 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of weakly-supervised electronic health record-based phenotyping methods in rare-outcome settings
Apr 10, 2026Accurately identifying patients with specific medical conditions is a key challenge when using clinical data from electronic health records. Our objective was to comprehensively assess when weakly-supervised prediction methods, which use silver-standard labels (proxy measures of the true outcome) rather than gold-standard true labels, perform well in rare-outcome settings like vaccine safety studies. We compared three methods (PheNorm, MAP, and sureLDA) that combine structured features and features derived from clinical text using natural language processing, through an extensive simulation study with data-generating mechanisms ranging from simple to complex, varying outcome rates, and varying degrees of informative silver labels. We also considered using predicted probabilities to design a chart review validation study. No single method dominated the other across all prediction performance metrics. Probability-guided sampling selected a cohort enriched for patients with more mentions of important concepts in chart notes. SureLDA, the most complex of the three algorithms we considered, often performed well in simulations. Performance depended greatly on selected tuning parameters. Care should be taken when using weakly-supervised prediction methods in rare-outcome settings, particularly if the probabilities will be used in downstream analysis, but these methods can work well when silver labels are strong predictors of true outcomes.
Efficient Targeted Maximum Likelihood Estimators for Two-Phase Design Problems
Feb 27, 2026In a typical two-phase design, a random sample is drawn from the target population in phase 1, during which only a subset of variables is collected. In phase 2, a subsample of the phase-1 cohort is selected, and additional variables are measured. This setting induces a coarsened data structure on the data from the second