 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-FedAvg: Learnable Federated Averaging for Multi-Institutional Medical Image Segmentation
Paper and Code
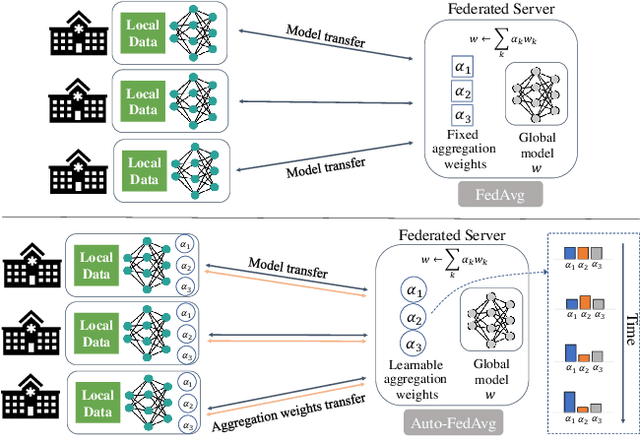
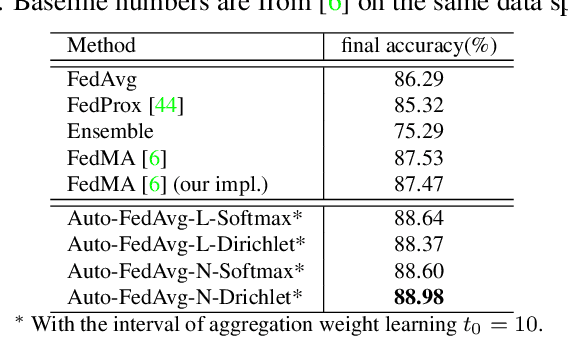
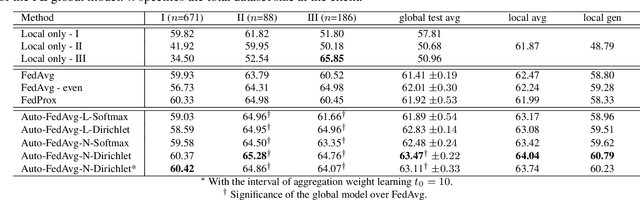
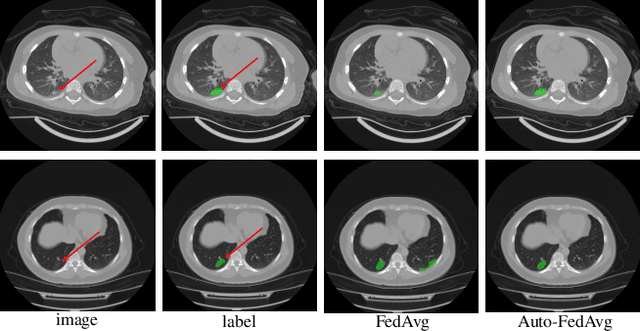
Federated learning (FL) enables collaborative model training while preserving each participant's privacy, which is particularly beneficial to the medical field. FedAvg is a standard algorithm that uses fixed weights, often originating from the dataset sizes at each client, to aggregate the distributed learned models on a server during the FL process. However, non-identical data distribution across clients, known as the non-i.i.d problem in FL, could make this assumption for setting fixed aggregation weights sub-optimal. In this work, we design a new data-driven approach, namely Auto-FedAvg, where aggregation weights are dynamically adjusted, depending on data distributions across data silos and the current training progress of the models. We disentangle the parameter set into two parts, local model parameters and global aggregation parameters, and update them iteratively with a communication-efficient algorithm. We first show the validity of our approach by outperforming state-of-the-art FL methods for image recognition on a heterogeneous data split of CIFAR-10. Furthermore, we demonstrate our algorithm's effectiveness on two multi-institutional medical image analysis tasks, i.e., COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.