 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo Label Is Better Than Human Label
Paper and Code
Mar 28, 2022


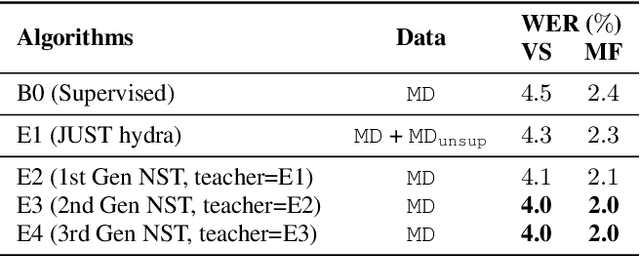
State-of-the-art automatic speech recognition (ASR) systems are trained with tens of thousands of hours of labeled speech data. Human transcription is expensive and time consuming. Factors such as the quality and consistency of the transcription can greatly affect the performance of the ASR models trained with these data. In this paper, we show that we can train a strong teacher model to produce high quality pseudo labels by utilizing recent self-supervised and semi-supervised learning techniques. Specifically, we use JUST (Joint Unsupervised/Supervised Training) and iterative noisy student teacher training to train a 600 million parameter bi-directional teacher model. This model achieved 4.0% word error rate (WER) on a voice search task, 11.1% relatively better than a baseline. We further show that by using this strong teacher model to generate high-quality pseudo labels for training, we can achieve 13.6% relative WER reduction (5.9% to 5.1%) for a streaming model compared to using human labels.