Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenting DNA sequence into `words'
Paper and Code
Jun 22, 2013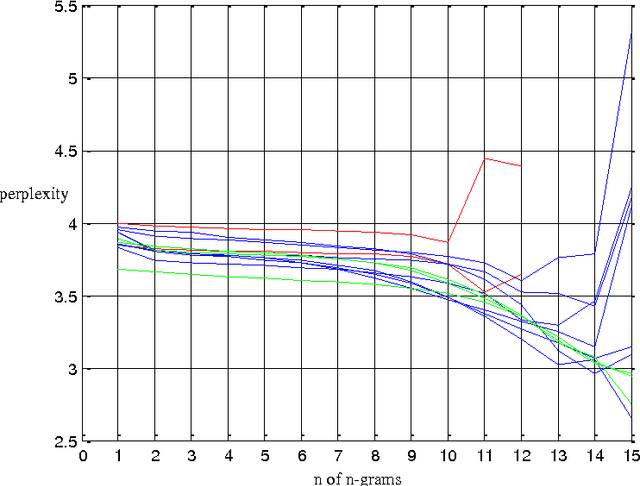

This paper presents a novel method to segment/decode DNA sequences based on n-grams statistical language model. Firstly, we find the length of most DNA 'words' is 12 to 15 bps by analyzing the genomes of 12 model species. Then we design an unsupervised probability based approach to segment the DNA sequences. The benchmark of segmenting method is also proposed.
* 12 pages,2 figures
View paper on