 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical considerations for variable screening in the Super Learner
Paper and Code
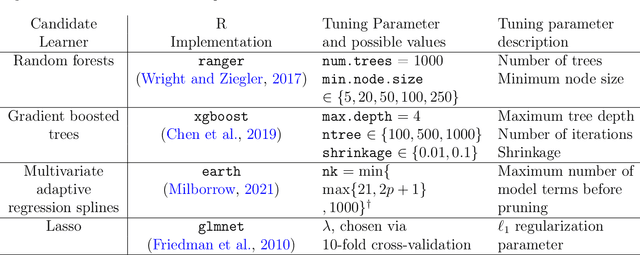
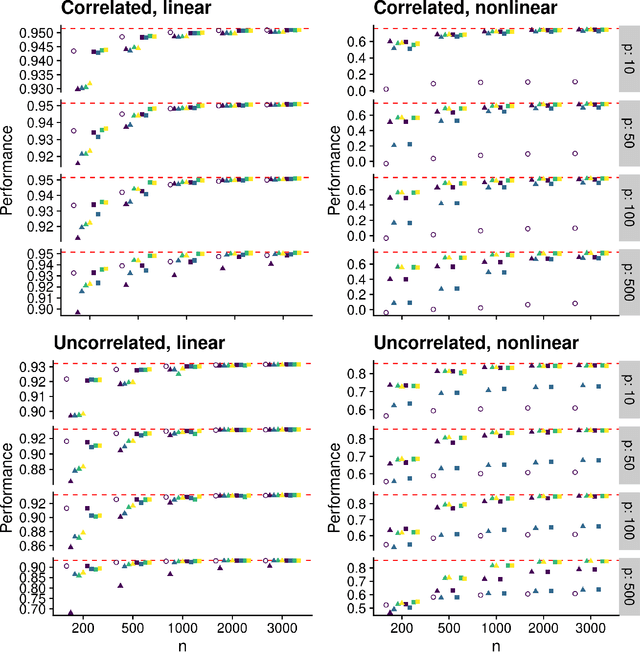
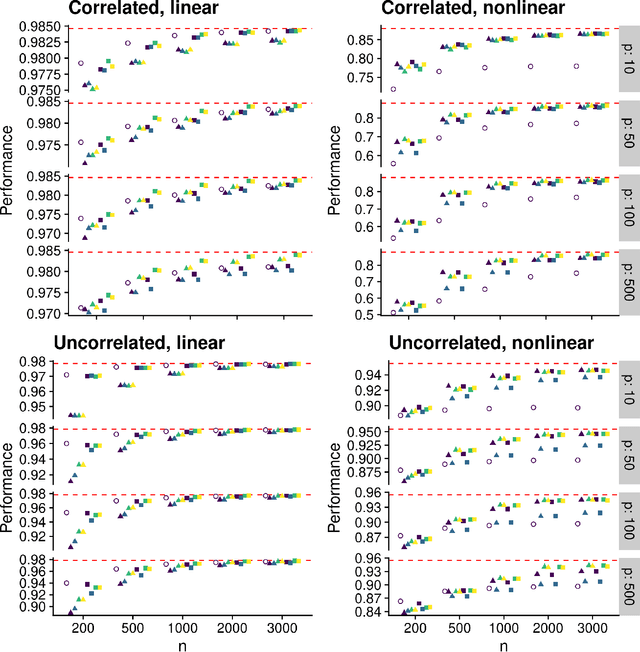
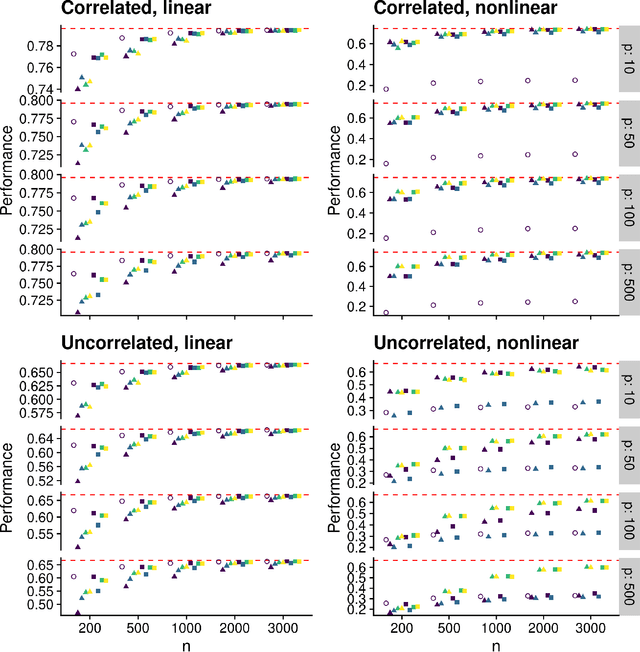
Estimating a prediction function is a fundamental component of many data analyses. The Super Learner ensemble, a particular implementation of stacking, has desirable theoretical properties and has been used successfully in many applications. Dimension reduction can be accomplished by using variable screening algorithms, including the lasso, within the ensemble prior to fitting other prediction algorithms. However, the performance of a Super Learner using the lasso for dimension reduction has not been fully explored in cases where the lasso is known to perform poorly. We provide empirical results that suggest that a diverse set of candidate screening algorithms should be used to protect against poor performance of any one screen, similar to the guidance for choosing a library of prediction algorithms for the Super Learner.