 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pneumonia Localization via Cross-Attention on Medical Images and Reports
Oct 06, 2021
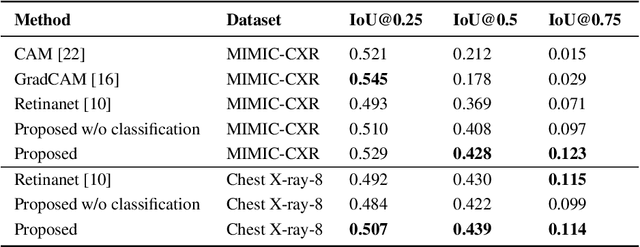
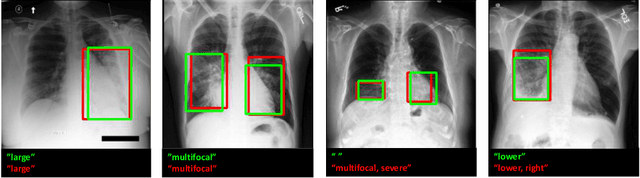

Localization and characterization of diseases like pneumonia are primary steps in a clinical pipeline, facilitating detailed clinical diagnosis and subsequent treatment planning. Additionally, such location annotated datasets can provide a pathway for deep learning models to be used for downstream tasks. However, acquiring quality annotations is expensive on human resources and usually requires domain expertise. On the other hand, medical reports contain a plethora of information both about pneumonia characteristics and its location. In this paper, we propose a novel weakly-supervised attention-driven deep learning model that leverages encoded information in medical reports during training to facilitate better localization. Our model also performs classification of attributes that are associated to pneumonia and extracted from medical reports for supervision. Both the classification and localization are trained in conjunction and once trained, the model can be utilized for both the localization and characterization of pneumonia using only the input image. In this paper, we explore and analyze the model using chest X-ray datasets and demonstrate qualitatively and quantitatively that the introduction of textual information improves pneumonia localization. We showcase quantitative results on two datasets, MIMIC-CXR and Chest X-ray-8, and we also showcase severity characterization on the COVID-19 dataset.
Self-supervised Image-text Pre-training With Mixed Data In Chest X-rays
Mar 30, 2021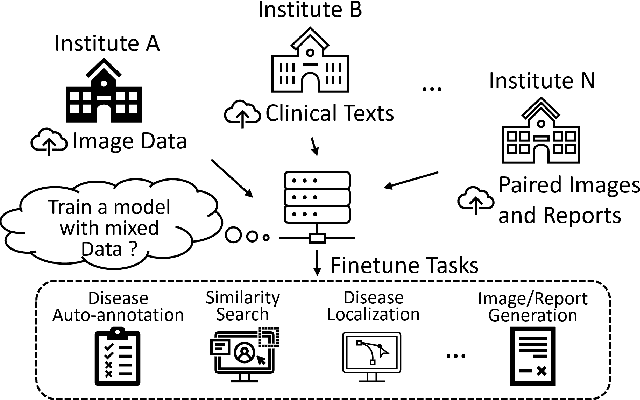
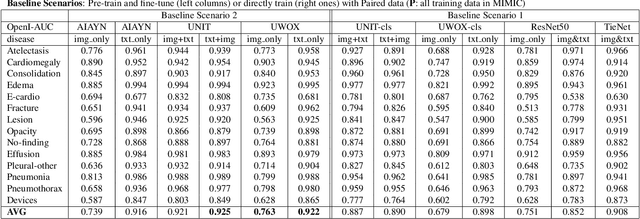
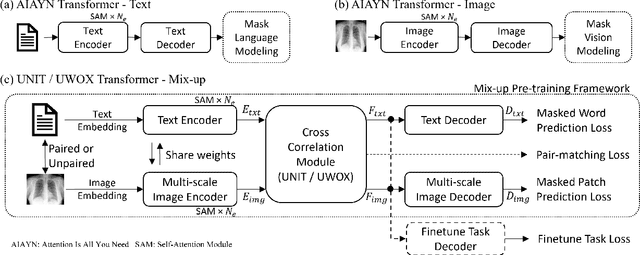
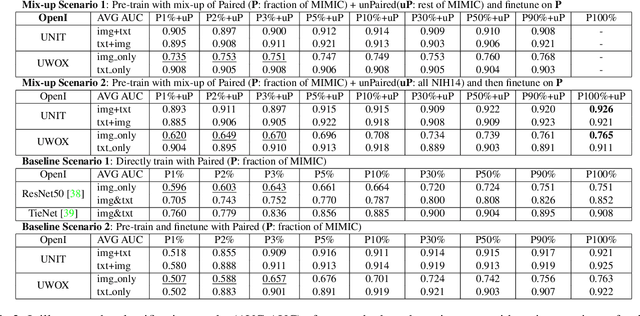
Pre-trained models, e.g., from ImageNet, have proven to be effective in boosting the performance of many downstream applications. It is too demanding to acquire large-scale annotations to build such models for medical imaging. Meanwhile, there are numerous clinical data (in the form of images and text reports) stored in the hospital information systems. The paired image-text data from the same patient study could be utilized for the pre-training task in a weakly supervised manner. However, the integrity, accessibility, and amount of such raw data vary across different institutes, e.g., paired vs. unpaired (image-only or text-only). In this work, we introduce an image-text pre-training framework that can learn from these raw data with mixed data inputs, i.e., paired image-text data, a mixture of paired and