited from a retrospective maintained database, and bounding boxes were drawn around their tumors. A primary model was trained on 80% of annotated cases, with 20% saved for testing (primary test set). The best primary model was then used to identify tumors in the remaining 861 patients and bounding box coordinates were generated on their scans using the model. Ten benchmark training sets were created with generated coordinates on not-segmented patients. The final model used to predict the kidney in the primary test set. We reported the positive predictive value (PPV), sensitivity, and mean average precision (mAP). Results The primary training set showed an average PPV of 0.94 +/- 0.01, sensitivity of 0.87 +/- 0.04, and mAP of 0.91 +/- 0.02. The best primary model yielded a PPV of 0.97, sensitivity of 0.92, and mAP of 0.95. The final model demonstrated an average PPV of 0.95 +/- 0.03, sensitivity of 0.98 +/- 0.004, and mAP of 0.95 +/- 0.01. Conclusion Using a semi-supervised approach with a medical image library, we developed a high-performing model for kidney detection. Further external validation is required to assess the model's generalizability.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022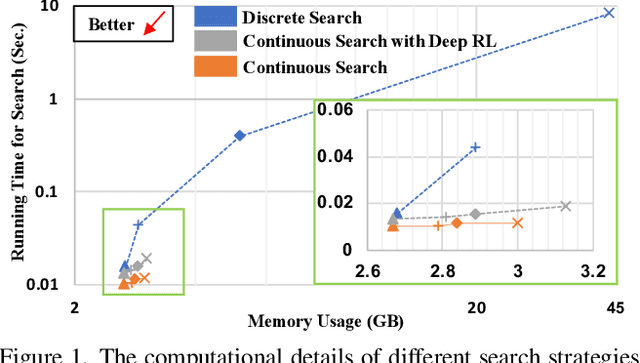

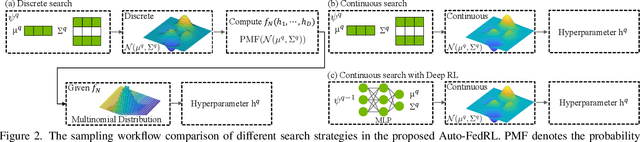

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Improving Pneumonia Localization via Cross-Attention on Medical Images and Reports
Oct 06, 2021
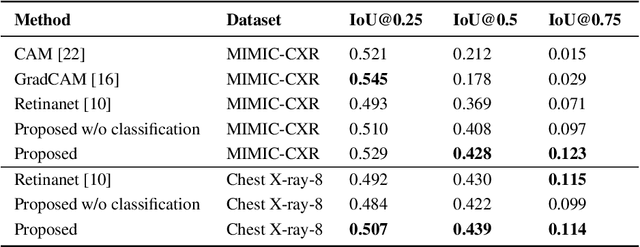
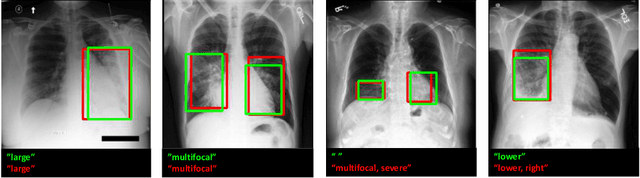

Localization and characterization of diseases like pneumonia are primary steps in a clinical pipeline, facilitating detailed clinical diagnosis and subsequent treatment planning. Additionally, such location annotated datasets can provide a pathway for deep learning models to be used for downstream tasks. However, acquiring quality annotations is expensive on human resources and usually requires domain expertise. On the other hand, medical reports contain a plethora of information both about pneumonia characteristics and its location. In this paper, we propose a novel weakly-supervised attention-driven deep learning model that leverages encoded information in medical reports during training to facilitate better localization. Our model also performs classification of attributes that are associated to pneumonia and extracted from medical reports for supervision. Both the classification and localization are trained in conjunction and once trained, the model can be utilized for both the localization and characterization of pneumonia using only the input image. In this paper, we explore and analyze the model using chest X-ray datasets and demonstrate qualitatively and quantitatively that the introduction of textual information improves pneumonia localization. We showcase quantitative results on two datasets, MIMIC-CXR and Chest X-ray-8, and we also showcase severity characterization on the COVID-19 dataset.