phase. We assume coarsening at random, that is, the phase-2 sampling mechanism depends only on variables fully observed. We review existing estimators, including the generalized raking estimator and the inverse probability of censoring weighted targeted maximum likelihood estimation (IPCW-TMLE) along with its extensions that also target the phase-2 sampling mechanism to improve efficiency. We further introduce a new class of estimators constructed within the TMLE framework that are asymptotically equivalent.
Behavior of prediction performance metrics with rare events
Apr 22, 2025
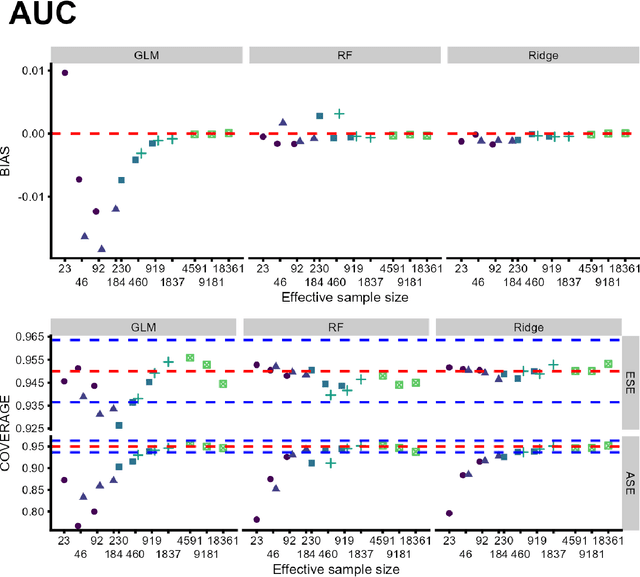
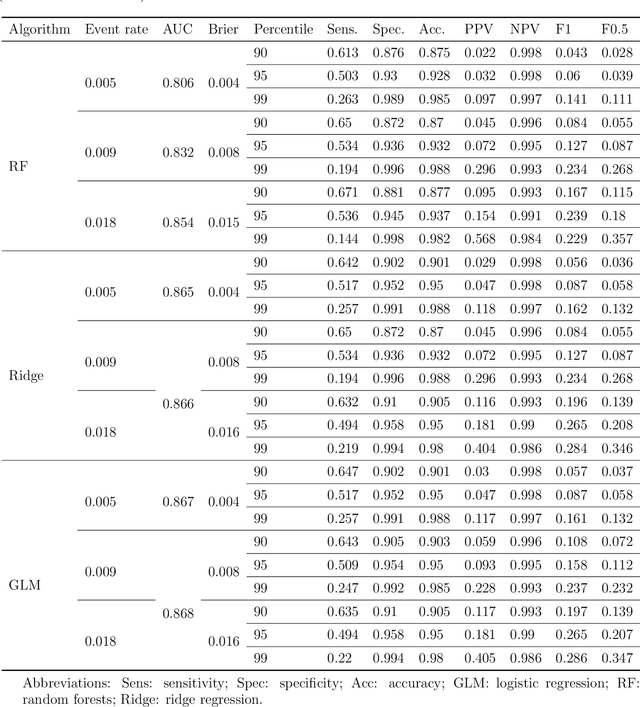
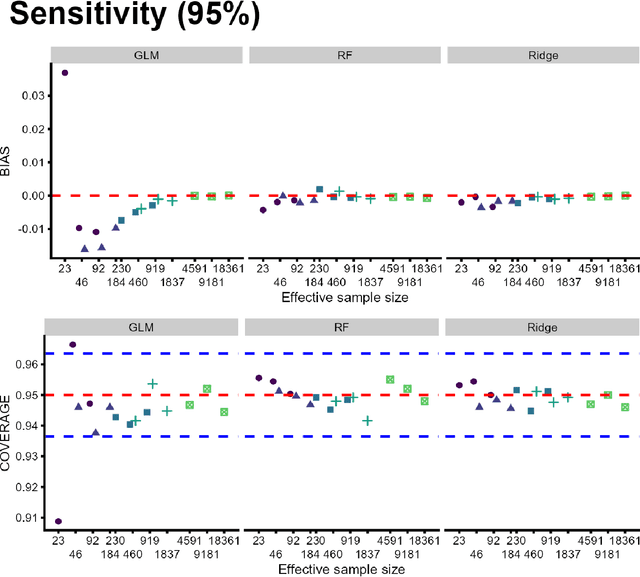
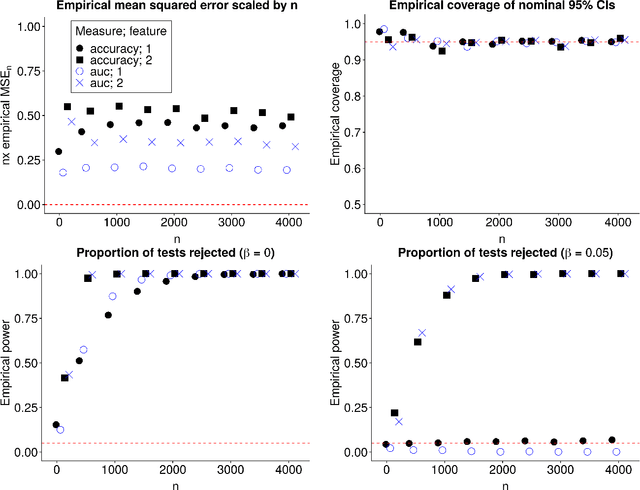
Area under the receiving operator characteristic curve (AUC) is commonly reported alongside binary prediction models. However, there are concerns that AUC might be a misleading measure of prediction performance in the rare event setting. This setting is common since many events of clinical importance are rare events. We conducted a simulation study to determine when or whether AUC is unstable in the rare event setting. Specifically, we aimed to determine whether the bias and variance of AUC are driven by the number of events or the event rate. We also investigated the behavior of other commonly used measures of prediction performance, including positive predictive value, accuracy, sensitivity, and specificity. Our results indicate that poor AUC behavior -- as measured by empirical bias, variability of cross-validated AUC estimates, and empirical coverage of confidence intervals -- is driven by the minimum class size, not event rate. Performance of sensitivity is driven by the number of events, while that of specificity is driven by the number of non-events. Other measures, including positive predictive value and accuracy, depend on the event rate even in large samples. AUC is reliable in the rare event setting provided that the total number of events is moderately large.