unpaired data. The unpaired data can be sourced from one or multiple institutes (e.g., images from one institute coupled with texts from another). Specifically, we propose a transformer-based training framework for jointly learning the representation of both the image and text data. In addition to the existing masked language modeling, multi-scale masked vision modeling is introduced as a self-supervised training task for image patch regeneration. We not only demonstrate the feasibility of pre-training across mixed data inputs but also illustrate the benefits of adopting such pre-trained models in 3 chest X-ray applications, i.e., classification, retrieval, and image regeneration. Superior results are reported in comparison to prior art using MIMIC-CXR, NIH14-CXR, and OpenI-CXR datasets.
Learning Image Labels On-the-fly for Training Robust Classification Models
Oct 02, 2020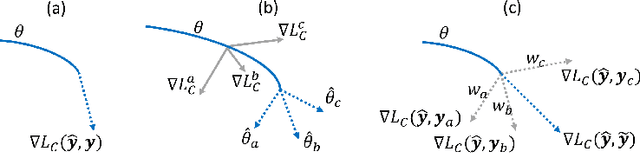
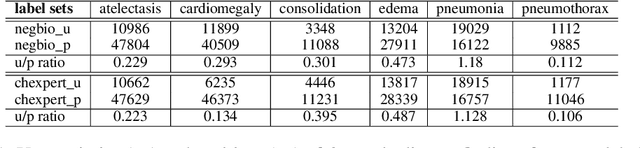
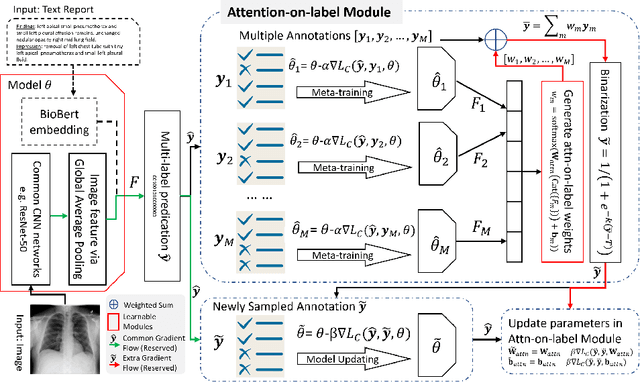

Current deep learning paradigms largely benefit from the tremendous amount of annotated data. However, the quality of the annotations often varies among labelers. Multi-observer studies have been conducted to study these annotation variances (by labeling the same data for multiple times) and its effects on critical applications like medical image analysis. This process indeed adds an extra burden to the already tedious annotation work that usually requires professional training and expertise in the specific domains. On the other hand, automated annotation methods based on NLP algorithms have recently shown promise as a reasonable alternative, relying on the existing diagnostic reports of those images that are widely available in the clinical system. Compared to human labelers, different algorithms provide labels with varying qualities that are even noisier. In this paper, we show how noisy annotations (e.g., from different algorithm-based labelers) can be utilized together and mutually benefit the learning of classification tasks. Specifically, the concept of attention-on-label is introduced to sample better label sets on-the-fly as the training data. A meta-training based label-sampling module is designed to attend the labels that benefit the model learning the most through additional back-propagation processes. We apply the attention-on-label scheme on the classification task of a synthetic noisy CIFAR-10 dataset to prove the concept, and then demonstrate superior results (3-5% increase on average in multiple disease classification AUCs) on the chest x-ray images from a hospital-scale dataset (MIMIC-CXR) and hand-labeled dataset (OpenI) in comparison to regular training paradigms.