Auto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Apr 20, 2021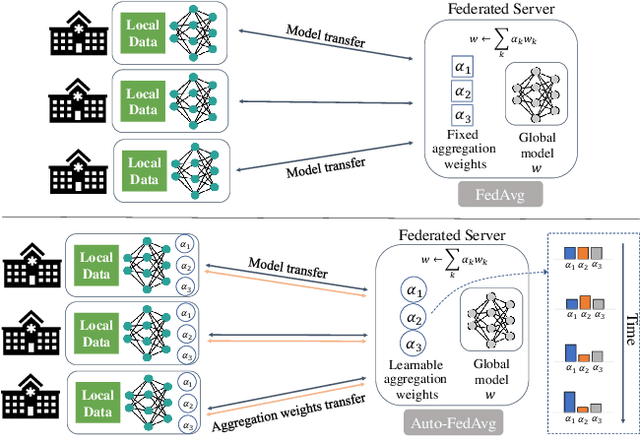
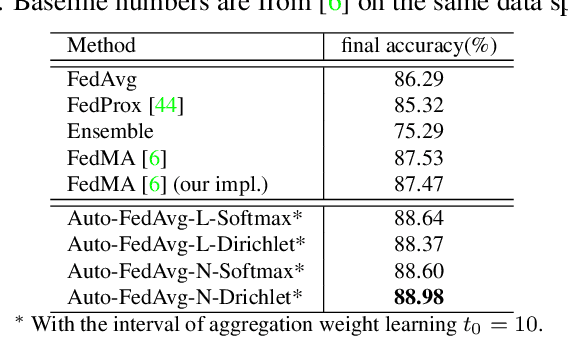
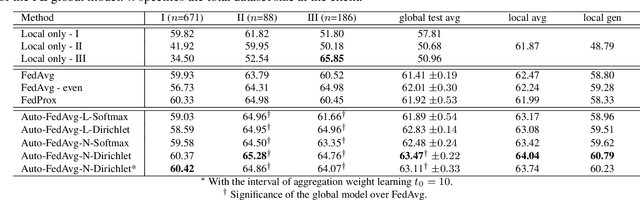
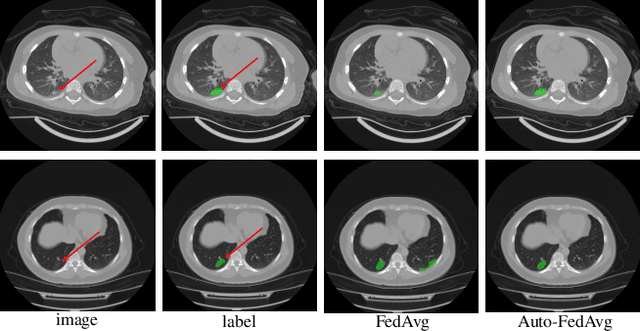
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Information Bottleneck Attribution for Visual Explanations of Diagnosis and Prognosis
Apr 07, 2021
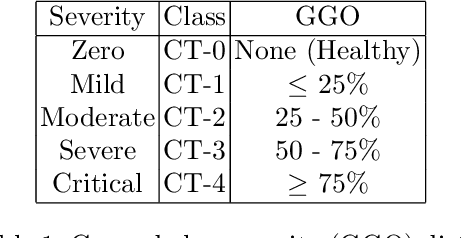
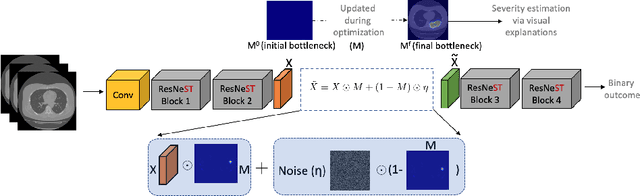
Visual explanation methods have an important role in the prognosis of the patients where the annotated data is limited or not available. There have been several attempts to use gradient-based attribution methods to localize pathology from medical scans without using segmentation labels. This research direction has been impeded by the lack of robustness and reliability. These methods are highly sensitive to the network parameters. In this study, we introduce a robust visual explanation method to address this problem for medical applications. We provide a highly innovative algorithm to quantifying lesions in the lungs caused by the Covid-19 with high accuracy and robustness without using dense segmentation labels. Inspired by the information bottleneck concept, we mask the neural network representation with noise to find out important regions. This approach overcomes the drawbacks of commonly used Grad-Cam and its derived algorithms. The premise behind our proposed strategy is that the information flow is minimized while ensuring the classifier prediction stays similar. Our findings indicate that the bottleneck condition provides a more stable and robust severity estimation than the similar attribution methods.
