 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Enhanced Hyperbolic Space Recommender Systems
Apr 08, 2025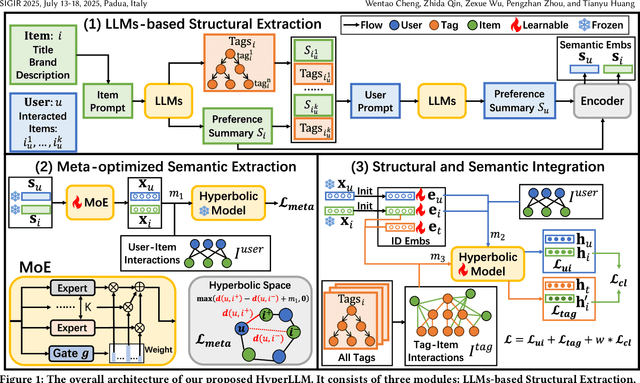
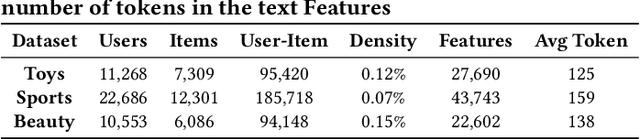
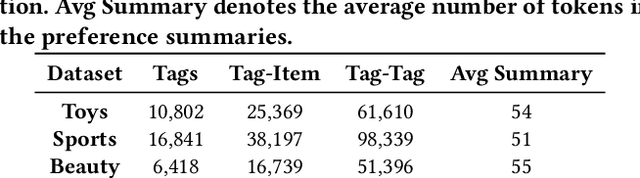
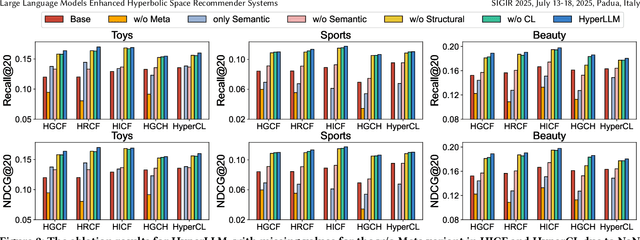
Large Language Models (LLMs) have attracted significant attention in recommender systems for their excellent world knowledge capabilities. However, existing methods that rely on Euclidean space struggle to capture the rich hierarchical information inherent in textual and semantic data, which is essential for capturing user preferences. The geometric properties of hyperbolic space offer a promising solution to address this issue. Nevertheless, integrating LLMs-based methods with hyperbolic space to effectively extract and incorporate diverse hierarchical information is non-trivial. To this end, we propose a model-agnostic framework, named HyperLLM, which extracts and integrates hierarchical information from both structural and semantic perspectives. Structurally, HyperLLM uses LLMs to generate multi-level classification tags with hierarchical parent-child relationships for each item. Then, tag-item and user-item interactions are jointly learned and aligned through contrastive learning, thereby providing the model with clear hierarchical information. Semantically, HyperLLM introduces a novel meta-optimized strategy to extract hierarchical information from semantic embeddings and bridge the gap between the semantic and collaborative spaces for seamless integration. Extensive experiments show that HyperLLM significantly outperforms recommender systems based on hyperbolic space and LLMs, achieving performance improvements of over 40%. Furthermore, HyperLLM not only improves recommender performance but also enhances training stability, highlighting the critical role of hierarchical information in recommender systems.
FedPAW: Federated Learning with Personalized Aggregation Weights for Urban Vehicle Speed Prediction
Dec 02, 2024

