 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Gradient Quantization Condition for Communication-Efficient Distributed Training
Paper and Code
Feb 25, 2020

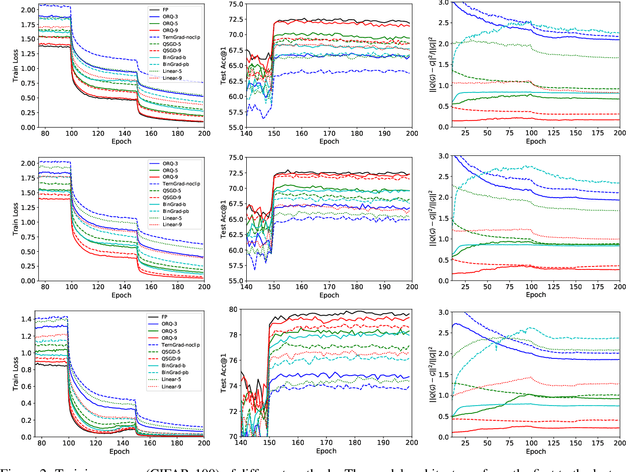
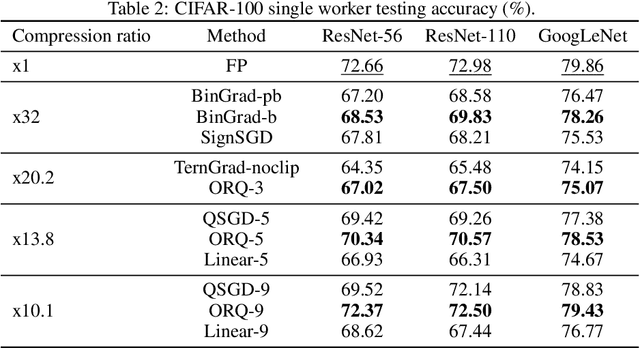
The communication of gradients is costly for training deep neural networks with multiple devices in computer vision applications. In particular, the growing size of deep learning models leads to higher communication overheads that defy the ideal linear training speedup regarding the number of devices. Gradient quantization is one of the common methods to reduce communication costs. However, it can lead to quantization error in the training and result in model performance degradation. In this work, we deduce the optimal condition of both the binary and multi-level gradient quantization for \textbf{ANY} gradient distribution. Based on the optimal condition, we develop two novel quantization schemes: biased BinGrad and unbiased ORQ for binary and multi-level gradient quantization respectively, which dynamically determine the optimal quantization levels. Extensive experimental results on CIFAR and ImageNet datasets with several popular convolutional neural networks show the superiority of our proposed methods.