Federated Semi-Supervised Learning for COVID Region Segmentation in Chest CT using Multi-National Data from China, Italy, Japan
Nov 23, 2020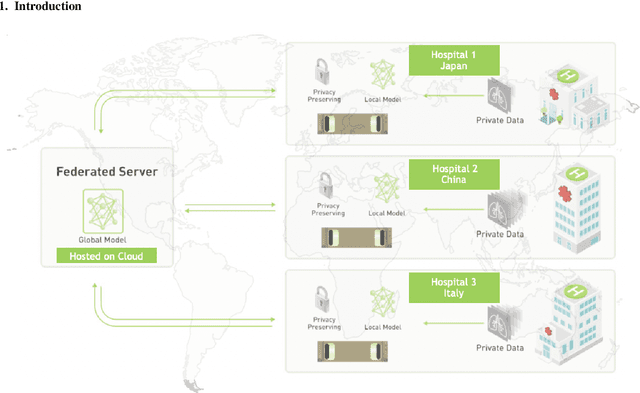


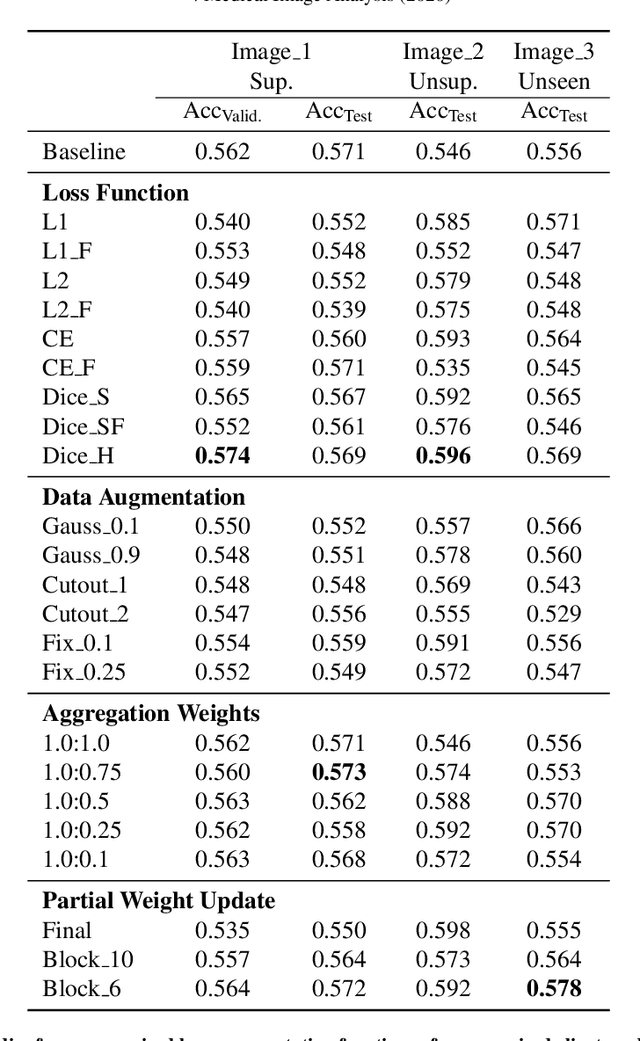
The recent outbreak of COVID-19 has led to urgent needs for reliable diagnosis and management of SARS-CoV-2 infection. As a complimentary tool, chest CT has been shown to be able to reveal visual patterns characteristic for COVID-19, which has definite value at several stages during the disease course. To facilitate CT analysis, recent efforts have focused on computer-aided characterization and diagnosis, which has shown promising results. However, domain shift of data across clinical data centers poses a serious challenge when deploying learning-based models. In this work, we attempt to find a solution for this challenge via federated and semi-supervised learning. A multi-national database consisting of 1704 scans from three countries is adopted to study the performance gap, when training a model with one dataset and applying it to another. Expert radiologists manually delineated 945 scans for COVID-19 findings. In handling the variability in both the data and annotations, a novel federated semi-supervised learning technique is proposed to fully utilize all available data (with or without annotations). Federated learning avoids the need for sensitive data-sharing, which makes it favorable for institutions and nations with strict regulatory policy on data privacy. Moreover, semi-supervision potentially reduces the annotation burden under a distributed setting. The proposed framework is shown to be effective compared to fully supervised scenarios with conventional data sharing instead of model weight sharing.
