 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan linguists better understand DNA?
Dec 10, 2024Multilingual transfer ability, which reflects how well models fine-tuned on one source language can be applied to other languages, has been well studied in multilingual pre-trained models. However, the existence of such capability transfer between natural language and gene sequences/languages remains underexplored.This study addresses this gap by drawing inspiration from the sentence-pair classification task used for evaluating sentence similarity in natural language. We constructed two analogous tasks: DNA-pair classification(DNA sequence similarity) and DNA-protein-pair classification(gene coding determination). These tasks were designed to validate the transferability of capabilities from natural language to gene sequences. Even a small-scale pre-trained model like GPT-2-small, which was pre-trained on English, achieved an accuracy of 78% on the DNA-pair classification task after being fine-tuned on English sentence-pair classification data(XTREME PAWS-X). While training a BERT model on multilingual text, the precision reached 82%.On the more complex DNA-protein-pair classification task, however, the model's output was barely distinguishable from random output.Experiments suggest that there may be a capability transfer from natural language to genetic language, but further task testing is needed to confirm this.
DNAHLM -- DNA sequence and Human Language mixed large language Model
Oct 22, 2024
There are already many DNA large language models, but most of them still follow traditional uses, such as extracting sequence features for classification tasks. More innovative applications of large language models, such as prompt engineering, RAG, and zero-shot or few-shot prediction, remain challenging for DNA-based models. The key issue lies in the fact that DNA models and human natural language models are entirely separate; however, techniques like prompt engineering require the use of natural language, thereby significantly limiting the application of DNA large language models. This paper introduces a hybrid model trained on the GPT-2 network, combining DNA sequences and English text to explore the potential of using prompts and fine-tuning in DNA models. The model has demonstrated its effectiveness in DNA related zero-shot prediction and multitask application.
Development of Minimal Biorobotic Stealth Distance and Its Application in the Design of Direct-Drive Dragonfly-Inspired Aircraft
Oct 21, 2024



This paper introduces the Minimal Biorobotic Stealth Distance (MBSD), a novel quantitative metric to evaluate the bionic resemblance of biorobotic aircraft. Current technological limitations prevent dragonfly-inspired aircrafts from achieving optimal performance at biological scales. To address these challenges, we use the DDD-1 dragonfly-inspired aircraft, a hover-capable direct-drive aircraft, to explore the impact of the MBSD on aircraft design. Key contributions of this research include: (1) the establishment of the MBSD as a quantifiable and operable evaluation metric that influences aircraft design, integrating seamlessly with the overall design process and providing a new dimension for optimizing bionic aircraft, balancing mechanical attributes and bionic characteristics; (2) the creation and analysis of a typical aircraft in four directions: essential characteristics of the MBSD, its coupling relationship with existing performance metrics (Longest Hover Duration and Maximum Instantaneous Forward Flight Speed), multi-objective optimization, and application in a typical mission scenario; (3) the construction and validation of a full-system model for the direct-drive dragonfly-inspired aircraft, demonstrating the design model's effectiveness against existing aircraft data. Detailed calculations of the MBSD consider appearance similarity, dynamic similarity, and environmental similarity.
A Plug-and-Play Fully On-the-Job Real-Time Reinforcement Learning Algorithm for a Direct-Drive Tandem-Wing Experiment Platforms Under Multiple Random Operating Conditions
Oct 21, 2024The nonlinear and unstable aerodynamic interference generated by the tandem wings of such biomimetic systems poses substantial challenges for motion control, especially under multiple random operating conditions. To address these challenges, the Concerto Reinforcement Learning Extension (CRL2E) algorithm has been developed. This plug-and-play, fully on-the-job, real-time reinforcement learning algorithm incorporates a novel Physics-Inspired Rule-Based Policy Composer Strategy with a Perturbation Module alongside a lightweight network optimized for real-time control. To validate the performance and the rationality of the module design, experiments were conducted under six challenging operating conditions, comparing seven different algorithms. The results demonstrate that the CRL2E algorithm achieves safe and stable training within the first 500 steps, improving tracking accuracy by 14 to 66 times compared to the Soft Actor-Critic, Proximal Policy Optimization, and Twin Delayed Deep Deterministic Policy Gradient algorithms. Additionally, CRL2E significantly enhances performance under various random operating conditions, with improvements in tracking accuracy ranging from 8.3% to 60.4% compared to the Concerto Reinforcement Learning (CRL) algorithm. The convergence speed of CRL2E is 36.11% to 57.64% faster than the CRL algorithm with only the Composer Perturbation and 43.52% to 65.85% faster than the CRL algorithm when both the Composer Perturbation and Time-Interleaved Capability Perturbation are introduced, especially in conditions where the standard CRL struggles to converge. Hardware tests indicate that the optimized lightweight network structure excels in weight loading and average inference time, meeting real-time control requirements.
Occlusion-Aware 3D Motion Interpretation for Abnormal Behavior Detection
Jul 23, 2024Estimating abnormal posture based on 3D pose is vital in human pose analysis, yet it presents challenges, especially when reconstructing 3D human poses from monocular datasets with occlusions. Accurate reconstructions enable the restoration of 3D movements, which assist in the extraction of semantic details necessary for analyzing abnormal behaviors. However, most existing methods depend on predefined key points as a basis for estimating the coordinates of occluded joints, where variations in data quality have adversely affected the performance of these models. In this paper, we present OAD2D, which discriminates against motion abnormalities based on reconstructing 3D coordinates of mesh vertices and human joints from monocular videos. The OAD2D employs optical flow to capture motion prior information in video streams, enriching the information on occluded human movements and ensuring temporal-spatial alignment of poses. Moreover, we reformulate the abnormal posture estimation by coupling it with Motion to Text (M2T) model in which, the VQVAE is employed to quantize motion features. This approach maps motion tokens to text tokens, allowing for a semantically interpretable analysis of motion, and enhancing the generalization of abnormal posture detection boosted by Language model. Our approach demonstrates the robustness of abnormal behavior detection against severe and self-occlusions, as it reconstructs human motion trajectories in global coordinates to effectively mitigate occlusion issues. Our method, validated using the Human3.6M, 3DPW, and NTU RGB+D datasets, achieves a high $F_1-$Score of 0.94 on the NTU RGB+D dataset for medical condition detection. And we will release all of our code and data.
A Graph Total Variation Regularized Softmax for Text Generation
Jan 01, 2021


