 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Data Utilization for Multilingual Dense Retrieval
Sep 11, 2025Multilingual dense retrieval aims to retrieve relevant documents across different languages based on a unified retriever model. The challenge lies in aligning representations of different languages in a shared vector space. The common practice is to fine-tune the dense retriever via contrastive learning, whose effectiveness highly relies on the quality of the negative sample and the efficacy of mini-batch data. Different from the existing studies that focus on developing sophisticated model architecture, we propose a method to boost data utilization for multilingual dense retrieval by obtaining high-quality hard negative samples and effective mini-batch data. The extensive experimental results on a multilingual retrieval benchmark, MIRACL, with 16 languages demonstrate the effectiveness of our method by outperforming several existing strong baselines.
Multilingual Collaborative Defense for Large Language Models
May 17, 2025The robustness and security of large language models (LLMs) has become a prominent research area. One notable vulnerability is the ability to bypass LLM safeguards by translating harmful queries into rare or underrepresented languages, a simple yet effective method of "jailbreaking" these models. Despite the growing concern, there has been limited research addressing the safeguarding of LLMs in multilingual scenarios, highlighting an urgent need to enhance multilingual safety. In this work, we investigate the correlation between various attack features across different languages and propose Multilingual Collaborative Defense (MCD), a novel learning method that optimizes a continuous, soft safety prompt automatically to facilitate multilingual safeguarding of LLMs. The MCD approach offers three advantages: First, it effectively improves safeguarding performance across multiple languages. Second, MCD maintains strong generalization capabilities while minimizing false refusal rates. Third, MCD mitigates the language safety misalignment caused by imbalances in LLM training corpora. To evaluate the effectiveness of MCD, we manually construct multilingual versions of commonly used jailbreak benchmarks, such as MaliciousInstruct and AdvBench, to assess various safeguarding methods. Additionally, we introduce these datasets in underrepresented (zero-shot) languages to verify the language transferability of MCD. The results demonstrate that MCD outperforms existing approaches in safeguarding against multilingual jailbreak attempts while also exhibiting strong language transfer capabilities. Our code is available at https://github.com/HLiang-Lee/MCD.
Touch100k: A Large-Scale Touch-Language-Vision Dataset for Touch-Centric Multimodal Representation
Jun 06, 2024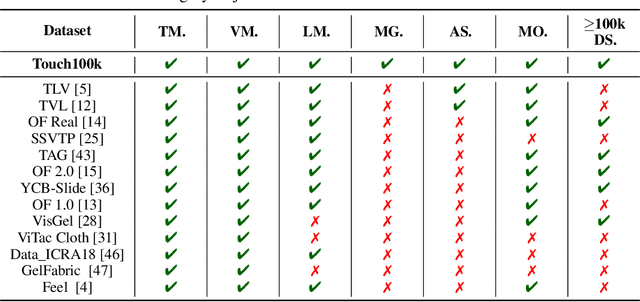
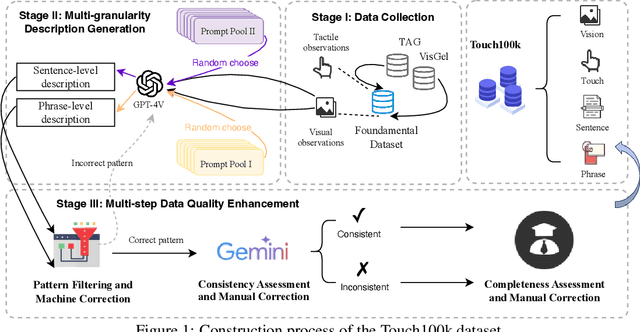
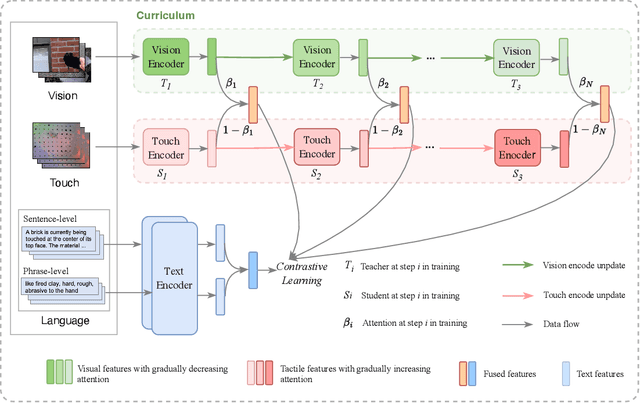
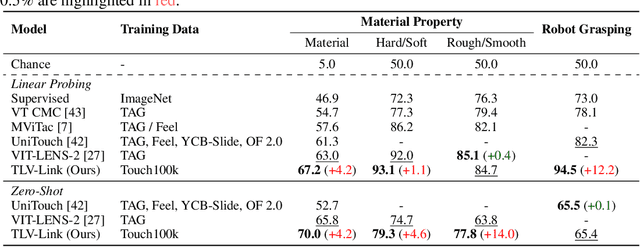
Touch holds a pivotal position in enhancing the perceptual and interactive capabilities of both humans and robots. Despite its significance, current tactile research mainly focuses on visual and tactile modalities, overlooking the language domain. Inspired by this, we construct Touch100k, a paired touch-language-vision dataset at the scale of 100k, featuring tactile sensation descriptions in multiple granularities (i.e., sentence-level natural expressions with rich semantics, including contextual and dynamic relationships, and phrase-level descriptions capturing the key features of tactile sensations). Based on the dataset, we propose a pre-training method, Touch-Language-Vision Representation Learning through Curriculum Linking (TLV-Link, for short), inspired by the concept of curriculum learning. TLV-Link aims to learn a tactile representation for the GelSight sensor and capture the relationship between tactile, language, and visual modalities. We evaluate our representation's performance across two task categories (namely, material property identification and robot grasping prediction), focusing on tactile representation and zero-shot touch understanding. The experimental evaluation showcases the effectiveness of our representation. By enabling TLV-Link to achieve substantial improvements and establish a new state-of-the-art in touch-centric multimodal representation learning, Touch100k demonstrates its value as a valuable resource for research. Project page: https://cocacola-lab.github.io/Touch100k/.
DoRA: Enhancing Parameter-Efficient Fine-Tuning with Dynamic Rank Distribution
May 28, 2024



Fine-tuning large-scale pre-trained models is inherently a resource-intensive task. While it can enhance the capabilities of the model, it also incurs substantial computational costs, posing challenges to the practical application of downstream tasks. Existing parameter-efficient fine-tuning (PEFT) methods such as Low-Rank Adaptation (LoRA) rely on a bypass framework that ignores the differential parameter budget requirements across weight matrices, which may lead to suboptimal fine-tuning outcomes. To address this issue, we introduce the Dynamic Low-Rank Adaptation (DoRA) method. DoRA decomposes high-rank LoRA layers into structured single-rank components, allowing for dynamic pruning of parameter budget based on their importance to specific tasks during training, which makes the most of the limited parameter budget. Experimental results demonstrate that DoRA can achieve competitive performance compared with LoRA and full model fine-tuning, and outperform various strong baselines with the same storage parameter budget. Our code is available at https://github.com/MIkumikumi0116/DoRA