Weakly supervised one-stage vision and language disease detection using large scale pneumonia and pneumothorax studies
Jul 31, 2020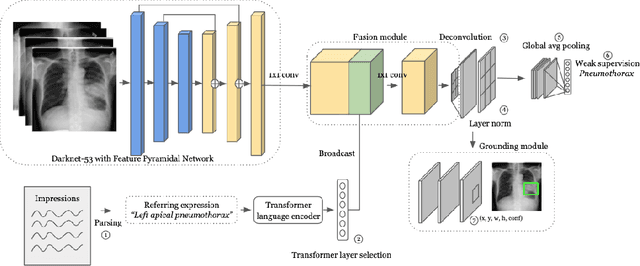

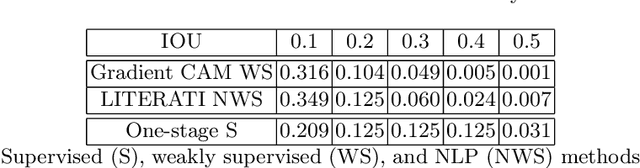
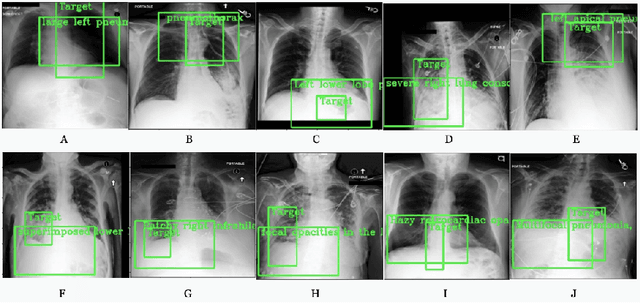
Detecting clinically relevant objects in medical images is a challenge despite large datasets due to the lack of detailed labels. To address the label issue, we utilize the scene-level labels with a detection architecture that incorporates natural language information. We present a challenging new set of radiologist paired bounding box and natural language annotations on the publicly available MIMIC-CXR dataset especially focussed on pneumonia and pneumothorax. Along with the dataset, we present a joint vision language weakly supervised transformer layer-selected one-stage dual head detection architecture (LITERATI) alongside strong baseline comparisons with class activation mapping (CAM), gradient CAM, and relevant implementations on the NIH ChestXray-14 and MIMIC-CXR dataset. Borrowing from advances in vision language architectures, the LITERATI method demonstrates joint image and referring expression (objects localized in the image using natural language) input for detection that scales in a purely weakly supervised fashion. The architectural modifications address three obstacles -- implementing a supervised vision and language detection method in a weakly supervised fashion, incorporating clinical referring expression natural language information, and generating high fidelity detections with map probabilities. Nevertheless, the challenging clinical nature of the radiologist annotations including subtle references, multi-instance specifications, and relatively verbose underlying medical reports, ensures the vision language detection task at scale remains stimulating for future investigation.