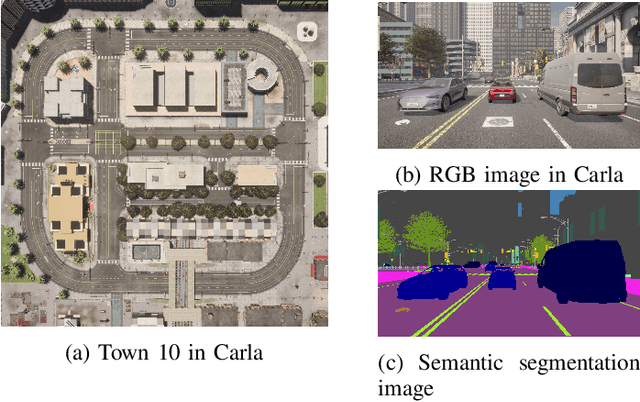

Vehicle speed prediction is crucial for intelligent transportation systems, promoting more reliable autonomous driving by accurately predicting future vehicle conditions. Due to variations in drivers' driving styles and vehicle types, speed predictions for different target vehicles may significantly differ. Existing methods may not realize personalized vehicle speed prediction while protecting drivers' data privacy. We propose a Federated learning framework with Personalized Aggregation Weights (FedPAW) to overcome these challenges. This method captures client-specific information by measuring the weighted mean squared error between the parameters of local models and global models. The server sends tailored aggregated models to clients instead of a single global model, without incurring additional computational and communication overhead for clients. To evaluate the effectiveness of FedPAW, we collected driving data in urban scenarios using the autonomous driving simulator CARLA, employing an LSTM-based Seq2Seq model with a multi-head attention mechanism to predict the future speed of target vehicles. The results demonstrate that our proposed FedPAW ranks lowest in prediction error within the time horizon of 10 seconds, with a 0.8% reduction in test MAE, compared to eleven representative benchmark baselines. The source code of FedPAW and dataset CarlaVSP are open-accessed at: https://github.com/heyuepeng/PFLlibVSP and https://pan.baidu.com/s/1qs8fxUvSPERV3C9i6pfUIw?pwd=tl3e.
FedAH: Aggregated Head for Personalized Federated Learning
Dec 02, 2024



Recently, Federated Learning (FL) has gained popularity for its privacy-preserving and collaborative learning capabilities. Personalized Federated Learning (PFL), building upon FL, aims to address the issue of statistical heterogeneity and achieve personalization. Personalized-head-based PFL is a common and effective PFL method that splits the model into a feature extractor and a head, where the feature extractor is collaboratively trained and shared, while the head is locally trained and not shared. However, retaining the head locally, although achieving personalization, prevents the model from learning global knowledge in the head, thus affecting the performance of the personalized model. To solve this problem, we propose a novel PFL method called Federated Learning with Aggregated Head (FedAH), which initializes the head with an Aggregated Head at each iteration. The key feature of FedAH is to perform element-level aggregation between the local model head and the global model head to introduce global information from the global model head. To evaluate the effectiveness of FedAH, we conduct extensive experiments on five benchmark datasets in the fields of computer vision and natural language processing. FedAH outperforms ten state-of-the-art FL methods in terms of test accuracy by 2.87%. Additionally, FedAH maintains its advantage even in scenarios where some clients drop out unexpectedly. Our code is open-accessed at https://github.com/heyuepeng/FedAH.
FedRAV: Hierarchically Federated Region-Learning for Traffic Object Classification of Autonomous Vehicles
Nov 21, 2024
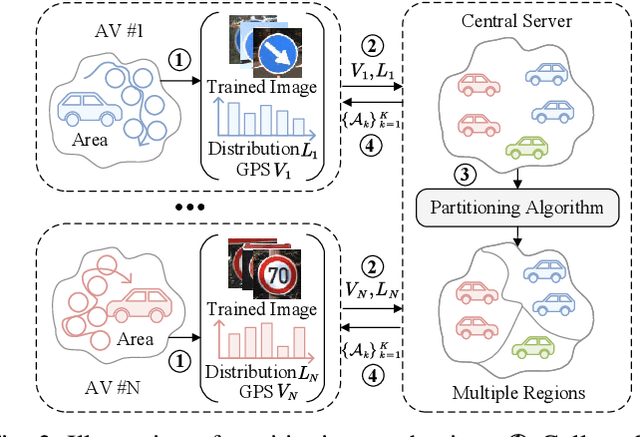
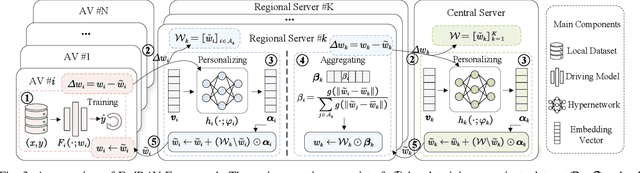

