 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOIST: A Joint Speech and Text Streaming Model For ASR
Paper and Code
Oct 13, 2022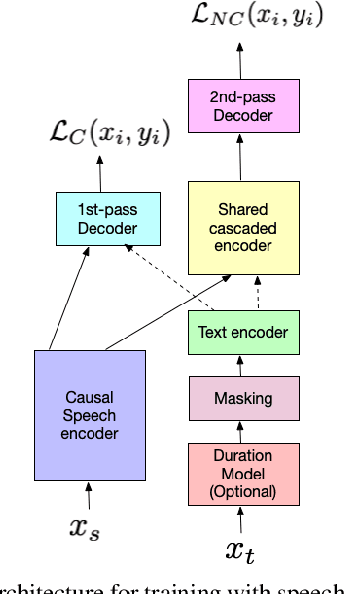

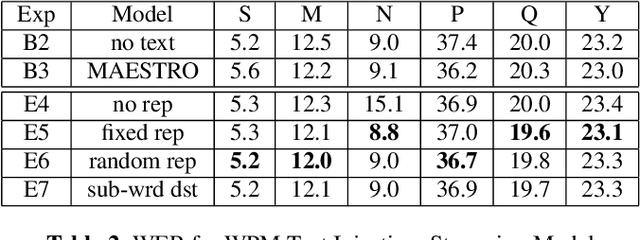

We present JOIST, an algorithm to train a streaming, cascaded, encoder end-to-end (E2E) model with both speech-text paired inputs, and text-only unpaired inputs. Unlike previous works, we explore joint training with both modalities, rather than pre-training and fine-tuning. In addition, we explore JOIST using a streaming E2E model with an order of magnitude more data, which are also novelties compared to previous works. Through a series of ablation studies, we explore different types of text modeling, including how to model the length of the text sequence and the appropriate text sub-word unit representation. We find that best text representation for JOIST improves WER across a variety of search and rare-word test sets by 4-14% relative, compared to a model not trained with text. In addition, we quantitatively show that JOIST maintains streaming capabilities, which is important for good user-level experience.