A Bottom-up Approach for Pancreas Segmentation using Cascaded Superpixels and (Deep) Image Patch Labeling
Mar 07, 2016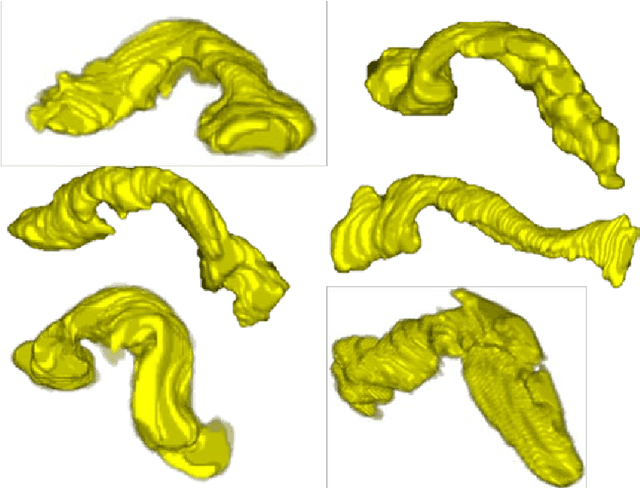

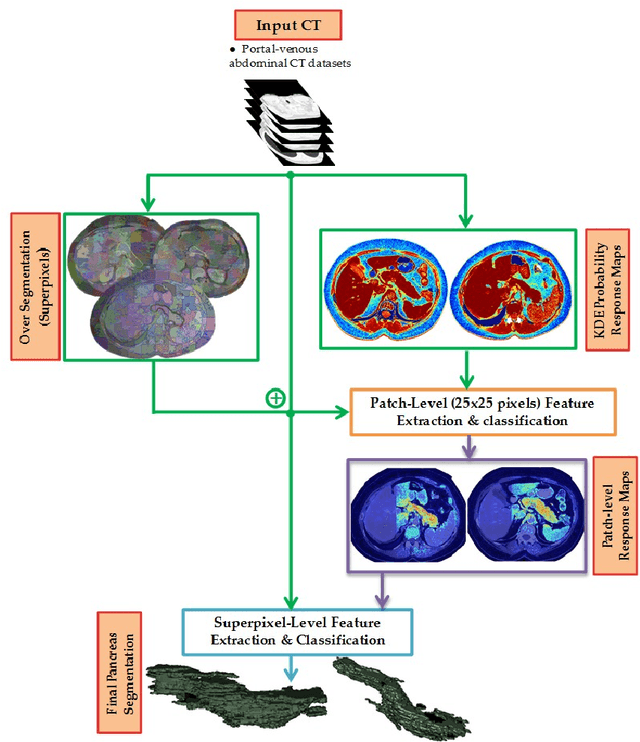
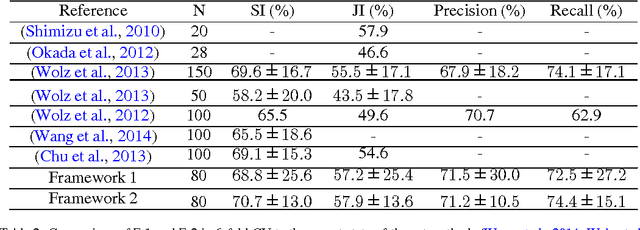
Robust automated organ segmentation is a prerequisite for computer-aided diagnosis (CAD), quantitative imaging analysis and surgical assistance. For high-variability organs such as the pancreas, previous approaches report undesirably low accuracies. We present a bottom-up approach for pancreas segmentation in abdominal CT scans that is based on a hierarchy of information propagation by classifying image patches at different resolutions; and cascading superpixels. There are four stages: 1) decomposing CT slice images as a set of disjoint boundary-preserving superpixels; 2) computing pancreas class probability maps via dense patch labeling; 3) classifying superpixels by pooling both intensity and probability features to form empirical statistics in cascaded random forest frameworks; and 4) simple connectivity based post-processing. The dense image patch labeling are conducted by: efficient random forest classifier on image histogram, location and texture features; and more expensive (but with better specificity) deep convolutional neural network classification on larger image windows (with more spatial contexts). Evaluation of the approach is performed on a database of 80 manually segmented CT volumes in six-fold cross-validation (CV). Our achieved results are comparable, or better than the state-of-the-art methods (evaluated by "leave-one-patient-out"), with Dice 70.7% and Jaccard 57.9%. The computational efficiency has been drastically improved in the order of 6~8 minutes, comparing with others of ~10 hours per case. Finally, we implement a multi-atlas label fusion (MALF) approach for pancreas segmentation using the same datasets. Under six-fold CV, our bottom-up segmentation method significantly outperforms its MALF counterpart: (70.7 +/- 13.0%) versus (52.5 +/- 20.8%) in Dice. Deep CNN patch labeling confidences offer more numerical stability, reflected by smaller standard deviations.