Practical considerations for variable screening in the Super Learner
Nov 06, 2023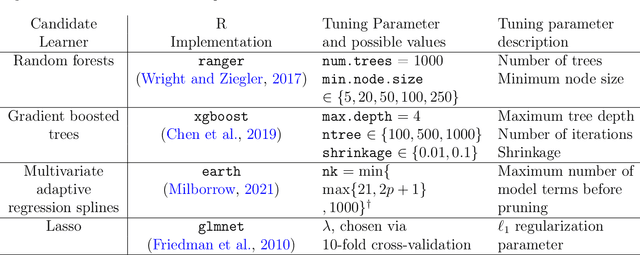
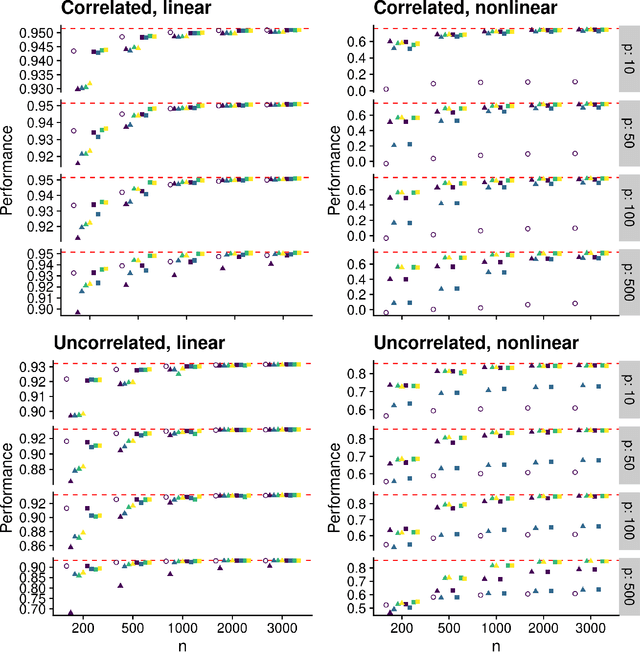
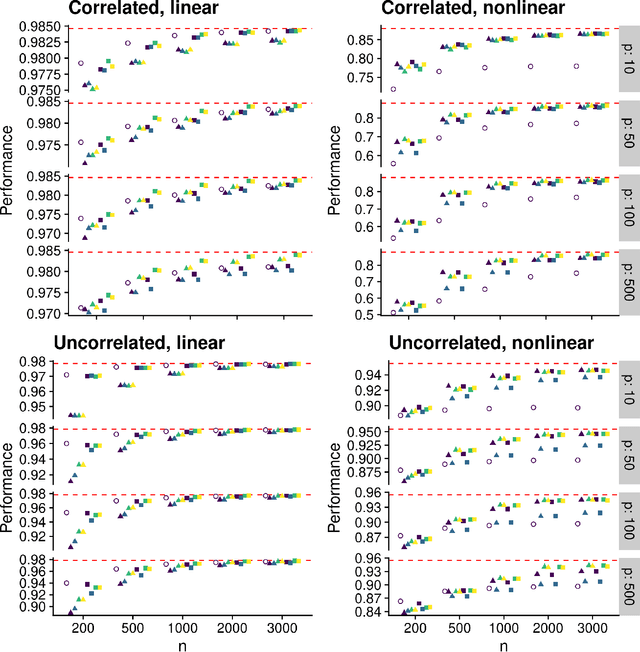
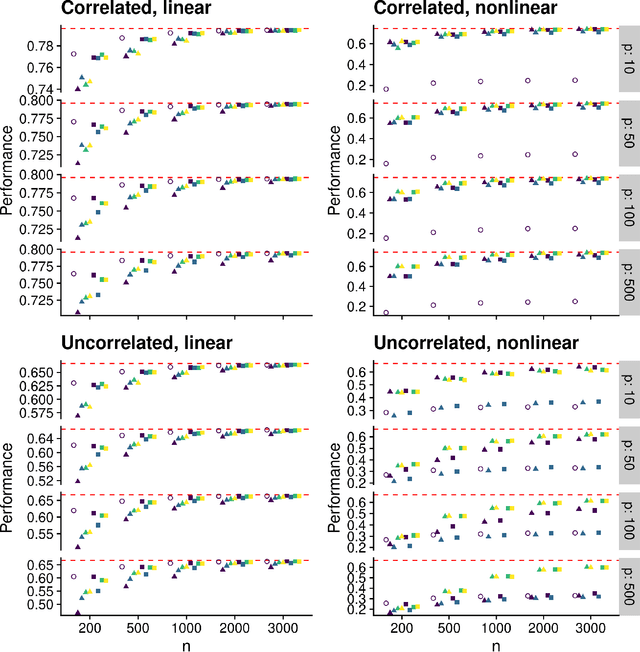
Estimating a prediction function is a fundamental component of many data analyses. The Super Learner ensemble, a particular implementation of stacking, has desirable theoretical properties and has been used successfully in many applications. Dimension reduction can be accomplished by using variable screening algorithms, including the lasso, within the ensemble prior to fitting other prediction algorithms. However, the performance of a Super Learner using the lasso for dimension reduction has not been fully explored in cases where the lasso is known to perform poorly. We provide empirical results that suggest that a diverse set of candidate screening algorithms should be used to protect against poor performance of any one screen, similar to the guidance for choosing a library of prediction algorithms for the Super Learner.