The emerging federated learning enables distributed autonomous vehicles to train equipped deep learning models collaboratively without exposing their raw data, providing great potential for utilizing explosively growing autonomous driving data. However, considering the complicated traffic environments and driving scenarios, deploying federated learning for autonomous vehicles is inevitably challenged by non-independent and identically distributed (Non-IID) data of vehicles, which may lead to failed convergence and low training accuracy. In this paper, we propose a novel hierarchically Federated Region-learning framework of Autonomous Vehicles (FedRAV), a two-stage framework, which adaptively divides a large area containing vehicles into sub-regions based on the defined region-wise distance, and achieves personalized vehicular models and regional models. This approach ensures that the personalized vehicular model adopts the beneficial models while discarding the unprofitable ones. We validate our FedRAV framework against existing federated learning algorithms on three real-world autonomous driving datasets in various heterogeneous settings. The experiment results demonstrate that our framework outperforms those known algorithms, and improves the accuracy by at least 3.69%. The source code of FedRAV is available at: https://github.com/yjzhai-cs/FedRAV.
Towards Efficient Scheduling of Federated Mobile Devices under Computational and Statistical Heterogeneity
May 25, 2020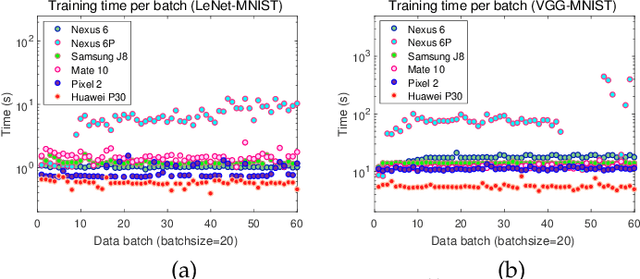
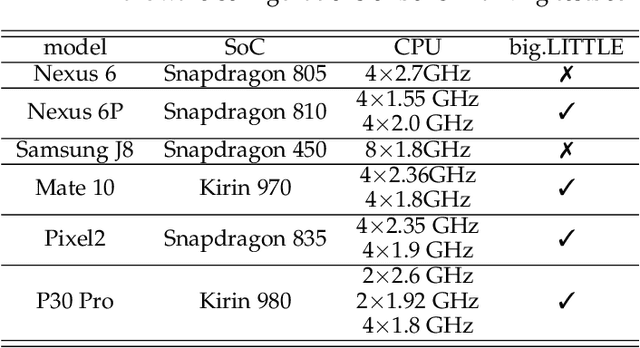


Originated from distributed learning, federated learning enables privacy-preserved collaboration on a new abstracted level by sharing the model parameters only. While the current research mainly focuses on optimizing learning algorithms and minimizing communication overhead left by distributed learning, there is still a considerable gap when it comes to the real implementation on mobile devices. In this paper, we start with an empirical experiment to demonstrate computation heterogeneity is a more pronounced bottleneck than communication on the current generation of battery-powered mobile devices, and the existing methods are haunted by mobile stragglers. Further, non-identically distributed data across the mobile users makes the selection of participants critical to the accuracy and convergence. To tackle the computational and statistical heterogeneity, we utilize data as a tunable knob and propose two efficient polynomial-time algorithms to schedule different workloads on various mobile devices, when data is identically or non-identically distributed. For identically distributed data, we combine partitioning and linear bottleneck assignment to achieve near-optimal training time without accuracy loss. For non-identically distributed data, we convert it into an average cost minimization problem and propose a greedy algorithm to find a reasonable balance between computation time and accuracy. We also establish an offline profiler to quantify the runtime behavior of different devices, which serves as the input to the scheduling algorithms. We conduct extensive experiments on a mobile testbed with two datasets and up to 20 devices. Compared with the common benchmarks, the proposed algorithms achieve 2-100x speedup epoch-wise, 2-7% accuracy gain and boost the convergence rate by more than 100% on CIFAR10.