DeepOrgan: Multi-level Deep Convolutional Networks for Automated Pancreas Segmentation
Jun 22, 2015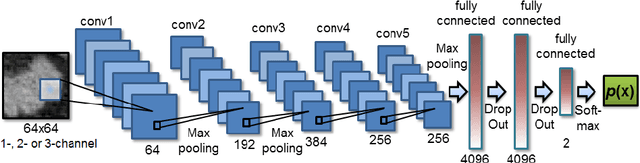
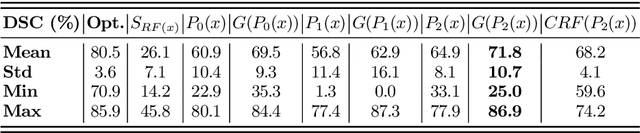


Automatic organ segmentation is an important yet challenging problem for medical image analysis. The pancreas is an abdominal organ with very high anatomical variability. This inhibits previous segmentation methods from achieving high accuracies, especially compared to other organs such as the liver, heart or kidneys. In this paper, we present a probabilistic bottom-up approach for pancreas segmentation in abdominal computed tomography (CT) scans, using multi-level deep convolutional networks (ConvNets). We propose and evaluate several variations of deep ConvNets in the context of hierarchical, coarse-to-fine classification on image patches and regions, i.e. superpixels. We first present a dense labeling of local image patches via $P{-}\mathrm{ConvNet}$ and nearest neighbor fusion. Then we describe a regional ConvNet ($R_1{-}\mathrm{ConvNet}$) that samples a set of bounding boxes around each image superpixel at different scales of contexts in a "zoom-out" fashion. Our ConvNets learn to assign class probabilities for each superpixel region of being pancreas. Last, we study a stacked $R_2{-}\mathrm{ConvNet}$ leveraging the joint space of CT intensities and the $P{-}\mathrm{ConvNet}$ dense probability maps. Both 3D Gaussian smoothing and 2D conditional random fields are exploited as structured predictions for post-processing. We evaluate on CT images of 82 patients in 4-fold cross-validation. We achieve a Dice Similarity Coefficient of 83.6$\pm$6.3% in training and 71.8$\pm$10.7% in testing.
