 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Momentum SGD for Federated Learning
Paper and Code
Feb 08, 2021
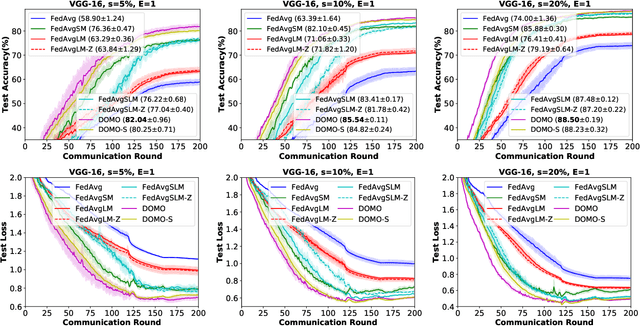
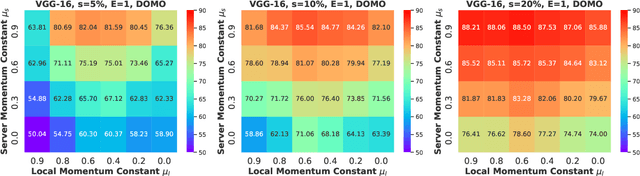
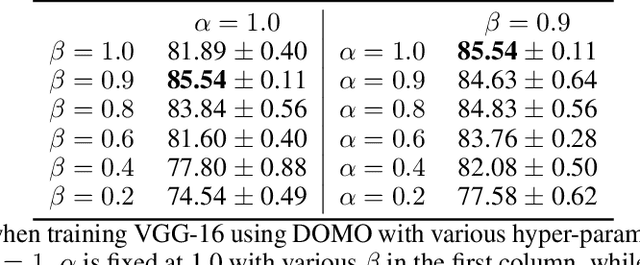
Communication efficiency is crucial in federated learning. Conducting many local training steps in clients to reduce the communication frequency between clients and the server is a common method to address this issue. However, the client drift problem arises as the non-i.i.d. data distributions in different clients can severely deteriorate the performance of federated learning. In this work, we propose a new SGD variant named as DOMO to improve the model performance in federated learning, where double momentum buffers are maintained. One momentum buffer tracks the server update direction, while the other tracks the local update direction. We introduce a novel server momentum fusion technique to coordinate the server and local momentum SGD. We also provide the first theoretical analysis involving both the server and local momentum SGD. Extensive experimental results show a better model performance of DOMO than FedAvg and existing momentum SGD variants in federated learning tasks.