 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging 2D Information for Long-term Time Series Forecasting with Vanilla Transformers
Paper and Code
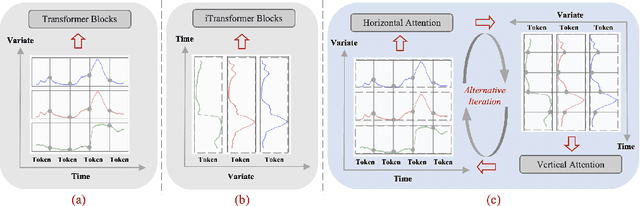
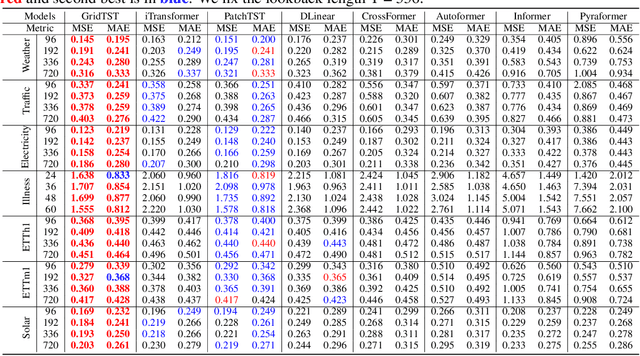
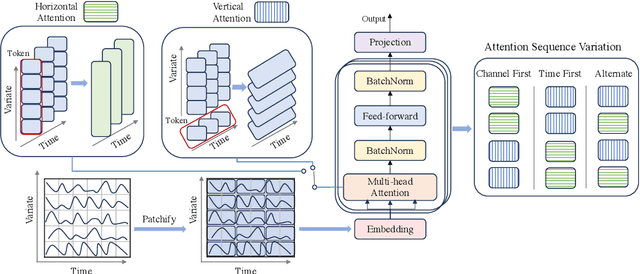
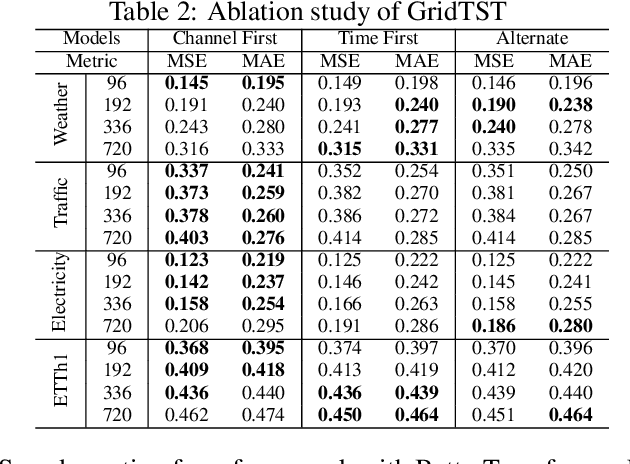
Time series prediction is crucial for understanding and forecasting complex dynamics in various domains, ranging from finance and economics to climate and healthcare. Based on Transformer architecture, one approach involves encoding multiple variables from the same timestamp into a single temporal token to model global dependencies. In contrast, another approach embeds the time points of individual series into separate variate tokens. The former method faces challenges in learning variate-centric representations, while the latter risks missing essential temporal information critical for accurate forecasting. In our work, we introduce GridTST, a model that combines the benefits of two approaches using innovative multi-directional attentions based on a vanilla Transformer. We regard the input time series data as a grid, where the $x$-axis represents the time steps and the $y$-axis represents the variates. A vertical slicing of this grid combines the variates at each time step into a \textit{time token}, while a horizontal slicing embeds the individual series across all time steps into a \textit{variate token}. Correspondingly, a \textit{horizontal attention mechanism} focuses on time tokens to comprehend the correlations between data at various time steps, while a \textit{vertical}, variate-aware \textit{attention} is employed to grasp multivariate correlations. This combination enables efficient processing of information across both time and variate dimensions, thereby enhancing the model's analytical strength. % We also integrate the patch technique, segmenting time tokens into subseries-level patches, ensuring that local semantic information is retained in the embedding. The GridTST model consistently delivers state-of-the-art performance across various real-world datasets.