A Bottom-Up Approach for Automatic Pancreas Segmentation in Abdominal CT Scans
Jul 31, 2014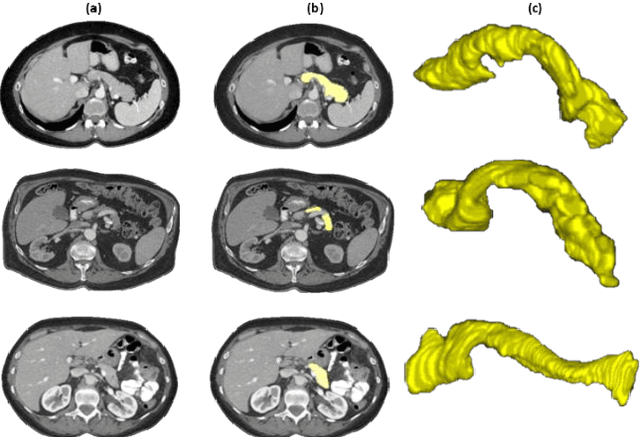
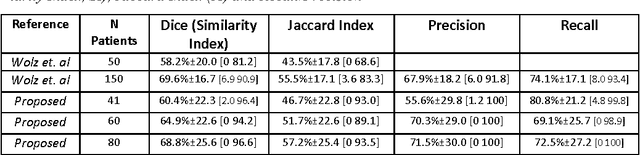
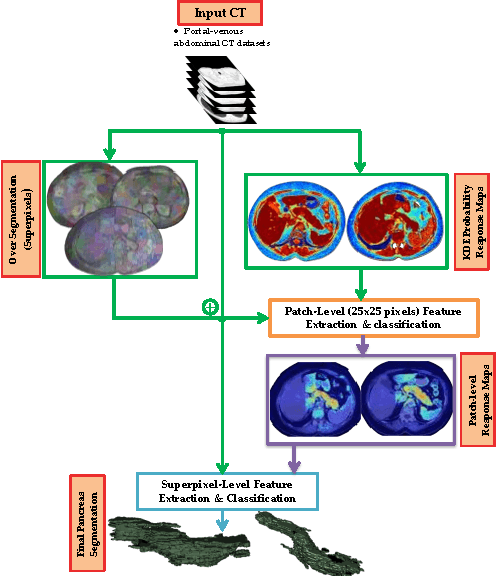
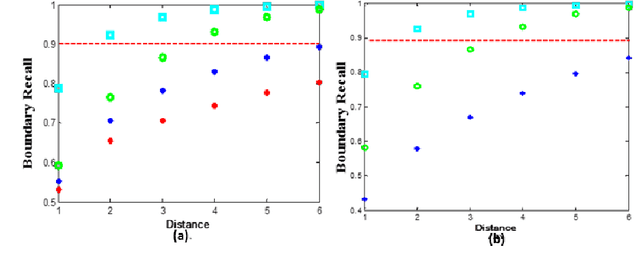
Organ segmentation is a prerequisite for a computer-aided diagnosis (CAD) system to detect pathologies and perform quantitative analysis. For anatomically high-variability abdominal organs such as the pancreas, previous segmentation works report low accuracies when comparing to organs like the heart or liver. In this paper, a fully-automated bottom-up method is presented for pancreas segmentation, using abdominal computed tomography (CT) scans. The method is based on a hierarchical two-tiered information propagation by classifying image patches. It labels superpixels as pancreas or not via pooling patch-level confidences on 2D CT slices over-segmented by the Simple Linear Iterative Clustering approach. A supervised random forest (RF) classifier is trained on the patch level and a two-level cascade of RFs is applied at the superpixel level, coupled with multi-channel feature extraction, respectively. On six-fold cross-validation using 80 patient CT volumes, we achieved 68.8% Dice coefficient and 57.2% Jaccard Index, comparable to or slightly better than published state-of-the-art methods.