 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Efficient RAG for Entity Matching with LLMs: A Blocking-based Exploration
Feb 05, 2026Retrieval-augmented generation (RAG) enhances LLM reasoning in knowledge-intensive tasks, but existing RAG pipelines incur substantial retrieval and generation overhead when applied to large-scale entity matching. To address this limitation, we introduce CE-RAG4EM, a cost-efficient RAG architecture that reduces computation through blocking-based batch retrieval and generation. We also present a unified framework for analyzing and evaluating RAG systems for entity matching, focusing on blocking-aware optimizations and retrieval granularity. Extensive experiments suggest that CE-RAG4EM can achieve comparable or improved matching quality while substantially reducing end-to-end runtime relative to strong baselines. Our analysis further reveals that key configuration parameters introduce an inherent trade-off between performance and overhead, offering practical guidance for designing efficient and scalable RAG systems for entity matching and data integration.
Knowledge Graph-based Retrieval-Augmented Generation for Schema Matching
Jan 15, 2025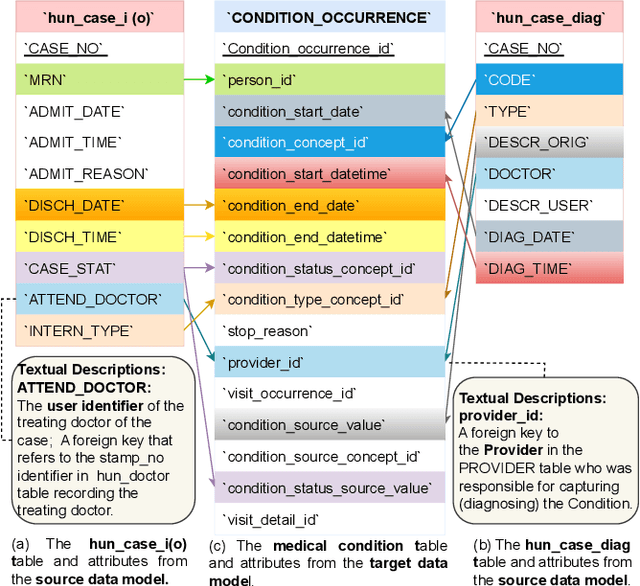
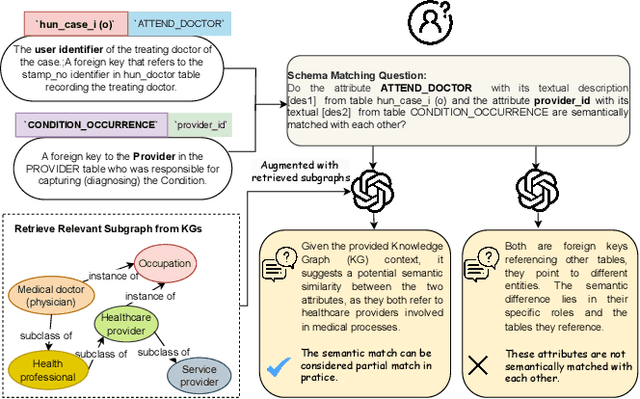
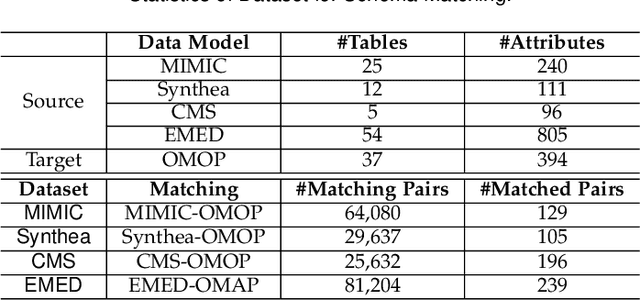
Traditional similarity-based schema matching methods are incapable of resolving semantic ambiguities and conflicts in domain-specific complex mapping scenarios due to missing commonsense and domain-specific knowledge. The hallucination problem of large language models (LLMs) also makes it challenging for LLM-based schema matching to address the above issues. Therefore, we propose a Knowledge Graph-based Retrieval-Augmented Generation model for Schema Matching, referred to as the KG-RAG4SM. In particular, KG-RAG4SM introduces novel vector-based, graph traversal-based, and query-based graph retrievals, as well as a hybrid approach and ranking schemes that identify the most relevant subgraphs from external large knowledge graphs (KGs). We showcase that KG-based retrieval-augmented LLMs are capable of generating more accurate results for complex matching cases without any re-training. Our experimental results show that KG-RAG4SM outperforms the LLM-based state-of-the-art (SOTA) methods (e.g., Jellyfish-8B) by 35.89% and 30.50% in terms of precision and F1 score on the MIMIC dataset, respectively; KG-RAG4SM with GPT-4o-mini outperforms the pre-trained language model (PLM)-based SOTA methods (e.g., SMAT) by 69.20% and 21.97% in terms of precision and F1 score on the Synthea dataset, respectively. The results also demonstrate that our approach is more efficient in end-to-end schema matching, and scales to retrieve from large KGs. Our case studies on the dataset from the real-world schema matching scenario exhibit that the hallucination problem of LLMs for schema matching is well mitigated by our solution.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020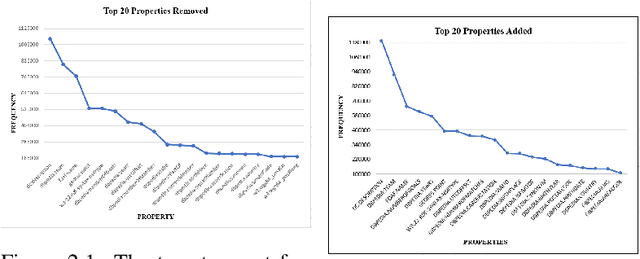
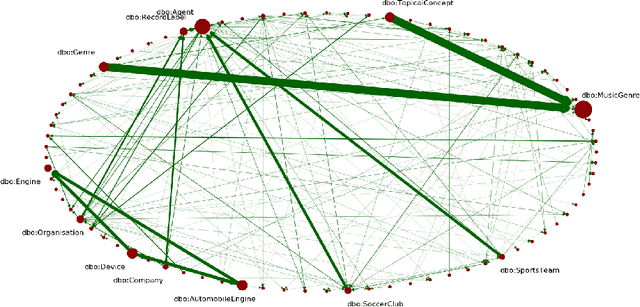

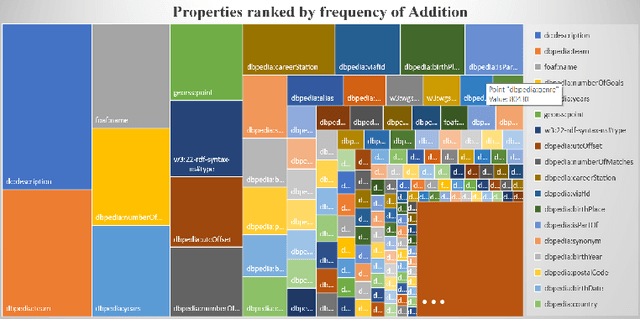
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.