 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Knowledge Distillation via Multi-branch Diversity Enhancement
Paper and Code
Oct 02, 2020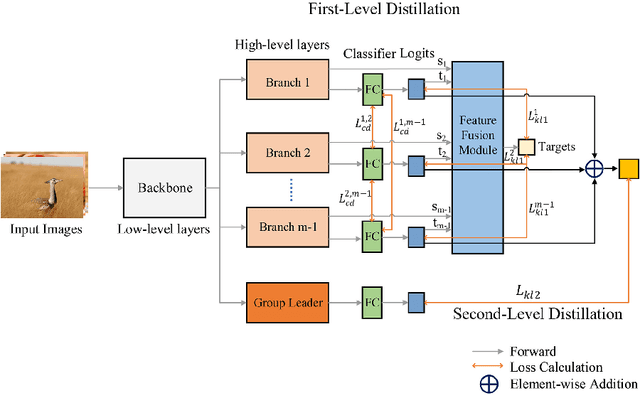
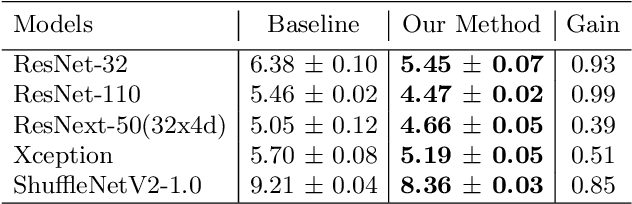
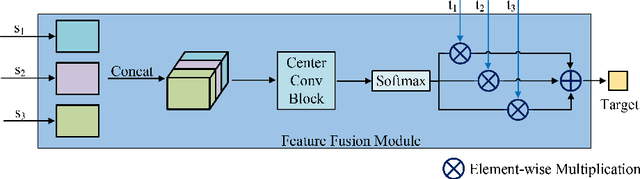
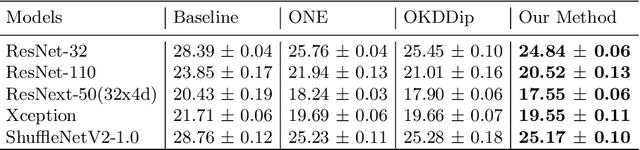
Knowledge distillation is an effective method to transfer the knowledge from the cumbersome teacher model to the lightweight student model. Online knowledge distillation uses the ensembled prediction results of multiple student models as soft targets to train each student model. However, the homogenization problem will lead to difficulty in further improving model performance. In this work, we propose a new distillation method to enhance the diversity among multiple student models. We introduce Feature Fusion Module (FFM), which improves the performance of the attention mechanism in the network by integrating rich semantic information contained in the last block of multiple student models. Furthermore, we use the Classifier Diversification(CD) loss function to strengthen the differences between the student models and deliver a better ensemble result. Extensive experiments proved that our method significantly enhances the diversity among student models and brings better distillation performance. We evaluate our method on three image classification datasets: CIFAR-10/100 and CINIC-10. The results show that our method achieves state-of-the-art performance on these datasets.