Efficient nonparametric statistical inference on population feature importance using Shapley values
Jun 16, 2020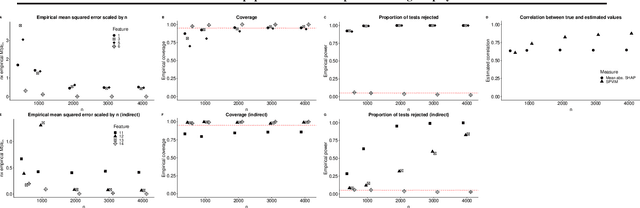
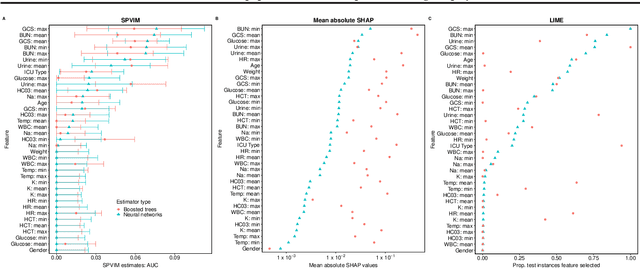
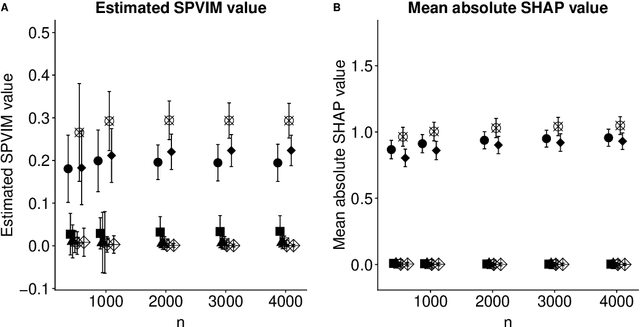
The true population-level importance of a variable in a prediction task provides useful knowledge about the underlying data-generating mechanism and can help in deciding which measurements to collect in subsequent experiments. Valid statistical inference on this importance is a key component in understanding the population of interest. We present a computationally efficient procedure for estimating and obtaining valid statistical inference on the Shapley Population Variable Importance Measure (SPVIM). Although the computational complexity of the true SPVIM scales exponentially with the number of variables, we propose an estimator based on randomly sampling only $\Theta(n)$ feature subsets given $n$ observations. We prove that our estimator converges at an asymptotically optimal rate. Moreover, by deriving the asymptotic distribution of our estimator, we construct valid confidence intervals and hypothesis tests. Our procedure has good finite-sample performance in simulations, and for an in-hospital mortality prediction task produces similar variable importance estimates when different machine learning algorithms are applied.
A unified approach for inference on algorithm-agnostic variable importance
Apr 07, 2020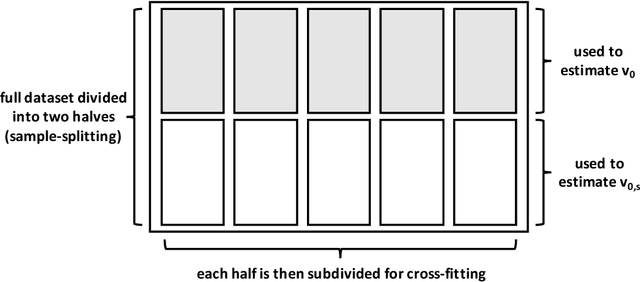


In many applications, it is of interest to assess the relative contribution of features (or subsets of features) toward the goal of predicting a response -- in other words, to gauge the variable importance of features. Most recent work on variable importance assessment has focused on describing the importance of features within the confines of a given prediction algorithm. However, such assessment does not necessarily characterize the prediction potential of features, and may provide a misleading reflection of the intrinsic value of these features. To address this limitation, we propose a general framework for nonparametric inference on interpretable algorithm-agnostic variable importance. We define variable importance as a population-level contrast between the oracle predictiveness of all available features versus all features except those under consideration. We propose a nonparametric efficient estimation procedure that allows the construction of valid confidence intervals, even when machine learning techniques are used. We also outline a valid strategy for testing the null importance hypothesis. Through simulations, we show that our proposal has good operating characteristics, and we illustrate its use with data from a study of an antibody against HIV-1 infection.