The softmax operator is one of the most important functions in machine learning models. When applying neural networks to multi-category classification, the correlations among different categories are often ignored. For example, in text generation, a language model makes a choice of each new word based only on the former selection of its context. In this scenario, the link statistics information of concurrent words based on a corpus (an analogy of the natural way of expression) is also valuable in choosing the next word, which can help to improve the sentence's fluency and smoothness. To fully explore such important information, we propose a graph softmax function for text generation. It is expected that the final classification result would be dominated by both the language model and graphical text relationships among words. We use a graph total variation term to regularize softmax so as to incorporate the concurrent relationship into the language model. The total variation of the generated words should be small locally. We apply the proposed graph softmax to GPT2 for the text generation task. Experimental results demonstrate that the proposed graph softmax achieves better BLEU and perplexity than softmax. Human testers can also easily distinguish the text generated by the graph softmax or softmax.
Segmenting DNA sequence into `words'
Jun 22, 2013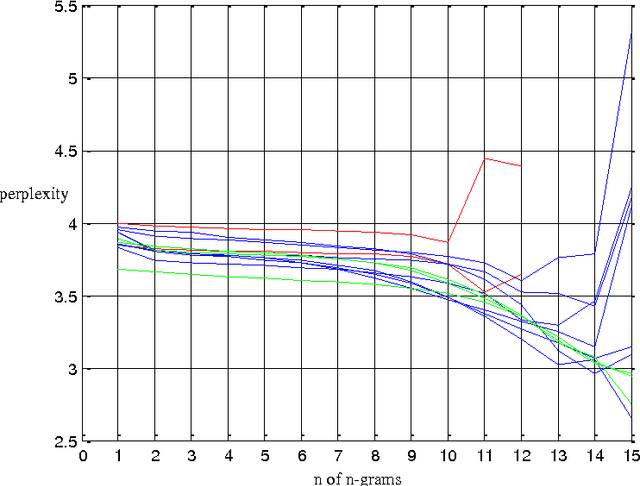

This paper presents a novel method to segment/decode DNA sequences based on n-grams statistical language model. Firstly, we find the length of most DNA 'words' is 12 to 15 bps by analyzing the genomes of 12 model species. Then we design an unsupervised probability based approach to segment the DNA sequences. The benchmark of segmenting method is also proposed.